 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGlazyBench: A Benchmark for Ceramic Glaze Property Prediction and Image Generation
May 07, 2026Developing ceramic glazes is a costly, time-consuming process of trial and error due to complex chemistry, placing a significant burden on independent artists. While recent advances in multimodal AI offer a modern solution, the field lacks the large-scale datasets required to train these models. We propose GlazyBench, the first dataset for AI-assisted glaze design. Comprising 23,148 real glaze formulations, GlazyBench supports two primary tasks: predicting post-firing surface properties, such as color and transparency, from raw materials, and generating accurate visual representations of the glaze based on these properties. We establish comprehensive baselines for property prediction using traditional machine learning and large language models, alongside image generation benchmarks using deep generative and large multimodal models. Our experiments demonstrate promising yet challenging results. GlazyBench pioneers a new research direction in AI-assisted material design, providing a standardized benchmark for systematic evaluation.
ViewSAM: Learning View-aware Cross-modal Semantics for Weakly Supervised Cross-view Referring Multi-Object Tracking
May 04, 2026Cross-view Referring Multi-Object Tracking (CRMOT) aims to track multiple objects specified by natural language across multiple camera views, with globally consistent identities. Despite recent progress, existing methods rely heavily on costly frame-level spatial annotations and cross-view identity supervision. To reduce such reliance, we explore CRMOT under weak supervision by leveraging the capabilities of foundation models. However, our empirical study shows that directly applying foundation models such as SAM2 and SAM3, even with task-specific modifications, fails to accurately understand referring expressions and maintain consistent identities across views. Yet, they remain effective at producing reliable object tracklets that can serve as pseudo supervision. We therefore repurpose foundation models as pseudo-label generators and propose a two-stage framework for weakly supervised CRMOT, using only object category labels as coarse-grained supervision. In the first stage, we design an Affinity-guided Cross-view Re-prompting strategy to refine and associate SAM3-generated tracklets across cameras, producing reliable cross-view pseudo labels for subsequent training. In the second stage, we introduce ViewSAM, a CRMOT model built upon SAM2 that explicitly models view-aware cross-modal semantics. By formulating view-induced variations as learnable conditions, ViewSAM bridges the gap between view-variant visual observations and view-invariant textual expressions, enabling robust cross-view referring tracking with only approximately 10% additional parameters. Extensive experiments demonstrate that ViewSAM achieves SOTA performance under weak supervision and remains competitive with fully supervised methods.
NovBench: Evaluating Large Language Models on Academic Paper Novelty Assessment
Apr 13, 2026Novelty is a core requirement in academic publishing and a central focus of peer review, yet the growing volume of submissions has placed increasing pressure on human reviewers. While large language models (LLMs), including those fine-tuned on peer review data, have shown promise in generating review comments, the absence of a dedicated benchmark has limited systematic evaluation of their ability to assess research novelty. To address this gap, we introduce NovBench, the first large-scale benchmark designed to evaluate LLMs' capability to generate novelty evaluations in support of human peer review. NovBench comprises 1,684 paper-review pairs from a leading NLP conference, including novelty descriptions extracted from paper introductions and corresponding expert-written novelty evaluations. We focus on both sources because the introduction provides a standardized and explicit articulation of novelty claims, while expert-written novelty evaluations constitute one of the current gold standards of human judgment. Furthermore, we propose a four-dimensional evaluation framework (including Relevance, Correctness, Coverage, and Clarity) to assess the quality of LLM-generated novelty evaluations. Extensive experiments on both general and specialized LLMs under different prompting strategies reveal that current models exhibit limited understanding of scientific novelty, and that fine--tuned models often suffer from instruction-following deficiencies. These findings underscore the need for targeted fine-tuning strategies that jointly improve novelty comprehension and instruction adherence.
