 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLens: Rethinking Training Efficiency for Foundational Text-to-Image Models
May 20, 2026We introduce Lens, a 3.8B-parameter T2I model that achieves performance competitive with, and in several cases surpassing, state-of-the-art models with more than 6B parameters across various benchmarks, while requiring significantly less training compute. For example, Lens requires only about 19.3% of the training compute used by Z-Image. The training efficiency of Lens stems from two key strategies beyond its compact model size. First, we maximize data information density per training batch by (i) training on Lens-800M, a dataset of 800M densely captioned image-text pairs whose captions are generated by GPT-4.1 and contain approximately 109 words on average, providing richer semantic supervision than conventional short captions, and (ii) constructing each batch from images with multiple resolutions and diverse aspect ratios, thereby enlarging the effective visual coverage of each optimization step. Second, we improve convergence speed through careful architectural choices, including adopting a semantic VAE that provides better latent representations and employing a strong language encoder that accelerates optimization while enabling multilingual generalization from English-only training data. After pre-training, we apply RL with taxonomy-driven prompts (Lens-RL-8K) and structured reward rubrics to suppress artifacts and improve visual quality, a reasoner module with training-free system prompt search to better align user requests with the model, and distillation-based acceleration for 4-step inference. Through efficient training and systematic optimization, Lens generalizes to arbitrary aspect ratios from 1:2 to 2:1 and resolutions up to 1440^2, and supports prompts in several commonly used languages. Thanks to its compact size, Lens generates a 1024^2 image in 3.15 seconds on a single NVIDIA H100 GPU, while its distilled turbo version performs 4-step generation in 0.84 seconds.
InsightTok: Improving Text and Face Fidelity in Discrete Tokenization for Autoregressive Image Generation
May 14, 2026Text and faces are among the most perceptually salient and practically important patterns in visual generation, yet they remain challenging for autoregressive generators built on discrete tokenization. A central bottleneck is the tokenizer: aggressive downsampling and quantization often discard the fine-grained structures needed to preserve readable glyphs and distinctive facial features. We attribute this gap to standard discrete-tokenizer objectives being weakly aligned with text legibility and facial fidelity, as these objectives typically optimize generic reconstruction while compressing diverse content uniformly. To address this, we propose InsightTok, a simple yet effective discrete visual tokenization framework that enhances text and face fidelity through localized, content-aware perceptual losses. With a compact 16k codebook and a 16x downsampling rate, InsightTok significantly outperforms prior tokenizers in text and face reconstruction without compromising general reconstruction quality. These gains consistently transfer to autoregressive image generation in InsightAR, producing images with clearer text and more faithful facial details. Overall, our results highlight the potential of specialized supervision in tokenizer training for advancing discrete image generation.
MobileManiBench: Simplifying Model Verification for Mobile Manipulation
Feb 05, 2026Vision-language-action models have advanced robotic manipulation but remain constrained by reliance on the large, teleoperation-collected datasets dominated by the static, tabletop scenes. We propose a simulation-first framework to verify VLA architectures before real-world deployment and introduce MobileManiBench, a large-scale benchmark for mobile-based robotic manipulation. Built on NVIDIA Isaac Sim and powered by reinforcement learning, our pipeline autonomously generates diverse manipulation trajectories with rich annotations (language instructions, multi-view RGB-depth-segmentation images, synchronized object/robot states and actions). MobileManiBench features 2 mobile platforms (parallel-gripper and dexterous-hand robots), 2 synchronized cameras (head and right wrist), 630 objects in 20 categories, 5 skills (open, close, pull, push, pick) with over 100 tasks performed in 100 realistic scenes, yielding 300K trajectories. This design enables controlled, scalable studies of robot embodiments, sensing modalities, and policy architectures, accelerating research on data efficiency and generalization. We benchmark representative VLA models and report insights into perception, reasoning, and control in complex simulated environments.
Animate Any Character in Any World
Dec 18, 2025Recent advances in world models have greatly enhanced interactive environment simulation. Existing methods mainly fall into two categories: (1) static world generation models, which construct 3D environments without active agents, and (2) controllable-entity models, which allow a single entity to perform limited actions in an otherwise uncontrollable environment. In this work, we introduce AniX, leveraging the realism and structural grounding of static world generation while extending controllable-entity models to support user-specified characters capable of performing open-ended actions. Users can provide a 3DGS scene and a character, then direct the character through natural language to perform diverse behaviors from basic locomotion to object-centric interactions while freely exploring the environment. AniX synthesizes temporally coherent video clips that preserve visual fidelity with the provided scene and character, formulated as a conditional autoregressive video generation problem. Built upon a pre-trained video generator, our training strategy significantly enhances motion dynamics while maintaining generalization across actions and characters. Our evaluation covers a broad range of aspects, including visual quality, character consistency, action controllability, and long-horizon coherence.
