 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptable and Precise: Enterprise-Scenario LLM Function-Calling Capability Training Pipeline
Dec 20, 2024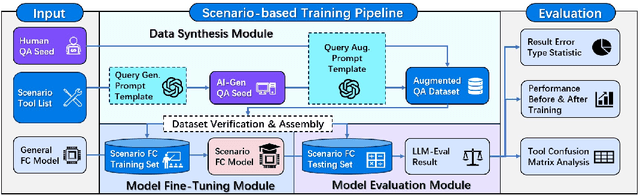


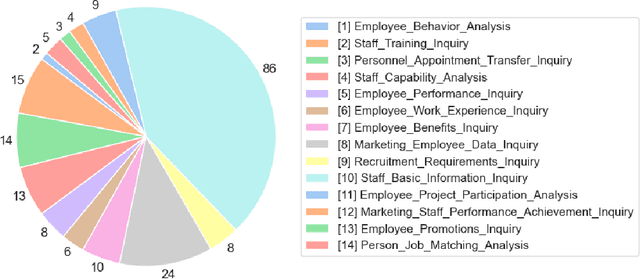
Enterprises possess a vast array of API assets scattered across various functions, forming the backbone of existing business processes. By leveraging these APIs as functional tools, enterprises can design diverse, scenario-specific agent applications, driven by on-premise function-calling models as the core engine. However, generic models often fail to meet enterprise requirements in terms of computational efficiency, output accuracy, and stability, necessitating scenario-specific adaptation. In this paper, we propose a training pipeline for function-calling capabilities tailored to real-world business scenarios. This pipeline includes the synthesis and augmentation of scenario-specific function-calling data, model fine-tuning, and performance evaluation and analysis. Using this pipeline, we generated 1,260 fully AI-generated samples and 1,035 augmented manually-labeled samples in digital HR agent scenario. The Qwen2.5-Coder-7B-Instruct model was employed as the base model and fine-tuned using the LoRA method on four GPUs with 24GB VRAM. Our fine-tuned model demonstrated outstanding performance in evaluations and practical applications, surpassing GPT-4 and GPT-4o in accuracy on the test set. These results validate the reliability of the proposed pipeline for training scenario-specific function-calling models.
Muti-Scale And Token Mergence: Make Your ViT More Efficient
Jun 08, 2023
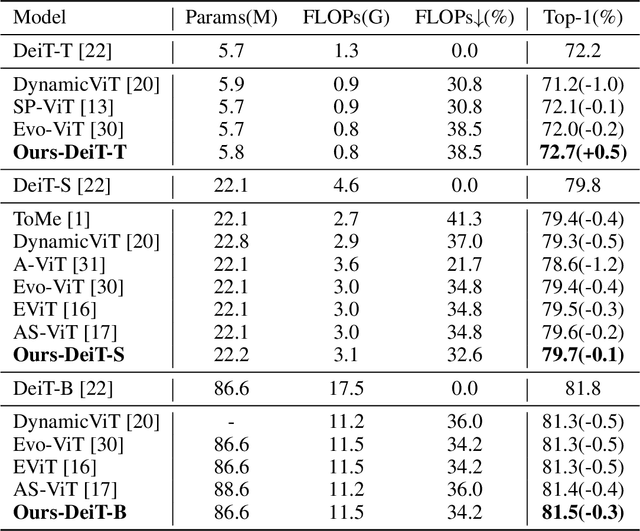

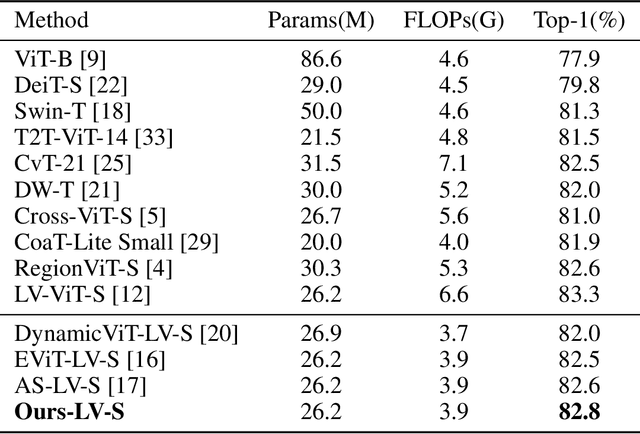
Since its inception, Vision Transformer (ViT) has emerged as a prevalent model in the computer vision domain. Nonetheless, the multi-head self-attention (MHSA) mechanism in ViT is computationally expensive due to its calculation of relationships among all tokens. Although some techniques mitigate computational overhead by discarding tokens, this also results in the loss of potential information from those tokens. To tackle these issues, we propose a novel token pruning method that retains information from non-crucial tokens by merging them with more crucial tokens, thereby mitigating the impact of pruning on model performance. Crucial and non-crucial tokens are identified by their importance scores and merged based on similarity scores. Furthermore, multi-scale features are exploited to represent images, which are fused prior to token pruning to produce richer feature representations. Importantly, our method can be seamlessly integrated with various ViTs, enhancing their adaptability. Experimental evidence substantiates the efficacy of our approach in reducing the influence of token pruning on model performance. For instance, on the ImageNet dataset, it achieves a remarkable 33% reduction in computational costs while only incurring a 0.1% decrease in accuracy on DeiT-S.