 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLightBagel: A Light-weighted, Double Fusion Framework for Unified Multimodal Understanding and Generation
Oct 27, 2025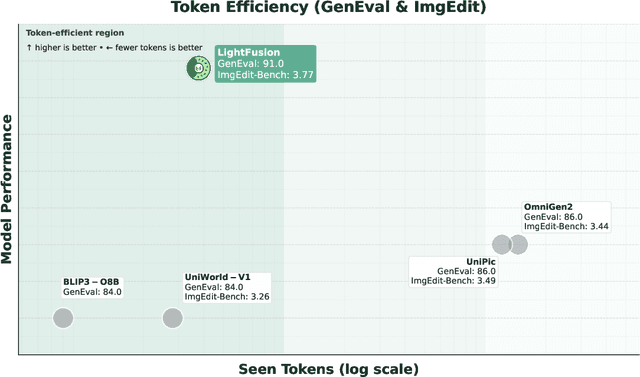
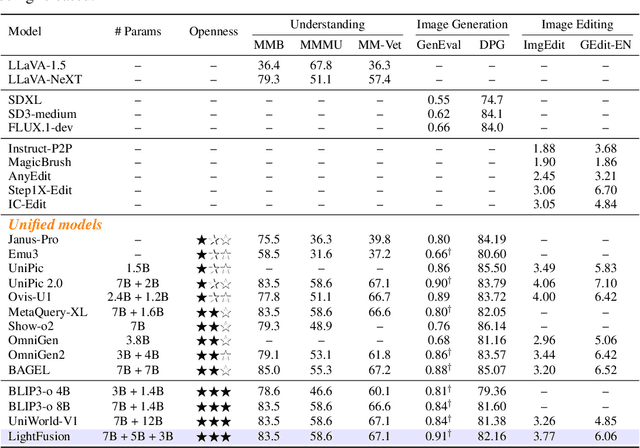
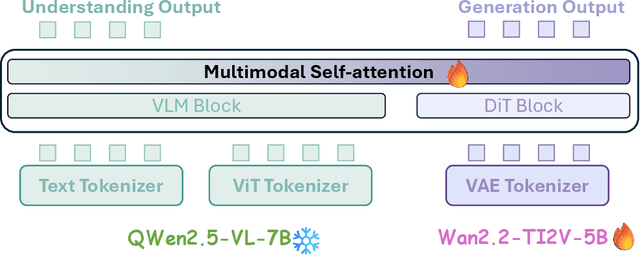
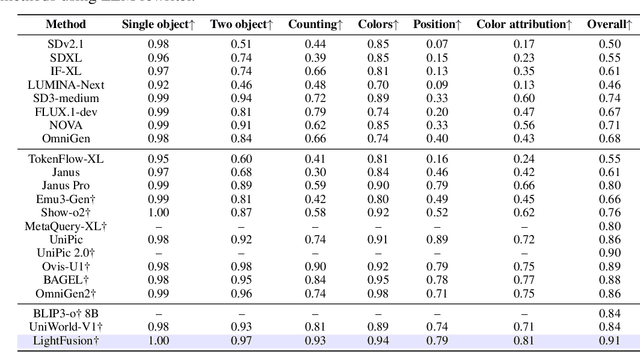
Unified multimodal models have recently shown remarkable gains in both capability and versatility, yet most leading systems are still trained from scratch and require substantial computational resources. In this paper, we show that competitive performance can be obtained far more efficiently by strategically fusing publicly available models specialized for either generation or understanding. Our key design is to retain the original blocks while additionally interleaving multimodal self-attention blocks throughout the networks. This double fusion mechanism (1) effectively enables rich multi-modal fusion while largely preserving the original strengths of the base models, and (2) catalyzes synergistic fusion of high-level semantic representations from the understanding encoder with low-level spatial signals from the generation encoder. By training with only ~ 35B tokens, this approach achieves strong results across multiple benchmarks: 0.91 on GenEval for compositional text-to-image generation, 82.16 on DPG-Bench for complex text-to-image generation, 6.06 on GEditBench, and 3.77 on ImgEdit-Bench for image editing. By fully releasing the entire suite of code, model weights, and datasets, we hope to support future research on unified multimodal modeling.
