 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeeing the Forest and the Trees: Query-Aware Tokenizer for Long-Video Multimodal Language Models
Nov 14, 2025Despite the recent advances in the video understanding ability of multimodal large language models (MLLMs), long video understanding remains a challenge. One of the main issues is that the number of vision tokens grows linearly with video length, which causes an explosion in attention cost, memory, and latency. To solve this challenge, we present Query-aware Token Selector (\textbf{QTSplus}), a lightweight yet powerful visual token selection module that serves as an information gate between the vision encoder and LLMs. Given a text query and video tokens, QTSplus dynamically selects the most important visual evidence for the input text query by (i) scoring visual tokens via cross-attention, (ii) \emph{predicting} an instance-specific retention budget based on the complexity of the query, and (iii) \emph{selecting} Top-$n$ tokens with a differentiable straight-through estimator during training and a hard gate at inference. Furthermore, a small re-encoder preserves temporal order using absolute time information, enabling second-level localization while maintaining global coverage. Integrated into Qwen2.5-VL, QTSplus compresses the vision stream by up to \textbf{89\%} and reduces end-to-end latency by \textbf{28\%} on long videos. The evaluation on eight long video understanding benchmarks shows near-parity accuracy overall when compared with the original Qwen models and outperforms the original model by \textbf{+20.5} and \textbf{+5.6} points respectively on TempCompass direction and order accuracies. These results show that QTSplus is an effective, general mechanism for scaling MLLMs to real-world long-video scenarios while preserving task-relevant evidence. We will make all code, data, and trained models' weights publicly available.
Faithful Contouring: Near-Lossless 3D Voxel Representation Free from Iso-surface
Nov 12, 2025



Accurate and efficient voxelized representations of 3D meshes are the foundation of 3D reconstruction and generation. However, existing representations based on iso-surface heavily rely on water-tightening or rendering optimization, which inevitably compromise geometric fidelity. We propose Faithful Contouring, a sparse voxelized representation that supports 2048+ resolutions for arbitrary meshes, requiring neither converting meshes to field functions nor extracting the isosurface during remeshing. It achieves near-lossless fidelity by preserving sharpness and internal structures, even for challenging cases with complex geometry and topology. The proposed method also shows flexibility for texturing, manipulation, and editing. Beyond representation, we design a dual-mode autoencoder for Faithful Contouring, enabling scalable and detail-preserving shape reconstruction. Extensive experiments show that Faithful Contouring surpasses existing methods in accuracy and efficiency for both representation and reconstruction. For direct representation, it achieves distance errors at the $10^{-5}$ level; for mesh reconstruction, it yields a 93\% reduction in Chamfer Distance and a 35\% improvement in F-score over strong baselines, confirming superior fidelity as a representation for 3D learning tasks.
Sparc3D: Sparse Representation and Construction for High-Resolution 3D Shapes Modeling
May 21, 2025High-fidelity 3D object synthesis remains significantly more challenging than 2D image generation due to the unstructured nature of mesh data and the cubic complexity of dense volumetric grids. Existing two-stage pipelines-compressing meshes with a VAE (using either 2D or 3D supervision), followed by latent diffusion sampling-often suffer from severe detail loss caused by inefficient representations and modality mismatches introduced in VAE. We introduce Sparc3D, a unified framework that combines a sparse deformable marching cubes representation Sparcubes with a novel encoder Sparconv-VAE. Sparcubes converts raw meshes into high-resolution ($1024^3$) surfaces with arbitrary topology by scattering signed distance and deformation fields onto a sparse cube, allowing differentiable optimization. Sparconv-VAE is the first modality-consistent variational autoencoder built entirely upon sparse convolutional networks, enabling efficient and near-lossless 3D reconstruction suitable for high-resolution generative modeling through latent diffusion. Sparc3D achieves state-of-the-art reconstruction fidelity on challenging inputs, including open surfaces, disconnected components, and intricate geometry. It preserves fine-grained shape details, reduces training and inference cost, and integrates naturally with latent diffusion models for scalable, high-resolution 3D generation.
Topology-Preserving Loss for Accurate and Anatomically Consistent Cardiac Mesh Reconstruction
Mar 10, 2025Accurate cardiac mesh reconstruction from volumetric data is essential for personalized cardiac modeling and clinical analysis. However, existing deformation-based approaches are prone to topological inconsistencies, particularly membrane penetration, which undermines the anatomical plausibility of the reconstructed mesh. To address this issue, we introduce Topology-Preserving Mesh Loss (TPM Loss), a novel loss function that explicitly enforces topological constraints during mesh deformation. By identifying topology-violating points, TPM Loss ensures spatially consistent reconstructions. Extensive experiments on CT and MRI datasets show that TPM Loss reduces topology violations by up to 93.1% while maintaining high segmentation accuracy (DSC: 89.1%-92.9%) and improving mesh fidelity (Chamfer Distance reduction up to 0.26 mm). These results demonstrate that TPM Loss effectively prevents membrane penetration and significantly improves cardiac mesh quality, enabling more accurate and anatomically consistent cardiac reconstructions.
Gaussians on their Way: Wasserstein-Constrained 4D Gaussian Splatting with State-Space Modeling
Nov 30, 2024Dynamic scene rendering has taken a leap forward with the rise of 4D Gaussian Splatting, but there's still one elusive challenge: how to make 3D Gaussians move through time as naturally as they would in the real world, all while keeping the motion smooth and consistent. In this paper, we unveil a fresh approach that blends state-space modeling with Wasserstein geometry, paving the way for a more fluid and coherent representation of dynamic scenes. We introduce a State Consistency Filter that merges prior predictions with the current observations, enabling Gaussians to stay true to their way over time. We also employ Wasserstein distance regularization to ensure smooth, consistent updates of Gaussian parameters, reducing motion artifacts. Lastly, we leverage Wasserstein geometry to capture both translational motion and shape deformations, creating a more physically plausible model for dynamic scenes. Our approach guides Gaussians along their natural way in the Wasserstein space, achieving smoother, more realistic motion and stronger temporal coherence. Experimental results show significant improvements in rendering quality and efficiency, outperforming current state-of-the-art techniques.
Differentiable Topology Estimating from Curvatures for 3D Shapes
Nov 28, 2024

