 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSLAM-LLM: A Modular, Open-Source Multimodal Large Language Model Framework and Best Practice for Speech, Language, Audio and Music Processing
Jan 14, 2026The recent surge in open-source Multimodal Large Language Models (MLLM) frameworks, such as LLaVA, provides a convenient kickoff for artificial intelligence developers and researchers. However, most of the MLLM frameworks take vision as the main input modality, and provide limited in-depth support for the modality of speech, audio, and music. This situation hinders the development of audio-language models, and forces researchers to spend a lot of effort on code writing and hyperparameter tuning. We present SLAM-LLM, an open-source deep learning framework designed to train customized MLLMs, focused on speech, language, audio, and music processing. SLAM-LLM provides a modular configuration of different encoders, projectors, LLMs, and parameter-efficient fine-tuning plugins. SLAM-LLM also includes detailed training and inference recipes for mainstream tasks, along with high-performance checkpoints like LLM-based Automatic Speech Recognition (ASR), Automated Audio Captioning (AAC), and Music Captioning (MC). Some of these recipes have already reached or are nearing state-of-the-art performance, and some relevant techniques have also been accepted by academic papers. We hope SLAM-LLM will accelerate iteration, development, data engineering, and model training for researchers. We are committed to continually pushing forward audio-based MLLMs through this open-source framework, and call on the community to contribute to the LLM-based speech, audio and music processing.
Omni-Captioner: Data Pipeline, Models, and Benchmark for Omni Detailed Perception
Oct 14, 2025Fine-grained perception of multimodal information is critical for advancing human-AI interaction. With recent progress in audio-visual technologies, Omni Language Models (OLMs), capable of processing audio and video signals in parallel, have emerged as a promising paradigm for achieving richer understanding and reasoning. However, their capacity to capture and describe fine-grained details remains limited explored. In this work, we present a systematic and comprehensive investigation of omni detailed perception from the perspectives of the data pipeline, models, and benchmark. We first identify an inherent "co-growth" between detail and hallucination in current OLMs. To address this, we propose Omni-Detective, an agentic data generation pipeline integrating tool-calling, to autonomously produce highly detailed yet minimally hallucinatory multimodal data. Based on the data generated with Omni-Detective, we train two captioning models: Audio-Captioner for audio-only detailed perception, and Omni-Captioner for audio-visual detailed perception. Under the cascade evaluation protocol, Audio-Captioner achieves the best performance on MMAU and MMAR among all open-source models, surpassing Gemini 2.5 Flash and delivering performance comparable to Gemini 2.5 Pro. On existing detailed captioning benchmarks, Omni-Captioner sets a new state-of-the-art on VDC and achieves the best trade-off between detail and hallucination on the video-SALMONN 2 testset. Given the absence of a dedicated benchmark for omni detailed perception, we design Omni-Cloze, a novel cloze-style evaluation for detailed audio, visual, and audio-visual captioning that ensures stable, efficient, and reliable assessment. Experimental results and analysis demonstrate the effectiveness of Omni-Detective in generating high-quality detailed captions, as well as the superiority of Omni-Cloze in evaluating such detailed captions.
MMAR: A Challenging Benchmark for Deep Reasoning in Speech, Audio, Music, and Their Mix
May 19, 2025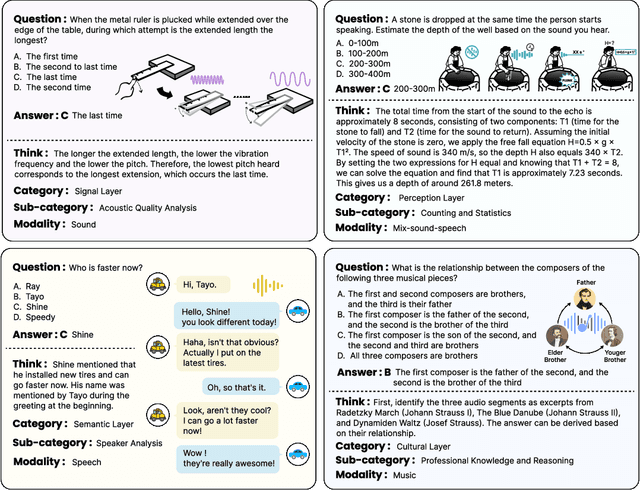

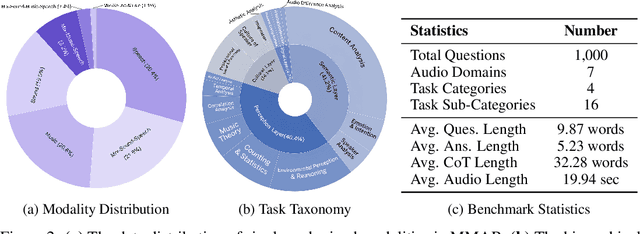
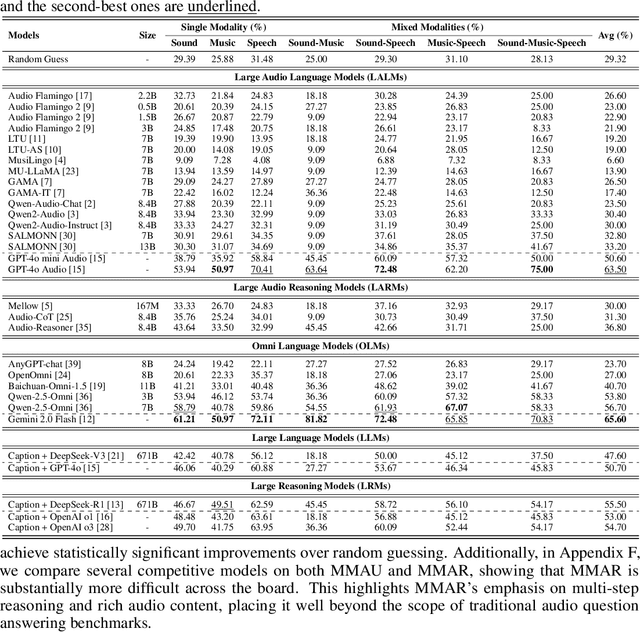
