 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProtFAD: Introducing function-aware domains as implicit modality towards protein function perception
May 24, 2024



Protein function prediction is currently achieved by encoding its sequence or structure, where the sequence-to-function transcendence and high-quality structural data scarcity lead to obvious performance bottlenecks. Protein domains are "building blocks" of proteins that are functionally independent, and their combinations determine the diverse biological functions. However, most existing studies have yet to thoroughly explore the intricate functional information contained in the protein domains. To fill this gap, we propose a synergistic integration approach for a function-aware domain representation, and a domain-joint contrastive learning strategy to distinguish different protein functions while aligning the modalities. Specifically, we associate domains with the GO terms as function priors to pre-train domain embeddings. Furthermore, we partition proteins into multiple sub-views based on continuous joint domains for contrastive training under the supervision of a novel triplet InfoNCE loss. Our approach significantly and comprehensively outperforms the state-of-the-art methods on various benchmarks, and clearly differentiates proteins carrying distinct functions compared to the competitor.
Point Resampling and Ray Transformation Aid to Editable NeRF Models
May 12, 2024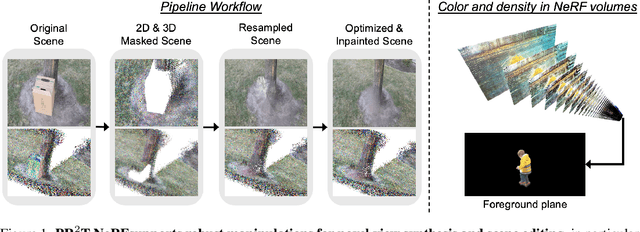

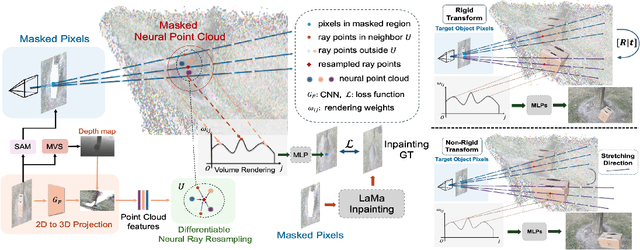

In NeRF-aided editing tasks, object movement presents difficulties in supervision generation due to the introduction of variability in object positions. Moreover, the removal operations of certain scene objects often lead to empty regions, presenting challenges for NeRF models in inpainting them effectively. We propose an implicit ray transformation strategy, allowing for direct manipulation of the 3D object's pose by operating on the neural-point in NeRF rays. To address the challenge of inpainting potential empty regions, we present a plug-and-play inpainting module, dubbed differentiable neural-point resampling (DNR), which interpolates those regions in 3D space at the original ray locations within the implicit space, thereby facilitating object removal & scene inpainting tasks. Importantly, employing DNR effectively narrows the gap between ground truth and predicted implicit features, potentially increasing the mutual information (MI) of the features across rays. Then, we leverage DNR and ray transformation to construct a point-based editable NeRF pipeline PR^2T-NeRF. Results primarily evaluated on 3D object removal & inpainting tasks indicate that our pipeline achieves state-of-the-art performance. In addition, our pipeline supports high-quality rendering visualization for diverse editing operations without necessitating extra supervision.
Intelligent model for offshore China sea fog forecasting
Jul 20, 2023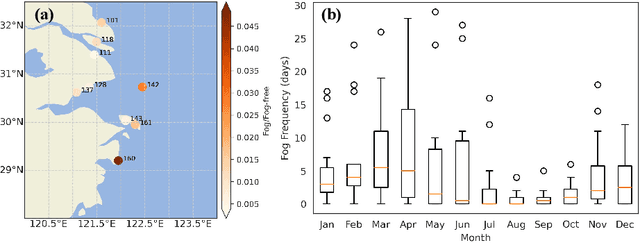
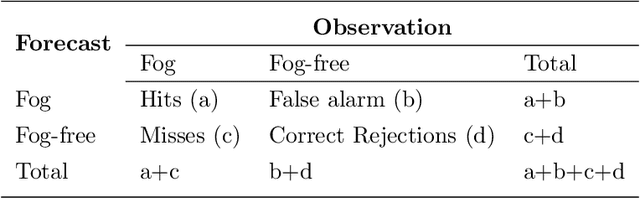
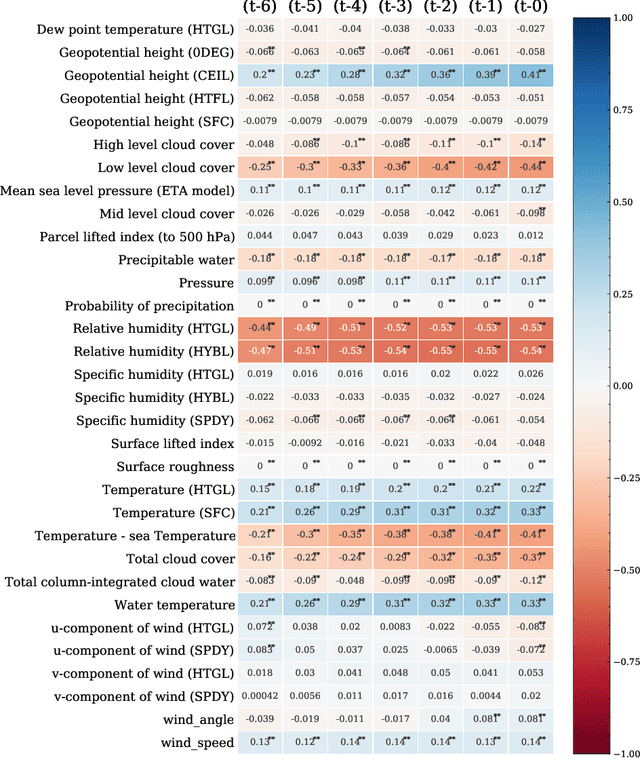
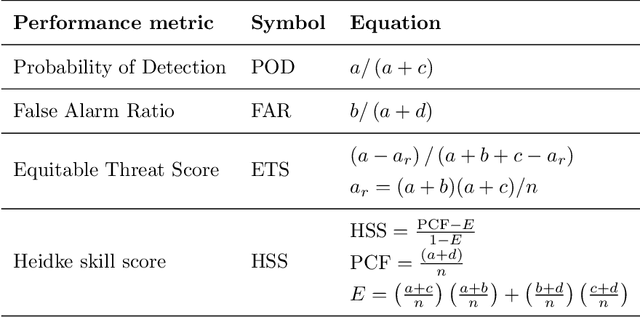
Accurate and timely prediction of sea fog is very important for effectively managing maritime and coastal economic activities. Given the intricate nature and inherent variability of sea fog, traditional numerical and statistical forecasting methods are often proven inadequate. This study aims to develop an advanced sea fog forecasting method embedded in a numerical weather prediction model using the Yangtze River Estuary (YRE) coastal area as a case study. Prior to training our machine learning model, we employ a time-lagged correlation analysis technique to identify key predictors and decipher the underlying mechanisms driving sea fog occurrence. In addition, we implement ensemble learning and a focal loss function to address the issue of imbalanced data, thereby enhancing the predictive ability of our model. To verify the accuracy of our method, we evaluate its performance using a comprehensive dataset spanning one year, which encompasses both weather station observations and historical forecasts. Remarkably, our machine learning-based approach surpasses the predictive performance of two conventional methods, the weather research and forecasting nonhydrostatic mesoscale model (WRF-NMM) and the algorithm developed by the National Oceanic and Atmospheric Administration (NOAA) Forecast Systems Laboratory (FSL). Specifically, in regard to predicting sea fog with a visibility of less than or equal to 1 km with a lead time of 60 hours, our methodology achieves superior results by increasing the probability of detection (POD) while simultaneously reducing the false alarm ratio (FAR).
Unsupervised Anomaly Detection with Local-Sensitive VQVAE and Global-Sensitive Transformers
Mar 29, 2023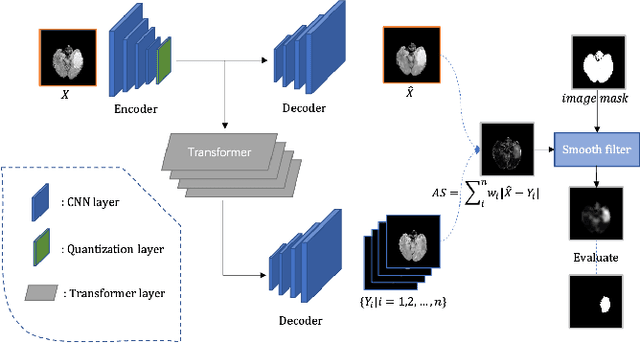