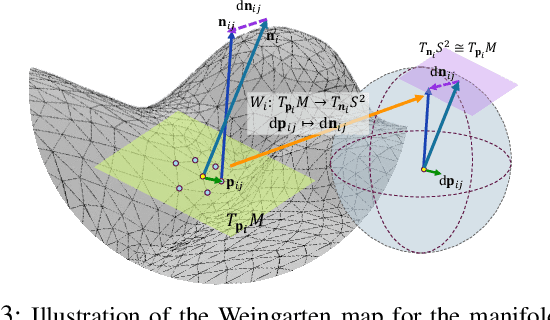

In the field of data-driven 3D shape analysis and generation, the estimation of global topological features from localized representations such as point clouds, voxels, and neural implicit fields is a longstanding challenge. This paper introduces a novel, differentiable algorithm tailored to accurately estimate the global topology of 3D shapes, overcoming the limitations of traditional methods rooted in mesh reconstruction and topological data analysis. The proposed method ensures high accuracy, efficiency, and instant computation with GPU compatibility. It begins with an efficient calculation of the self-adjoint Weingarten map for point clouds and its adaptations for other modalities. The curvatures are then extracted, and their integration over tangent differentiable Voronoi elements is utilized to estimate key topological invariants, including the Euler number and Genus. Additionally, an auto-optimization mechanism is implemented to refine the local moving frames and area elements based on the integrity of topological invariants. Experimental results demonstrate the method's superior performance across various datasets. The robustness and differentiability of the algorithm ensure its seamless integration into deep learning frameworks, offering vast potential for downstream tasks in 3D shape analysis.
ViT3D Alignment of LLaMA3: 3D Medical Image Report Generation
Oct 11, 2024



Automatic medical report generation (MRG), which aims to produce detailed text reports from medical images, has emerged as a critical task in this domain. MRG systems can enhance radiological workflows by reducing the time and effort required for report writing, thereby improving diagnostic efficiency. In this work, we present a novel approach for automatic MRG utilizing a multimodal large language model. Specifically, we employed the 3D Vision Transformer (ViT3D) image encoder introduced from M3D-CLIP to process 3D scans and use the Asclepius-Llama3-8B as the language model to generate the text reports by auto-regressive decoding. The experiment shows our model achieved an average Green score of 0.3 on the MRG task validation set and an average accuracy of 0.61 on the visual question answering (VQA) task validation set, outperforming the baseline model. Our approach demonstrates the effectiveness of the ViT3D alignment of LLaMA3 for automatic MRG and VQA tasks by tuning the model on a small dataset.
Explicit Differentiable Slicing and Global Deformation for Cardiac Mesh Reconstruction
Sep 03, 2024