Spatia: Video Generation with Updatable Spatial Memory
Dec 17, 2025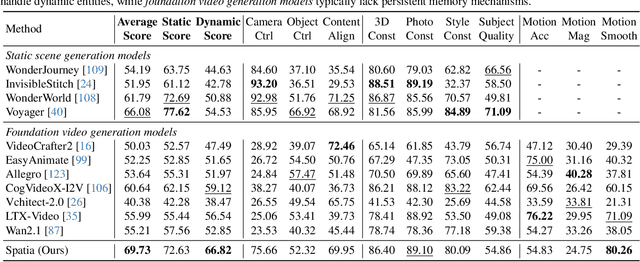
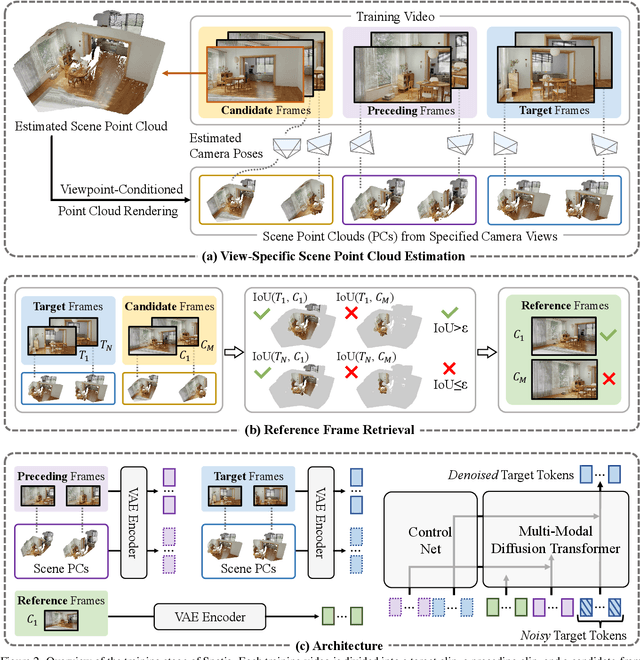

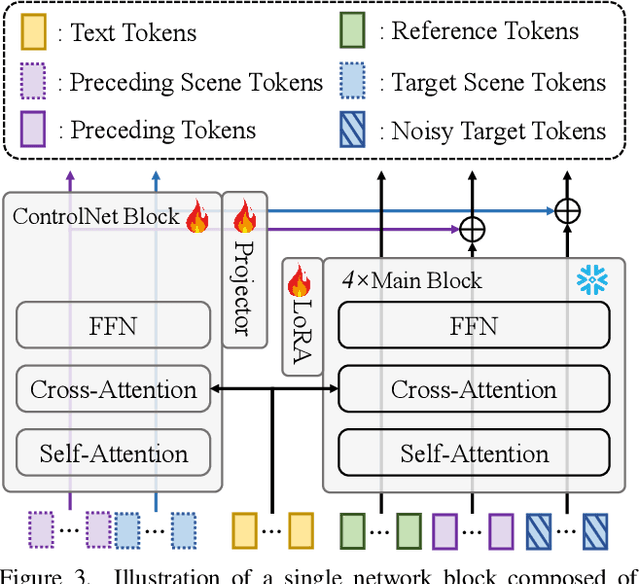
Existing video generation models struggle to maintain long-term spatial and temporal consistency due to the dense, high-dimensional nature of video signals. To overcome this limitation, we propose Spatia, a spatial memory-aware video generation framework that explicitly preserves a 3D scene point cloud as persistent spatial memory. Spatia iteratively generates video clips conditioned on this spatial memory and continuously updates it through visual SLAM. This dynamic-static disentanglement design enhances spatial consistency throughout the generation process while preserving the model's ability to produce realistic dynamic entities. Furthermore, Spatia enables applications such as explicit camera control and 3D-aware interactive editing, providing a geometrically grounded framework for scalable, memory-driven video generation.