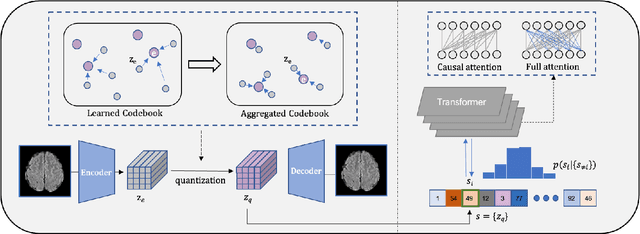
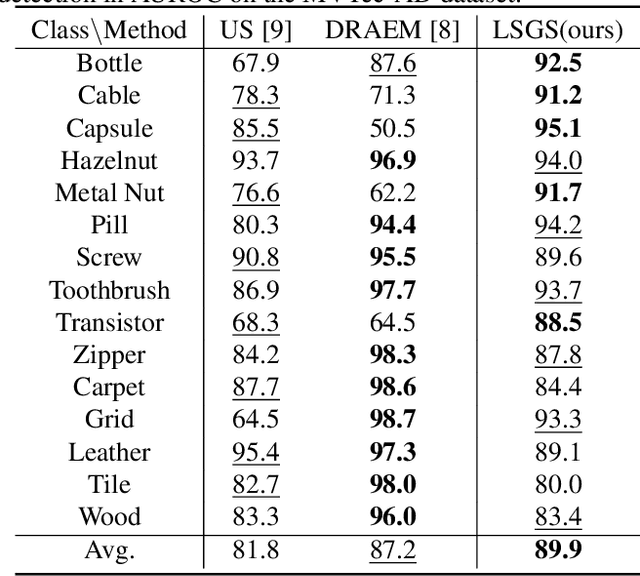
Unsupervised anomaly detection (UAD) has been widely implemented in industrial and medical applications, which reduces the cost of manual annotation and improves efficiency in disease diagnosis. Recently, deep auto-encoder with its variants has demonstrated its advantages in many UAD scenarios. Training on the normal data, these models are expected to locate anomalies by producing higher reconstruction error for the abnormal areas than the normal ones. However, this assumption does not always hold because of the uncontrollable generalization capability. To solve this problem, we present LSGS, a method that builds on Vector Quantised-Variational Autoencoder (VQVAE) with a novel aggregated codebook and transformers with global attention. In this work, the VQVAE focus on feature extraction and reconstruction of images, and the transformers fit the manifold and locate anomalies in the latent space. Then, leveraging the generated encoding sequences that conform to a normal distribution, we can reconstruct a more accurate image for locating the anomalies. Experiments on various datasets demonstrate the effectiveness of the proposed method.