From Virtual Games to Real-World Play
Jun 23, 2025



We introduce RealPlay, a neural network-based real-world game engine that enables interactive video generation from user control signals. Unlike prior works focused on game-style visuals, RealPlay aims to produce photorealistic, temporally consistent video sequences that resemble real-world footage. It operates in an interactive loop: users observe a generated scene, issue a control command, and receive a short video chunk in response. To enable such realistic and responsive generation, we address key challenges including iterative chunk-wise prediction for low-latency feedback, temporal consistency across iterations, and accurate control response. RealPlay is trained on a combination of labeled game data and unlabeled real-world videos, without requiring real-world action annotations. Notably, we observe two forms of generalization: (1) control transfer-RealPlay effectively maps control signals from virtual to real-world scenarios; and (2) entity transfer-although training labels originate solely from a car racing game, RealPlay generalizes to control diverse real-world entities, including bicycles and pedestrians, beyond vehicles. Project page can be found: https://wenqsun.github.io/RealPlay/
Video4DGen: Enhancing Video and 4D Generation through Mutual Optimization
Apr 05, 2025The advancement of 4D (i.e., sequential 3D) generation opens up new possibilities for lifelike experiences in various applications, where users can explore dynamic objects or characters from any viewpoint. Meanwhile, video generative models are receiving particular attention given their ability to produce realistic and imaginative frames. These models are also observed to exhibit strong 3D consistency, indicating the potential to act as world simulators. In this work, we present Video4DGen, a novel framework that excels in generating 4D representations from single or multiple generated videos as well as generating 4D-guided videos. This framework is pivotal for creating high-fidelity virtual contents that maintain both spatial and temporal coherence. The 4D outputs generated by Video4DGen are represented using our proposed Dynamic Gaussian Surfels (DGS), which optimizes time-varying warping functions to transform Gaussian surfels (surface elements) from a static state to a dynamically warped state. We design warped-state geometric regularization and refinements on Gaussian surfels, to preserve the structural integrity and fine-grained appearance details. To perform 4D generation from multiple videos and capture representation across spatial, temporal, and pose dimensions, we design multi-video alignment, root pose optimization, and pose-guided frame sampling strategies. The leveraging of continuous warping fields also enables a precise depiction of pose, motion, and deformation over per-video frames. Further, to improve the overall fidelity from the observation of all camera poses, Video4DGen performs novel-view video generation guided by the 4D content, with the proposed confidence-filtered DGS to enhance the quality of generated sequences. With the ability of 4D and video generation, Video4DGen offers a powerful tool for applications in virtual reality, animation, and beyond.
MMTL-UniAD: A Unified Framework for Multimodal and Multi-Task Learning in Assistive Driving Perception
Apr 03, 2025Advanced driver assistance systems require a comprehensive understanding of the driver's mental/physical state and traffic context but existing works often neglect the potential benefits of joint learning between these tasks. This paper proposes MMTL-UniAD, a unified multi-modal multi-task learning framework that simultaneously recognizes driver behavior (e.g., looking around, talking), driver emotion (e.g., anxiety, happiness), vehicle behavior (e.g., parking, turning), and traffic context (e.g., traffic jam, traffic smooth). A key challenge is avoiding negative transfer between tasks, which can impair learning performance. To address this, we introduce two key components into the framework: one is the multi-axis region attention network to extract global context-sensitive features, and the other is the dual-branch multimodal embedding to learn multimodal embeddings from both task-shared and task-specific features. The former uses a multi-attention mechanism to extract task-relevant features, mitigating negative transfer caused by task-unrelated features. The latter employs a dual-branch structure to adaptively adjust task-shared and task-specific parameters, enhancing cross-task knowledge transfer while reducing task conflicts. We assess MMTL-UniAD on the AIDE dataset, using a series of ablation studies, and show that it outperforms state-of-the-art methods across all four tasks. The code is available on https://github.com/Wenzhuo-Liu/MMTL-UniAD.