From Virtual Games to Real-World Play
Jun 23, 2025



We introduce RealPlay, a neural network-based real-world game engine that enables interactive video generation from user control signals. Unlike prior works focused on game-style visuals, RealPlay aims to produce photorealistic, temporally consistent video sequences that resemble real-world footage. It operates in an interactive loop: users observe a generated scene, issue a control command, and receive a short video chunk in response. To enable such realistic and responsive generation, we address key challenges including iterative chunk-wise prediction for low-latency feedback, temporal consistency across iterations, and accurate control response. RealPlay is trained on a combination of labeled game data and unlabeled real-world videos, without requiring real-world action annotations. Notably, we observe two forms of generalization: (1) control transfer-RealPlay effectively maps control signals from virtual to real-world scenarios; and (2) entity transfer-although training labels originate solely from a car racing game, RealPlay generalizes to control diverse real-world entities, including bicycles and pedestrians, beyond vehicles. Project page can be found: https://wenqsun.github.io/RealPlay/
Fast Autoregressive Models for Continuous Latent Generation
Apr 24, 2025Autoregressive models have demonstrated remarkable success in sequential data generation, particularly in NLP, but their extension to continuous-domain image generation presents significant challenges. Recent work, the masked autoregressive model (MAR), bypasses quantization by modeling per-token distributions in continuous spaces using a diffusion head but suffers from slow inference due to the high computational cost of the iterative denoising process. To address this, we propose the Fast AutoRegressive model (FAR), a novel framework that replaces MAR's diffusion head with a lightweight shortcut head, enabling efficient few-step sampling while preserving autoregressive principles. Additionally, FAR seamlessly integrates with causal Transformers, extending them from discrete to continuous token generation without requiring architectural modifications. Experiments demonstrate that FAR achieves $2.3\times$ faster inference than MAR while maintaining competitive FID and IS scores. This work establishes the first efficient autoregressive paradigm for high-fidelity continuous-space image generation, bridging the critical gap between quality and scalability in visual autoregressive modeling.
EAGLE-3: Scaling up Inference Acceleration of Large Language Models via Training-Time Test
Mar 03, 2025The sequential nature of modern LLMs makes them expensive and slow, and speculative sampling has proven to be an effective solution to this problem. Methods like EAGLE perform autoregression at the feature level, reusing top-layer features from the target model to achieve better results than vanilla speculative sampling. A growing trend in the LLM community is scaling up training data to improve model intelligence without increasing inference costs. However, we observe that scaling up data provides limited improvements for EAGLE. We identify that this limitation arises from EAGLE's feature prediction constraints. In this paper, we introduce EAGLE-3, which abandons feature prediction in favor of direct token prediction and replaces reliance on top-layer features with multi-layer feature fusion via a technique named training-time test. These improvements significantly enhance performance and enable the draft model to fully benefit from scaling up training data. Our experiments include both chat models and reasoning models, evaluated on five tasks. The results show that EAGLE-3 achieves a speedup ratio up to 6.5x, with about 1.4x improvement over EAGLE-2. The code is available at https://github.com/SafeAILab/EAGLE.
Modelling Multi-modal Cross-interaction for ML-FSIC Based on Local Feature Selection
Dec 18, 2024
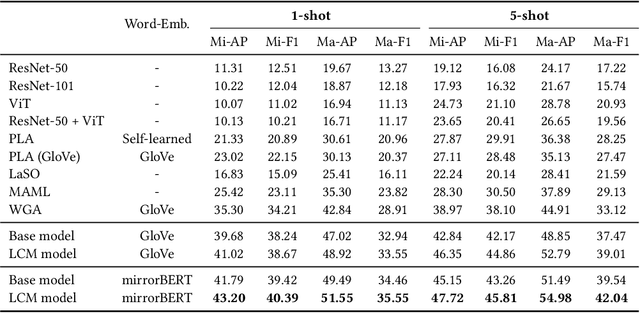

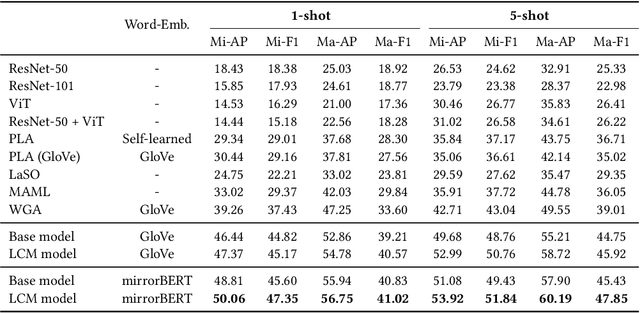
The aim of multi-label few-shot image classification (ML-FSIC) is to assign semantic labels to images, in settings where only a small number of training examples are available for each label. A key feature of the multi-label setting is that images often have several labels, which typically refer to objects appearing in different regions of the image. When estimating label prototypes, in a metric-based setting, it is thus important to determine which regions are relevant for which labels, but the limited amount of training data and the noisy nature of local features make this highly challenging. As a solution, we propose a strategy in which label prototypes are gradually refined. First, we initialize the prototypes using word embeddings, which allows us to leverage prior knowledge about the meaning of the labels. Second, taking advantage of these initial prototypes, we then use a Loss Change Measurement~(LCM) strategy to select the local features from the training images (i.e.\ the support set) that are most likely to be representative of a given label. Third, we construct the final prototype of the label by aggregating these representative local features using a multi-modal cross-interaction mechanism, which again relies on the initial word embedding-based prototypes. Experiments on COCO, PASCAL VOC, NUS-WIDE, and iMaterialist show that our model substantially improves the current state-of-the-art.