We introduce MMAR, a new benchmark designed to evaluate the deep reasoning capabilities of Audio-Language Models (ALMs) across massive multi-disciplinary tasks. MMAR comprises 1,000 meticulously curated audio-question-answer triplets, collected from real-world internet videos and refined through iterative error corrections and quality checks to ensure high quality. Unlike existing benchmarks that are limited to specific domains of sound, music, or speech, MMAR extends them to a broad spectrum of real-world audio scenarios, including mixed-modality combinations of sound, music, and speech. Each question in MMAR is hierarchically categorized across four reasoning layers: Signal, Perception, Semantic, and Cultural, with additional sub-categories within each layer to reflect task diversity and complexity. To further foster research in this area, we annotate every question with a Chain-of-Thought (CoT) rationale to promote future advancements in audio reasoning. Each item in the benchmark demands multi-step deep reasoning beyond surface-level understanding. Moreover, a part of the questions requires graduate-level perceptual and domain-specific knowledge, elevating the benchmark's difficulty and depth. We evaluate MMAR using a broad set of models, including Large Audio-Language Models (LALMs), Large Audio Reasoning Models (LARMs), Omni Language Models (OLMs), Large Language Models (LLMs), and Large Reasoning Models (LRMs), with audio caption inputs. The performance of these models on MMAR highlights the benchmark's challenging nature, and our analysis further reveals critical limitations of understanding and reasoning capabilities among current models. We hope MMAR will serve as a catalyst for future advances in this important but little-explored area.
Interleaved Speech-Text Language Models are Simple Streaming Text to Speech Synthesizers
Dec 23, 2024This paper introduces Interleaved Speech-Text Language Model (IST-LM) for streaming zero-shot Text-to-Speech (TTS). Unlike many previous approaches, IST-LM is directly trained on interleaved sequences of text and speech tokens with a fixed ratio, eliminating the need for additional efforts in duration prediction and grapheme-to-phoneme alignment. The ratio of text chunk size to speech chunk size is crucial for the performance of IST-LM. To explore this, we conducted a comprehensive series of statistical analyses on the training data and performed correlation analysis with the final performance, uncovering several key factors: 1) the distance between speech tokens and their corresponding text tokens, 2) the number of future text tokens accessible to each speech token, and 3) the frequency of speech tokens precedes their corresponding text tokens. Experimental results demonstrate how to achieve an optimal streaming TTS system without complicated engineering optimization, which has a limited gap with the non-streaming system. IST-LM is conceptually simple and empirically powerful, paving the way for streaming TTS with minimal overhead while largely maintaining performance, showcasing broad prospects coupled with real-time text stream from LLMs.
SLAM-Omni: Timbre-Controllable Voice Interaction System with Single-Stage Training
Dec 20, 2024

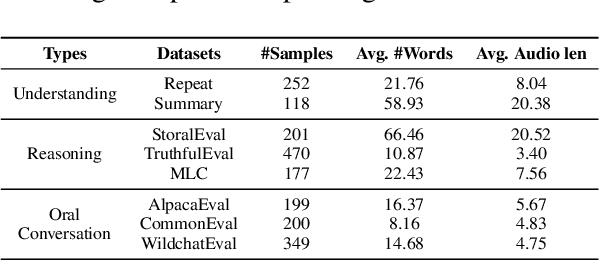
Recent advancements highlight the potential of end-to-end real-time spoken dialogue systems, showcasing their low latency and high quality. In this paper, we introduce SLAM-Omni, a timbre-controllable, end-to-end voice interaction system with single-stage training. SLAM-Omni achieves zero-shot timbre control by modeling spoken language with semantic tokens and decoupling speaker information to a vocoder. By predicting grouped speech semantic tokens at each step, our method significantly reduces the sequence length of audio tokens, accelerating both training and inference. Additionally, we propose historical text prompting to compress dialogue history, facilitating efficient multi-round interactions. Comprehensive evaluations reveal that SLAM-Omni outperforms prior models of similar scale, requiring only 15 hours of training on 4 GPUs with limited data. Notably, it is the first spoken dialogue system to achieve competitive performance with a single-stage training approach, eliminating the need for pre-training on TTS or ASR tasks. Further experiments validate its multilingual and multi-turn dialogue capabilities on larger datasets.
