 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOmniVTON++: Training-Free Universal Virtual Try-On with Principal Pose Guidance
Feb 16, 2026Image-based Virtual Try-On (VTON) concerns the synthesis of realistic person imagery through garment re-rendering under human pose and body constraints. In practice, however, existing approaches are typically optimized for specific data conditions, making their deployment reliant on retraining and limiting their generalization as a unified solution. We present OmniVTON++, a training-free VTON framework designed for universal applicability. It addresses the intertwined challenges of garment alignment, human structural coherence, and boundary continuity by coordinating Structured Garment Morphing for correspondence-driven garment adaptation, Principal Pose Guidance for step-wise structural regulation during diffusion sampling, and Continuous Boundary Stitching for boundary-aware refinement, forming a cohesive pipeline without task-specific retraining. Experimental results demonstrate that OmniVTON++ achieves state-of-the-art performance across diverse generalization settings, including cross-dataset and cross-garment-type evaluations, while reliably operating across scenarios and diffusion backbones within a single formulation. In addition to single-garment, single-human cases, the framework supports multi-garment, multi-human, and anime character virtual try-on, expanding the scope of virtual try-on applications. The source code will be released to the public.
EAGLE-3: Scaling up Inference Acceleration of Large Language Models via Training-Time Test
Mar 03, 2025The sequential nature of modern LLMs makes them expensive and slow, and speculative sampling has proven to be an effective solution to this problem. Methods like EAGLE perform autoregression at the feature level, reusing top-layer features from the target model to achieve better results than vanilla speculative sampling. A growing trend in the LLM community is scaling up training data to improve model intelligence without increasing inference costs. However, we observe that scaling up data provides limited improvements for EAGLE. We identify that this limitation arises from EAGLE's feature prediction constraints. In this paper, we introduce EAGLE-3, which abandons feature prediction in favor of direct token prediction and replaces reliance on top-layer features with multi-layer feature fusion via a technique named training-time test. These improvements significantly enhance performance and enable the draft model to fully benefit from scaling up training data. Our experiments include both chat models and reasoning models, evaluated on five tasks. The results show that EAGLE-3 achieves a speedup ratio up to 6.5x, with about 1.4x improvement over EAGLE-2. The code is available at https://github.com/SafeAILab/EAGLE.
EAGLE-2: Faster Inference of Language Models with Dynamic Draft Trees
Jun 24, 2024Inference with modern Large Language Models (LLMs) is expensive and time-consuming, and speculative sampling has proven to be an effective solution. Most speculative sampling methods such as EAGLE use a static draft tree, implicitly assuming that the acceptance rate of draft tokens depends only on their position. Interestingly, we found that the acceptance rate of draft tokens is also context-dependent. In this paper, building upon EAGLE, we propose EAGLE-2, which introduces a new technique of context-aware dynamic draft tree into drafting modeling. This improvement leverages the fact that the draft model of EAGLE is well-calibrated: the confidence scores from the draft model approximate acceptance rates with small errors. We conducted extensive evaluations on three series of LLMs and six tasks, with EAGLE-2 achieving speedup ratios 3.05x-4.26x, which is 20%-40% faster than EAGLE-1. EAGLE-2 also ensures that the distribution of the generated text remains unchanged, making it a lossless acceleration algorithm.
EAGLE: Speculative Sampling Requires Rethinking Feature Uncertainty
Feb 04, 2024Autoregressive decoding makes the inference of Large Language Models (LLMs) time-consuming. In this paper, we reconsider speculative sampling and derive two key observations. Firstly, autoregression at the feature (second-to-top-layer) level is more straightforward than at the token level. Secondly, the inherent uncertainty in feature (second-to-top-layer) level autoregression constrains its performance. Based on these insights, we introduce EAGLE (Extrapolation Algorithm for Greater Language-model Efficiency), a simple yet highly efficient speculative sampling framework. By incorporating a token sequence advanced by one time step, EAGLE effectively resolves the uncertainty, enabling precise second-to-top-layer feature prediction with minimal overhead. We conducted comprehensive evaluations of EAGLE, including all models from the Vicuna and LLaMA2-Chat series, the MoE model Mixtral 8x7B Instruct, and tasks in dialogue, code generation, mathematical reasoning, and instruction following. For LLaMA2-Chat 70B, EAGLE achieved a latency speedup ratio of 2.7x-3.5x, doubled throughput, while maintaining the distribution of the generated text.