UniGraspTransformer: Simplified Policy Distillation for Scalable Dexterous Robotic Grasping
Dec 03, 2024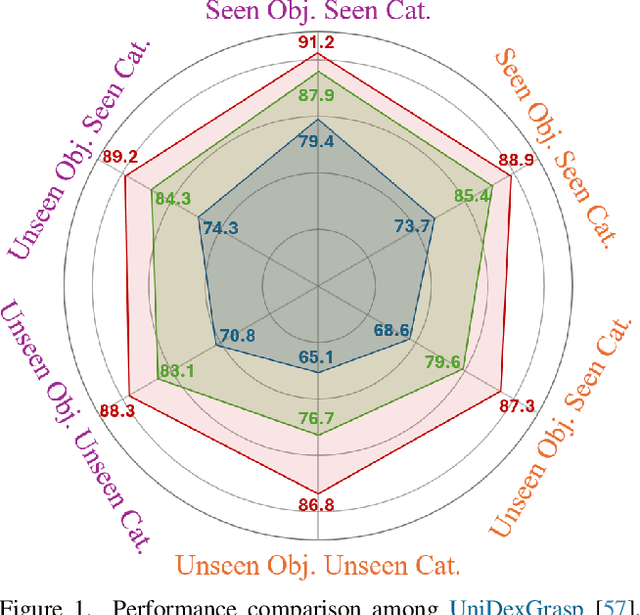

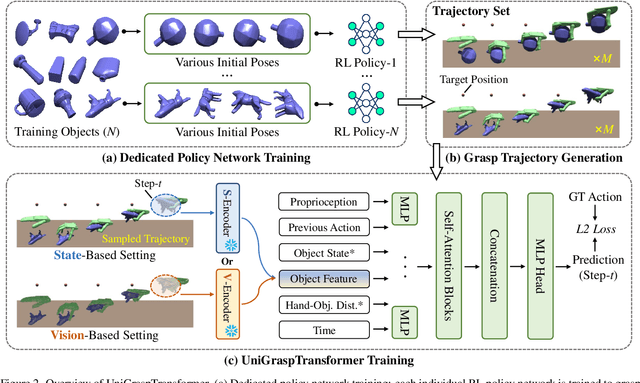

We introduce UniGraspTransformer, a universal Transformer-based network for dexterous robotic grasping that simplifies training while enhancing scalability and performance. Unlike prior methods such as UniDexGrasp++, which require complex, multi-step training pipelines, UniGraspTransformer follows a streamlined process: first, dedicated policy networks are trained for individual objects using reinforcement learning to generate successful grasp trajectories; then, these trajectories are distilled into a single, universal network. Our approach enables UniGraspTransformer to scale effectively, incorporating up to 12 self-attention blocks for handling thousands of objects with diverse poses. Additionally, it generalizes well to both idealized and real-world inputs, evaluated in state-based and vision-based settings. Notably, UniGraspTransformer generates a broader range of grasping poses for objects in various shapes and orientations, resulting in more diverse grasp strategies. Experimental results demonstrate significant improvements over state-of-the-art, UniDexGrasp++, across various object categories, achieving success rate gains of 3.5%, 7.7%, and 10.1% on seen objects, unseen objects within seen categories, and completely unseen objects, respectively, in the vision-based setting. Project page: https://dexhand.github.io/UniGraspTransformer.