Seeing the Forest and the Trees: Query-Aware Tokenizer for Long-Video Multimodal Language Models
Nov 14, 2025Despite the recent advances in the video understanding ability of multimodal large language models (MLLMs), long video understanding remains a challenge. One of the main issues is that the number of vision tokens grows linearly with video length, which causes an explosion in attention cost, memory, and latency. To solve this challenge, we present Query-aware Token Selector (\textbf{QTSplus}), a lightweight yet powerful visual token selection module that serves as an information gate between the vision encoder and LLMs. Given a text query and video tokens, QTSplus dynamically selects the most important visual evidence for the input text query by (i) scoring visual tokens via cross-attention, (ii) \emph{predicting} an instance-specific retention budget based on the complexity of the query, and (iii) \emph{selecting} Top-$n$ tokens with a differentiable straight-through estimator during training and a hard gate at inference. Furthermore, a small re-encoder preserves temporal order using absolute time information, enabling second-level localization while maintaining global coverage. Integrated into Qwen2.5-VL, QTSplus compresses the vision stream by up to \textbf{89\%} and reduces end-to-end latency by \textbf{28\%} on long videos. The evaluation on eight long video understanding benchmarks shows near-parity accuracy overall when compared with the original Qwen models and outperforms the original model by \textbf{+20.5} and \textbf{+5.6} points respectively on TempCompass direction and order accuracies. These results show that QTSplus is an effective, general mechanism for scaling MLLMs to real-world long-video scenarios while preserving task-relevant evidence. We will make all code, data, and trained models' weights publicly available.
CMI-Bench: A Comprehensive Benchmark for Evaluating Music Instruction Following
Jun 14, 2025Recent advances in audio-text large language models (LLMs) have opened new possibilities for music understanding and generation. However, existing benchmarks are limited in scope, often relying on simplified tasks or multi-choice evaluations that fail to reflect the complexity of real-world music analysis. We reinterpret a broad range of traditional MIR annotations as instruction-following formats and introduce CMI-Bench, a comprehensive music instruction following benchmark designed to evaluate audio-text LLMs on a diverse set of music information retrieval (MIR) tasks. These include genre classification, emotion regression, emotion tagging, instrument classification, pitch estimation, key detection, lyrics transcription, melody extraction, vocal technique recognition, instrument performance technique detection, music tagging, music captioning, and (down)beat tracking: reflecting core challenges in MIR research. Unlike previous benchmarks, CMI-Bench adopts standardized evaluation metrics consistent with previous state-of-the-art MIR models, ensuring direct comparability with supervised approaches. We provide an evaluation toolkit supporting all open-source audio-textual LLMs, including LTU, Qwen-audio, SALMONN, MusiLingo, etc. Experiment results reveal significant performance gaps between LLMs and supervised models, along with their culture, chronological and gender bias, highlighting the potential and limitations of current models in addressing MIR tasks. CMI-Bench establishes a unified foundation for evaluating music instruction following, driving progress in music-aware LLMs.