RAIN: Your Language Models Can Align Themselves without Finetuning
Sep 13, 2023Large language models (LLMs) often demonstrate inconsistencies with human preferences. Previous research gathered human preference data and then aligned the pre-trained models using reinforcement learning or instruction tuning, the so-called finetuning step. In contrast, aligning frozen LLMs without any extra data is more appealing. This work explores the potential of the latter setting. We discover that by integrating self-evaluation and rewind mechanisms, unaligned LLMs can directly produce responses consistent with human preferences via self-boosting. We introduce a novel inference method, Rewindable Auto-regressive INference (RAIN), that allows pre-trained LLMs to evaluate their own generation and use the evaluation results to guide backward rewind and forward generation for AI safety. Notably, RAIN operates without the need of extra data for model alignment and abstains from any training, gradient computation, or parameter updates; during the self-evaluation phase, the model receives guidance on which human preference to align with through a fixed-template prompt, eliminating the need to modify the initial prompt. Experimental results evaluated by GPT-4 and humans demonstrate the effectiveness of RAIN: on the HH dataset, RAIN improves the harmlessness rate of LLaMA 30B over vanilla inference from 82% to 97%, while maintaining the helpfulness rate. Under the leading adversarial attack llm-attacks on Vicuna 33B, RAIN establishes a new defense baseline by reducing the attack success rate from 94% to 19%.
CARMA: Context-Aware Runtime Reconfiguration for Energy-Efficient Sensor Fusion
Jun 27, 2023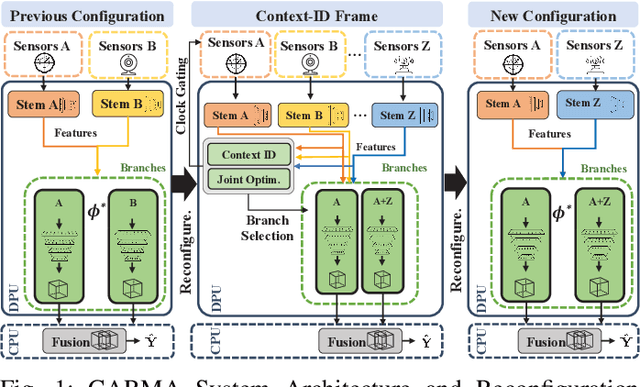
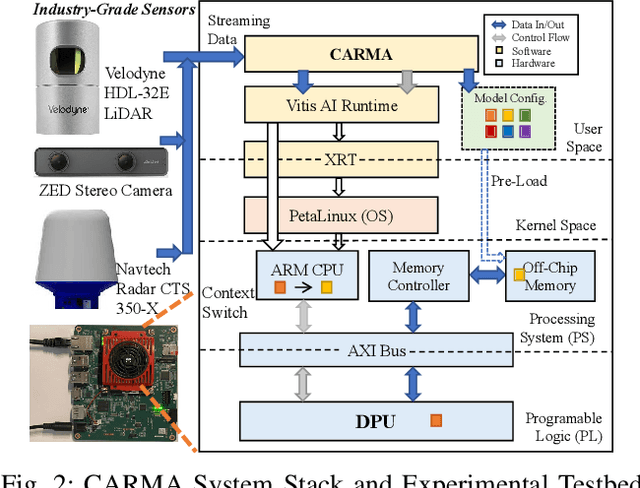
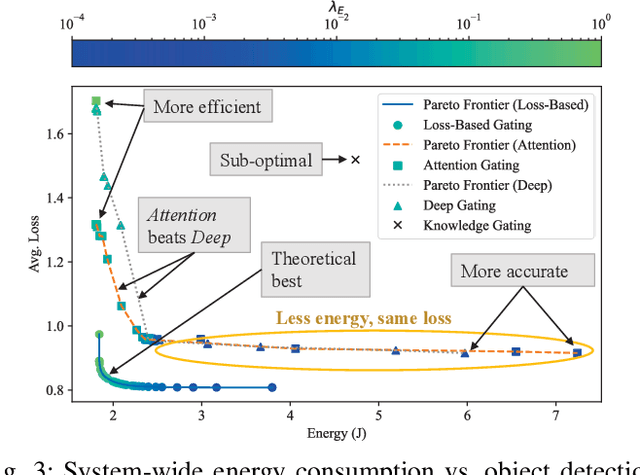
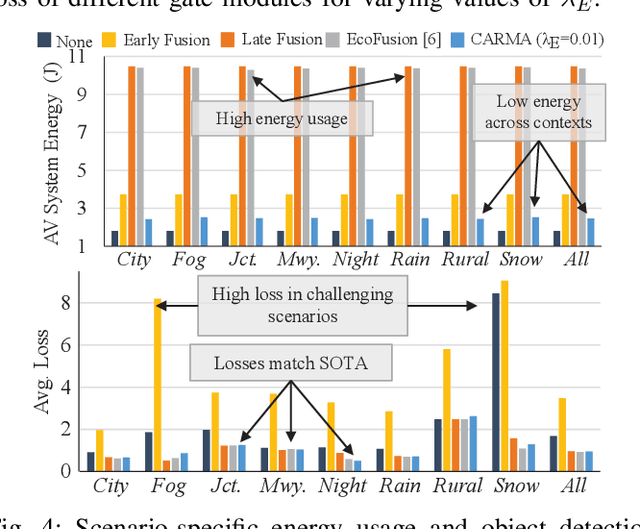
Autonomous systems (AS) are systems that can adapt and change their behavior in response to unanticipated events and include systems such as aerial drones, autonomous vehicles, and ground/aquatic robots. AS require a wide array of sensors, deep-learning models, and powerful hardware platforms to perceive and safely operate in real-time. However, in many contexts, some sensing modalities negatively impact perception while increasing the system's overall energy consumption. Since AS are often energy-constrained edge devices, energy-efficient sensor fusion methods have been proposed. However, existing methods either fail to adapt to changing scenario conditions or to optimize energy efficiency system-wide. We propose