NatureLM: Deciphering the Language of Nature for Scientific Discovery
Feb 11, 2025



Foundation models have revolutionized natural language processing and artificial intelligence, significantly enhancing how machines comprehend and generate human languages. Inspired by the success of these foundation models, researchers have developed foundation models for individual scientific domains, including small molecules, materials, proteins, DNA, and RNA. However, these models are typically trained in isolation, lacking the ability to integrate across different scientific domains. Recognizing that entities within these domains can all be represented as sequences, which together form the "language of nature", we introduce Nature Language Model (briefly, NatureLM), a sequence-based science foundation model designed for scientific discovery. Pre-trained with data from multiple scientific domains, NatureLM offers a unified, versatile model that enables various applications including: (i) generating and optimizing small molecules, proteins, RNA, and materials using text instructions; (ii) cross-domain generation/design, such as protein-to-molecule and protein-to-RNA generation; and (iii) achieving state-of-the-art performance in tasks like SMILES-to-IUPAC translation and retrosynthesis on USPTO-50k. NatureLM offers a promising generalist approach for various scientific tasks, including drug discovery (hit generation/optimization, ADMET optimization, synthesis), novel material design, and the development of therapeutic proteins or nucleotides. We have developed NatureLM models in different sizes (1 billion, 8 billion, and 46.7 billion parameters) and observed a clear improvement in performance as the model size increases.
DimensionX: Create Any 3D and 4D Scenes from a Single Image with Controllable Video Diffusion
Nov 07, 2024



In this paper, we introduce \textbf{DimensionX}, a framework designed to generate photorealistic 3D and 4D scenes from just a single image with video diffusion. Our approach begins with the insight that both the spatial structure of a 3D scene and the temporal evolution of a 4D scene can be effectively represented through sequences of video frames. While recent video diffusion models have shown remarkable success in producing vivid visuals, they face limitations in directly recovering 3D/4D scenes due to limited spatial and temporal controllability during generation. To overcome this, we propose ST-Director, which decouples spatial and temporal factors in video diffusion by learning dimension-aware LoRAs from dimension-variant data. This controllable video diffusion approach enables precise manipulation of spatial structure and temporal dynamics, allowing us to reconstruct both 3D and 4D representations from sequential frames with the combination of spatial and temporal dimensions. Additionally, to bridge the gap between generated videos and real-world scenes, we introduce a trajectory-aware mechanism for 3D generation and an identity-preserving denoising strategy for 4D generation. Extensive experiments on various real-world and synthetic datasets demonstrate that DimensionX achieves superior results in controllable video generation, as well as in 3D and 4D scene generation, compared with previous methods.
MeshAnything V2: Artist-Created Mesh Generation With Adjacent Mesh Tokenization
Aug 05, 2024

We introduce MeshAnything V2, an autoregressive transformer that generates Artist-Created Meshes (AM) aligned to given shapes. It can be integrated with various 3D asset production pipelines to achieve high-quality, highly controllable AM generation. MeshAnything V2 surpasses previous methods in both efficiency and performance using models of the same size. These improvements are due to our newly proposed mesh tokenization method: Adjacent Mesh Tokenization (AMT). Different from previous methods that represent each face with three vertices, AMT uses a single vertex whenever possible. Compared to previous methods, AMT requires about half the token sequence length to represent the same mesh in average. Furthermore, the token sequences from AMT are more compact and well-structured, fundamentally benefiting AM generation. Our extensive experiments show that AMT significantly improves the efficiency and performance of AM generation. Project Page: https://buaacyw.github.io/meshanything-v2/
Freeplane: Unlocking Free Lunch in Triplane-Based Sparse-View Reconstruction Models
Jun 02, 2024Creating 3D assets from single-view images is a complex task that demands a deep understanding of the world. Recently, feed-forward 3D generative models have made significant progress by training large reconstruction models on extensive 3D datasets, with triplanes being the preferred 3D geometry representation. However, effectively utilizing the geometric priors of triplanes, while minimizing artifacts caused by generated inconsistent multi-view images, remains a challenge. In this work, we present \textbf{Fre}quency modulat\textbf{e}d tri\textbf{plane} (\textbf{Freeplane}), a simple yet effective method to improve the generation quality of feed-forward models without additional training. We first analyze the role of triplanes in feed-forward methods and find that the inconsistent multi-view images introduce high-frequency artifacts on triplanes, leading to low-quality 3D meshes. Based on this observation, we propose strategically filtering triplane features and combining triplanes before and after filtering to produce high-quality textured meshes. These techniques incur no additional cost and can be seamlessly integrated into pre-trained feed-forward models to enhance their robustness against the inconsistency of generated multi-view images. Both qualitative and quantitative results demonstrate that our method improves the performance of feed-forward models by simply modulating triplanes. All you need is to modulate the triplanes during inference.