MMAR: A Challenging Benchmark for Deep Reasoning in Speech, Audio, Music, and Their Mix
May 19, 2025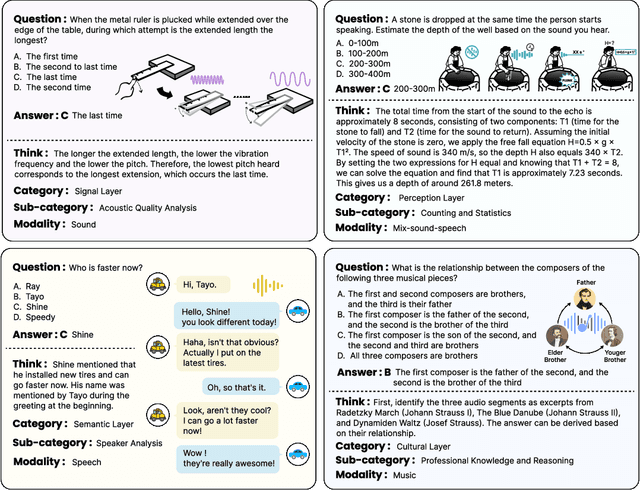

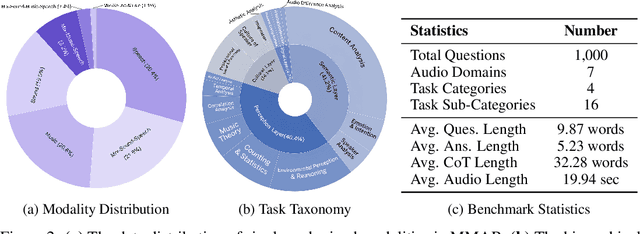
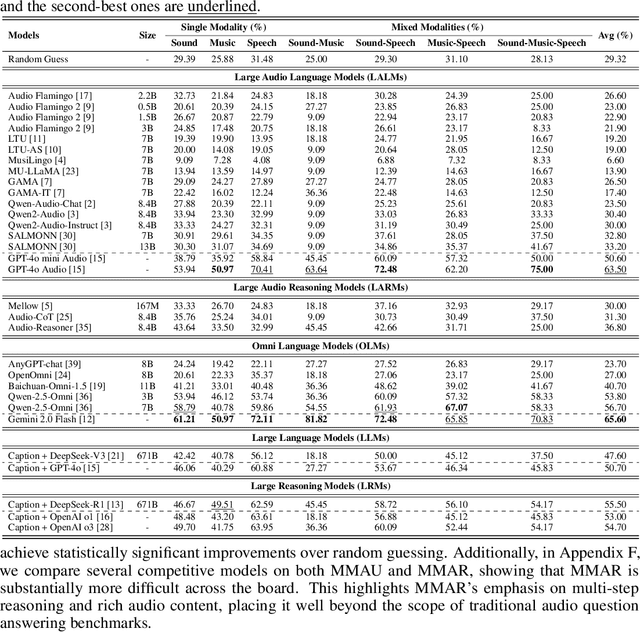
We introduce MMAR, a new benchmark designed to evaluate the deep reasoning capabilities of Audio-Language Models (ALMs) across massive multi-disciplinary tasks. MMAR comprises 1,000 meticulously curated audio-question-answer triplets, collected from real-world internet videos and refined through iterative error corrections and quality checks to ensure high quality. Unlike existing benchmarks that are limited to specific domains of sound, music, or speech, MMAR extends them to a broad spectrum of real-world audio scenarios, including mixed-modality combinations of sound, music, and speech. Each question in MMAR is hierarchically categorized across four reasoning layers: Signal, Perception, Semantic, and Cultural, with additional sub-categories within each layer to reflect task diversity and complexity. To further foster research in this area, we annotate every question with a Chain-of-Thought (CoT) rationale to promote future advancements in audio reasoning. Each item in the benchmark demands multi-step deep reasoning beyond surface-level understanding. Moreover, a part of the questions requires graduate-level perceptual and domain-specific knowledge, elevating the benchmark's difficulty and depth. We evaluate MMAR using a broad set of models, including Large Audio-Language Models (LALMs), Large Audio Reasoning Models (LARMs), Omni Language Models (OLMs), Large Language Models (LLMs), and Large Reasoning Models (LRMs), with audio caption inputs. The performance of these models on MMAR highlights the benchmark's challenging nature, and our analysis further reveals critical limitations of understanding and reasoning capabilities among current models. We hope MMAR will serve as a catalyst for future advances in this important but little-explored area.
ViT3D Alignment of LLaMA3: 3D Medical Image Report Generation
Oct 11, 2024



Automatic medical report generation (MRG), which aims to produce detailed text reports from medical images, has emerged as a critical task in this domain. MRG systems can enhance radiological workflows by reducing the time and effort required for report writing, thereby improving diagnostic efficiency. In this work, we present a novel approach for automatic MRG utilizing a multimodal large language model. Specifically, we employed the 3D Vision Transformer (ViT3D) image encoder introduced from M3D-CLIP to process 3D scans and use the Asclepius-Llama3-8B as the language model to generate the text reports by auto-regressive decoding. The experiment shows our model achieved an average Green score of 0.3 on the MRG task validation set and an average accuracy of 0.61 on the visual question answering (VQA) task validation set, outperforming the baseline model. Our approach demonstrates the effectiveness of the ViT3D alignment of LLaMA3 for automatic MRG and VQA tasks by tuning the model on a small dataset.