CARMA: a context-aware sensor fusion approach that uses context to dynamically reconfigure the computation flow on a Field-Programmable Gate Array (FPGA) at runtime. By clock-gating unused sensors and model sub-components, CARMA significantly reduces the energy used by a multi-sensory object detector without compromising performance. We use a Deep-learning Processor Unit (DPU) based reconfiguration approach to minimize the latency of model reconfiguration. We evaluate multiple context-identification strategies, propose a novel system-wide energy-performance joint optimization, and evaluate scenario-specific perception performance. Across challenging real-world sensing contexts, CARMA outperforms state-of-the-art methods with up to 1.3x speedup and 73% lower energy consumption.
Fusing Structural and Functional Connectivities using Disentangled VAE for Detecting MCI
Jun 16, 2023
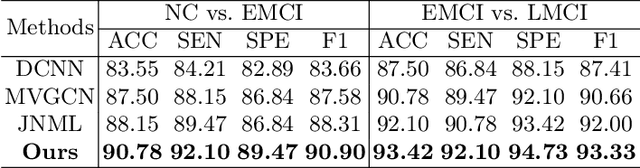
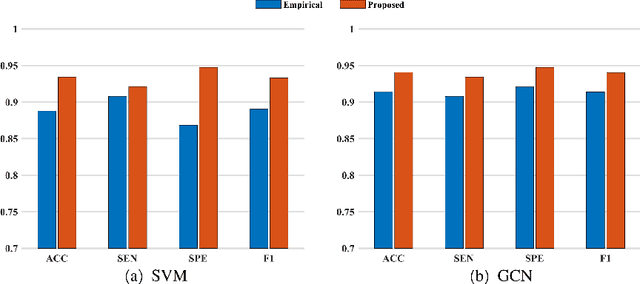
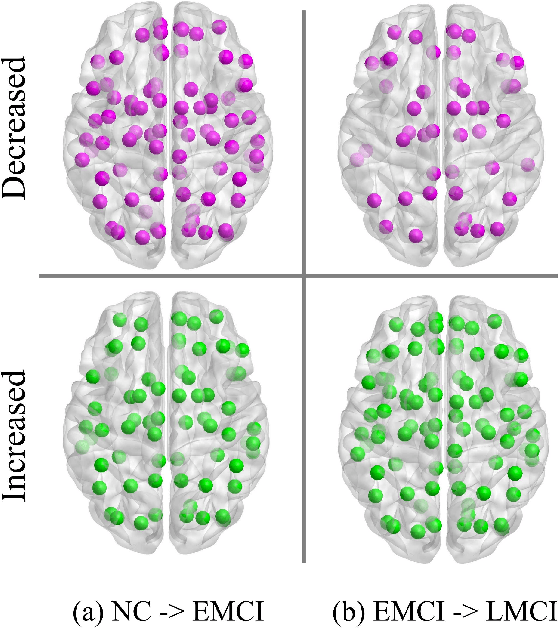
Brain network analysis is a useful approach to studying human brain disorders because it can distinguish patients from healthy people by detecting abnormal connections. Due to the complementary information from multiple modal neuroimages, multimodal fusion technology has a lot of potential for improving prediction performance. However, effective fusion of multimodal medical images to achieve complementarity is still a challenging problem. In this paper, a novel hierarchical structural-functional connectivity fusing (HSCF) model is proposed to construct brain structural-functional connectivity matrices and predict abnormal brain connections based on functional magnetic resonance imaging (fMRI) and diffusion tensor imaging (DTI). Specifically, the prior knowledge is incorporated into the separators for disentangling each modality of information by the graph convolutional networks (GCN). And a disentangled cosine distance loss is devised to ensure the disentanglement's effectiveness. Moreover, the hierarchical representation fusion module is designed to effectively maximize the combination of relevant and effective features between modalities, which makes the generated structural-functional connectivity more robust and discriminative in the cognitive disease analysis. Results from a wide range of tests performed on the public Alzheimer's Disease Neuroimaging Initiative (ADNI) database show that the proposed model performs better than competing approaches in terms of classification evaluation. In general, the proposed HSCF model is a promising model for generating brain structural-functional connectivities and identifying abnormal brain connections as cognitive disease progresses.
