 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSGLoc: Semantic Localization System for Camera Pose Estimation from 3D Gaussian Splatting Representation
Jul 16, 2025We propose SGLoc, a novel localization system that directly regresses camera poses from 3D Gaussian Splatting (3DGS) representation by leveraging semantic information. Our method utilizes the semantic relationship between 2D image and 3D scene representation to estimate the 6DoF pose without prior pose information. In this system, we introduce a multi-level pose regression strategy that progressively estimates and refines the pose of query image from the global 3DGS map, without requiring initial pose priors. Moreover, we introduce a semantic-based global retrieval algorithm that establishes correspondences between 2D (image) and 3D (3DGS map). By matching the extracted scene semantic descriptors of 2D query image and 3DGS semantic representation, we align the image with the local region of the global 3DGS map, thereby obtaining a coarse pose estimation. Subsequently, we refine the coarse pose by iteratively optimizing the difference between the query image and the rendered image from 3DGS. Our SGLoc demonstrates superior performance over baselines on 12scenes and 7scenes datasets, showing excellent capabilities in global localization without initial pose prior. Code will be available at https://github.com/IRMVLab/SGLoc.
Design and Evaluation of Deep Learning-Based Dual-Spectrum Image Fusion Methods
Jun 09, 2025Visible images offer rich texture details, while infrared images emphasize salient targets. Fusing these complementary modalities enhances scene understanding, particularly for advanced vision tasks under challenging conditions. Recently, deep learning-based fusion methods have gained attention, but current evaluations primarily rely on general-purpose metrics without standardized benchmarks or downstream task performance. Additionally, the lack of well-developed dual-spectrum datasets and fair algorithm comparisons hinders progress. To address these gaps, we construct a high-quality dual-spectrum dataset captured in campus environments, comprising 1,369 well-aligned visible-infrared image pairs across four representative scenarios: daytime, nighttime, smoke occlusion, and underpasses. We also propose a comprehensive and fair evaluation framework that integrates fusion speed, general metrics, and object detection performance using the lang-segment-anything model to ensure fairness in downstream evaluation. Extensive experiments benchmark several state-of-the-art fusion algorithms under this framework. Results demonstrate that fusion models optimized for downstream tasks achieve superior performance in target detection, especially in low-light and occluded scenes. Notably, some algorithms that perform well on general metrics do not translate to strong downstream performance, highlighting limitations of current evaluation practices and validating the necessity of our proposed framework. The main contributions of this work are: (1)a campus-oriented dual-spectrum dataset with diverse and challenging scenes; (2) a task-aware, comprehensive evaluation framework; and (3) thorough comparative analysis of leading fusion methods across multiple datasets, offering insights for future development.
Adaptable and Precise: Enterprise-Scenario LLM Function-Calling Capability Training Pipeline
Dec 20, 2024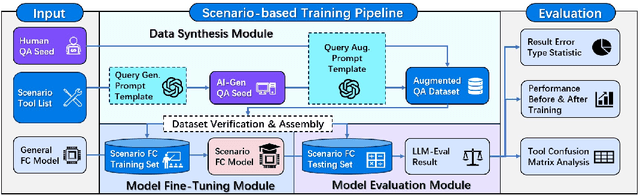


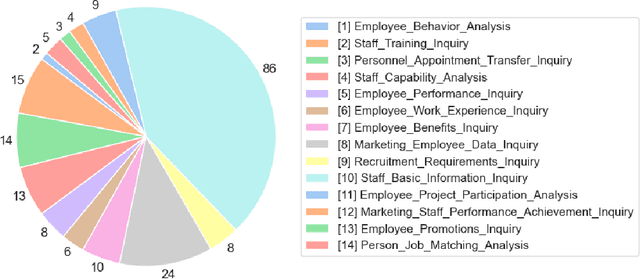
Enterprises possess a vast array of API assets scattered across various functions, forming the backbone of existing business processes. By leveraging these APIs as functional tools, enterprises can design diverse, scenario-specific agent applications, driven by on-premise function-calling models as the core engine. However, generic models often fail to meet enterprise requirements in terms of computational efficiency, output accuracy, and stability, necessitating scenario-specific adaptation. In this paper, we propose a training pipeline for function-calling capabilities tailored to real-world business scenarios. This pipeline includes the synthesis and augmentation of scenario-specific function-calling data, model fine-tuning, and performance evaluation and analysis. Using this pipeline, we generated 1,260 fully AI-generated samples and 1,035 augmented manually-labeled samples in digital HR agent scenario. The Qwen2.5-Coder-7B-Instruct model was employed as the base model and fine-tuned using the LoRA method on four GPUs with 24GB VRAM. Our fine-tuned model demonstrated outstanding performance in evaluations and practical applications, surpassing GPT-4 and GPT-4o in accuracy on the test set. These results validate the reliability of the proposed pipeline for training scenario-specific function-calling models.
ViT3D Alignment of LLaMA3: 3D Medical Image Report Generation
Oct 11, 2024



Automatic medical report generation (MRG), which aims to produce detailed text reports from medical images, has emerged as a critical task in this domain. MRG systems can enhance radiological workflows by reducing the time and effort required for report writing, thereby improving diagnostic efficiency. In this work, we present a novel approach for automatic MRG utilizing a multimodal large language model. Specifically, we employed the 3D Vision Transformer (ViT3D) image encoder introduced from M3D-CLIP to process 3D scans and use the Asclepius-Llama3-8B as the language model to generate the text reports by auto-regressive decoding. The experiment shows our model achieved an average Green score of 0.3 on the MRG task validation set and an average accuracy of 0.61 on the visual question answering (VQA) task validation set, outperforming the baseline model. Our approach demonstrates the effectiveness of the ViT3D alignment of LLaMA3 for automatic MRG and VQA tasks by tuning the model on a small dataset.
A Quantitative Approach to Understand Self-Supervised Models as Cross-lingual Feature Extractors
Nov 27, 2023



In this work, we study the features extracted by English self-supervised learning (SSL) models in cross-lingual contexts and propose a new metric to predict the quality of feature representations. Using automatic speech recognition (ASR) as a downstream task, we analyze the effect of model size, training objectives, and model architecture on the models' performance as a feature extractor for a set of topologically diverse corpora. We develop a novel metric, the Phonetic-Syntax Ratio (PSR), to measure the phonetic and synthetic information in the extracted representations using deep generalized canonical correlation analysis. Results show the contrastive loss in the wav2vec2.0 objective facilitates more effective cross-lingual feature extraction. There is a positive correlation between PSR scores and ASR performance, suggesting that phonetic information extracted by monolingual SSL models can be used for downstream tasks in cross-lingual settings. The proposed metric is an effective indicator of the quality of the representations and can be useful for model selection.