Mesh reconstruction of the cardiac anatomy from medical images is useful for shape and motion measurements and biophysics simulations to facilitate the assessment of cardiac function and health. However, 3D medical images are often acquired as 2D slices that are sparsely sampled and noisy, and mesh reconstruction on such data is a challenging task. Traditional voxel-based approaches rely on pre- and post-processing that compromises image fidelity, while mesh-level deep learning approaches require mesh annotations that are difficult to get. Therefore, direct cross-domain supervision from 2D images to meshes is a key technique for advancing 3D learning in medical imaging, but it has not been well-developed. While there have been attempts to approximate the optimized meshes' slicing, few existing methods directly use 2D slices to supervise mesh reconstruction in a differentiable manner. Here, we propose a novel explicit differentiable voxelization and slicing (DVS) algorithm that allows gradient backpropagation to a mesh from its slices, facilitating refined mesh optimization directly supervised by the losses defined on 2D images. Further, we propose an innovative framework for extracting patient-specific left ventricle (LV) meshes from medical images by coupling DVS with a graph harmonic deformation (GHD) mesh morphing descriptor of cardiac shape that naturally preserves mesh quality and smoothness during optimization. Experimental results demonstrate that our method achieves state-of-the-art performance in cardiac mesh reconstruction tasks from CT and MRI, with an overall Dice score of 90% on multi-datasets, outperforming existing approaches. The proposed method can further quantify clinically useful parameters such as ejection fraction and global myocardial strains, closely matching the ground truth and surpassing the traditional voxel-based approach in sparse images.
MeshAnything V2: Artist-Created Mesh Generation With Adjacent Mesh Tokenization
Aug 05, 2024

We introduce MeshAnything V2, an autoregressive transformer that generates Artist-Created Meshes (AM) aligned to given shapes. It can be integrated with various 3D asset production pipelines to achieve high-quality, highly controllable AM generation. MeshAnything V2 surpasses previous methods in both efficiency and performance using models of the same size. These improvements are due to our newly proposed mesh tokenization method: Adjacent Mesh Tokenization (AMT). Different from previous methods that represent each face with three vertices, AMT uses a single vertex whenever possible. Compared to previous methods, AMT requires about half the token sequence length to represent the same mesh in average. Furthermore, the token sequences from AMT are more compact and well-structured, fundamentally benefiting AM generation. Our extensive experiments show that AMT significantly improves the efficiency and performance of AM generation. Project Page: https://buaacyw.github.io/meshanything-v2/
Differentiable Voxelization and Mesh Morphing
Jul 15, 2024
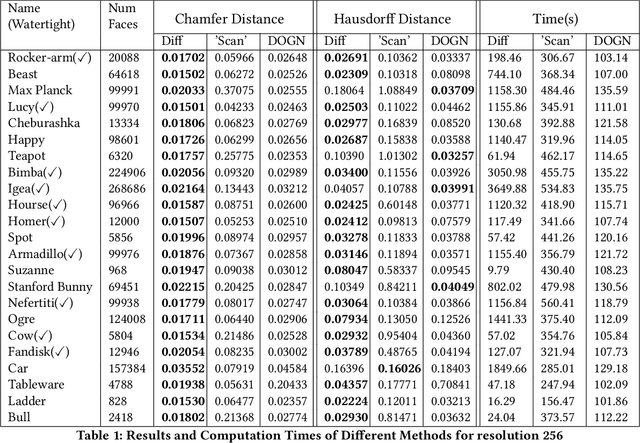
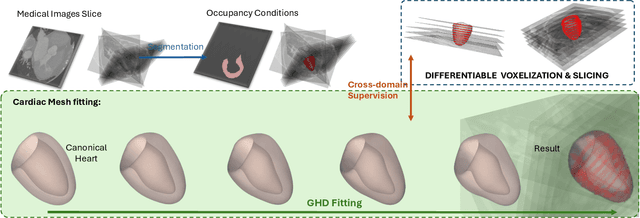

In this paper, we propose the differentiable voxelization of 3D meshes via the winding number and solid angles. The proposed approach achieves fast, flexible, and accurate voxelization of 3D meshes, admitting the computation of gradients with respect to the input mesh and GPU acceleration. We further demonstrate the application of the proposed voxelization in mesh morphing, where the voxelized mesh is deformed by a neural network. The proposed method is evaluated on the ShapeNet dataset and achieves state-of-the-art performance in terms of both accuracy and efficiency.