Direct-Effect Risk Minimization for Domain Generalization
Nov 26, 2022We study the problem of out-of-distribution (o.o.d.) generalization where spurious correlations of attributes vary across training and test domains. This is known as the problem of correlation shift and has posed concerns on the reliability of machine learning. In this work, we introduce the concepts of direct and indirect effects from causal inference to the domain generalization problem. We argue that models that learn direct effects minimize the worst-case risk across correlation-shifted domains. To eliminate the indirect effects, our algorithm consists of two stages: in the first stage, we learn an indirect-effect representation by minimizing the prediction error of domain labels using the representation and the class label; in the second stage, we remove the indirect effects learned in the first stage by matching each data with another data of similar indirect-effect representation but of different class label. We also propose a new model selection method by matching the validation set in the same way, which is shown to improve the generalization performance of existing models on correlation-shifted datasets. Experiments on 5 correlation-shifted datasets and the DomainBed benchmark verify the effectiveness of our approach.
An optical biomimetic eyes with interested object imaging
Aug 08, 2021
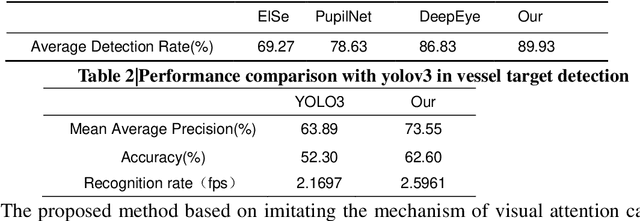
We presented an optical system to perform imaging interested objects in complex scenes, like the creature easy see the interested prey in the hunt for complex environments. It utilized Deep-learning network to learn the interested objects's vision features and designed the corresponding "imaging matrices", furthermore the learned matrixes act as the measurement matrix to complete compressive imaging with a single-pixel camera, finally we can using the compressed image data to only image the interested objects without the rest objects and backgrounds of the scenes with the previous Deep-learning network. Our results demonstrate that no matter interested object is single feature or rich details, the interference can be successfully filtered out and this idea can be applied in some common applications that effectively improve the performance. This bio-inspired optical system can act as the creature eye to achieve success on interested-based object imaging, object detection, object recognition and object tracking, etc.