Vidu4D: Single Generated Video to High-Fidelity 4D Reconstruction with Dynamic Gaussian Surfels
May 27, 2024Video generative models are receiving particular attention given their ability to generate realistic and imaginative frames. Besides, these models are also observed to exhibit strong 3D consistency, significantly enhancing their potential to act as world simulators. In this work, we present Vidu4D, a novel reconstruction model that excels in accurately reconstructing 4D (i.e., sequential 3D) representations from single generated videos, addressing challenges associated with non-rigidity and frame distortion. This capability is pivotal for creating high-fidelity virtual contents that maintain both spatial and temporal coherence. At the core of Vidu4D is our proposed Dynamic Gaussian Surfels (DGS) technique. DGS optimizes time-varying warping functions to transform Gaussian surfels (surface elements) from a static state to a dynamically warped state. This transformation enables a precise depiction of motion and deformation over time. To preserve the structural integrity of surface-aligned Gaussian surfels, we design the warped-state geometric regularization based on continuous warping fields for estimating normals. Additionally, we learn refinements on rotation and scaling parameters of Gaussian surfels, which greatly alleviates texture flickering during the warping process and enhances the capture of fine-grained appearance details. Vidu4D also contains a novel initialization state that provides a proper start for the warping fields in DGS. Equipping Vidu4D with an existing video generative model, the overall framework demonstrates high-fidelity text-to-4D generation in both appearance and geometry.
Point Resampling and Ray Transformation Aid to Editable NeRF Models
May 12, 2024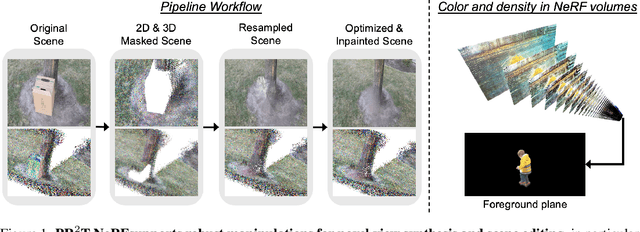

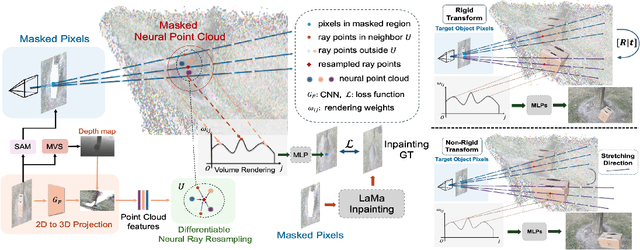

In NeRF-aided editing tasks, object movement presents difficulties in supervision generation due to the introduction of variability in object positions. Moreover, the removal operations of certain scene objects often lead to empty regions, presenting challenges for NeRF models in inpainting them effectively. We propose an implicit ray transformation strategy, allowing for direct manipulation of the 3D object's pose by operating on the neural-point in NeRF rays. To address the challenge of inpainting potential empty regions, we present a plug-and-play inpainting module, dubbed differentiable neural-point resampling (DNR), which interpolates those regions in 3D space at the original ray locations within the implicit space, thereby facilitating object removal & scene inpainting tasks. Importantly, employing DNR effectively narrows the gap between ground truth and predicted implicit features, potentially increasing the mutual information (MI) of the features across rays. Then, we leverage DNR and ray transformation to construct a point-based editable NeRF pipeline PR^2T-NeRF. Results primarily evaluated on 3D object removal & inpainting tasks indicate that our pipeline achieves state-of-the-art performance. In addition, our pipeline supports high-quality rendering visualization for diverse editing operations without necessitating extra supervision.