AbdomenCT-1K: Is Abdominal Organ Segmentation A Solved Problem?
Oct 28, 2020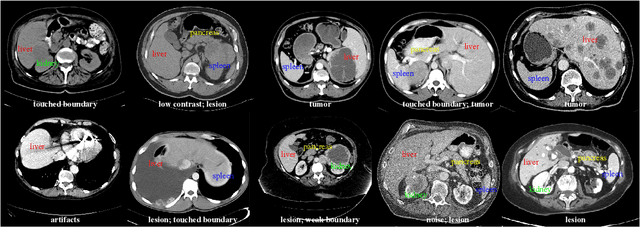
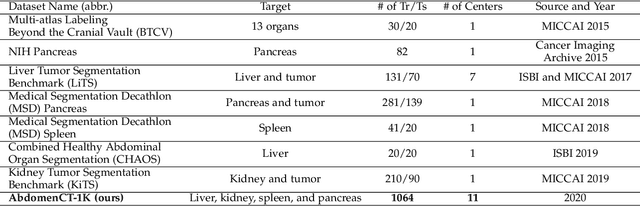
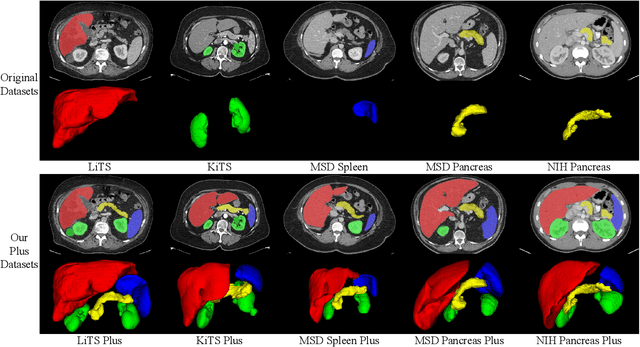
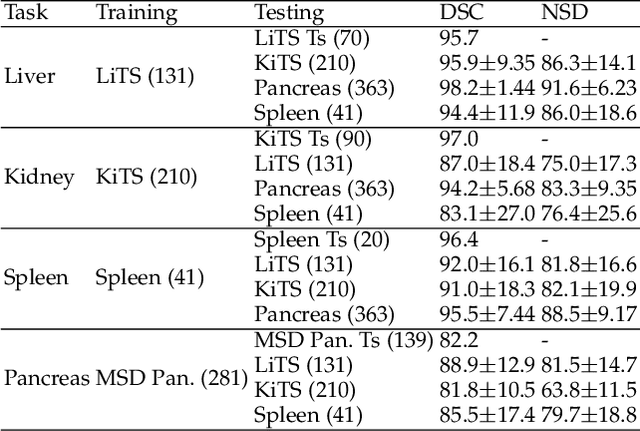
With the unprecedented developments in deep learning, automatic segmentation of main abdominal organs (i.e., liver, kidney, and spleen) seems to be a solved problem as the state-of-the-art (SOTA) methods have achieved comparable results with inter-observer variability on existing benchmark datasets. However, most of the existing abdominal organ segmentation benchmark datasets only contain single-center, single-phase, single-vendor, or single-disease cases, thus, it is unclear whether the excellent performance can generalize on more diverse datasets. In this paper, we present a large and diverse abdominal CT organ segmentation dataset, termed as AbdomenCT-1K, with more than 1000 (1K) CT scans from 11 countries, including multi-center, multi-phase, multi-vendor, and multi-disease cases. Furthermore, we conduct a large-scale study for liver, kidney, spleen, and pancreas segmentation, as well as reveal the unsolved segmentation problems of the SOTA method, such as the limited generalization ability on distinct medical centers, phases, and unseen diseases. To advance the unsolved problems, we build four organ segmentation benchmarks for fully supervised, semi-supervised, weakly supervised, and continual learning, which are currently challenging and active research topics. Accordingly, we develop a simple and effective method for each benchmark, which can be used as out-of-the-box methods and strong baselines. We believe the introduction of the AbdomenCT-1K dataset will promote future in-depth research towards clinical applicable abdominal organ segmentation methods. Moreover, the datasets, codes, and trained models of baseline methods will be publicly available at https://github.com/JunMa11/AbdomenCT-1K.