CRUXEval-X: A Benchmark for Multilingual Code Reasoning, Understanding and Execution
Aug 23, 2024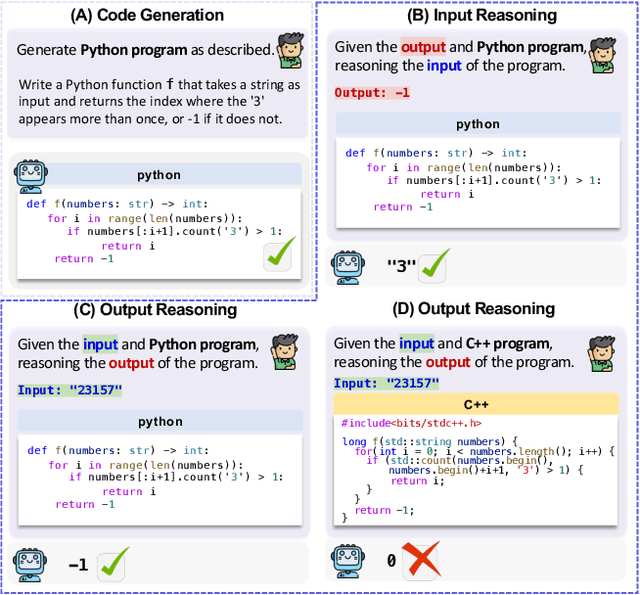
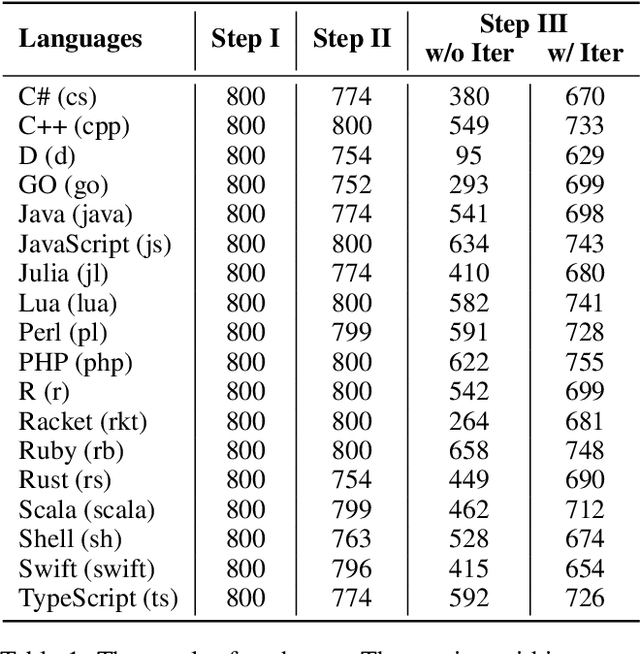
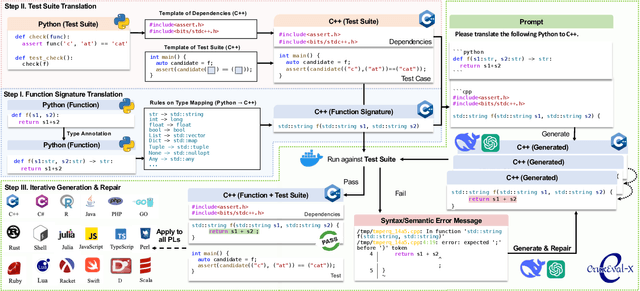

Code benchmarks such as HumanEval are widely adopted to evaluate Large Language Models' (LLMs) coding capabilities. However, there is an unignorable programming language bias in existing code benchmarks -- over 95% code generation benchmarks are dominated by Python, leaving the LLMs' capabilities in other programming languages such as Java and C/C++ unknown. Moreover, coding task bias is also crucial. Most benchmarks focus on code generation capability, while benchmarks for code reasoning (given input, reasoning output; and given output, reasoning input), an essential coding capability, are insufficient. Yet, constructing multi-lingual benchmarks can be expensive and labor-intensive, and codes in contest websites such as Leetcode suffer from data contamination during training. To fill this gap, we propose CRUXEVAL-X, a multi-lingual code reasoning benchmark that contains 19 programming languages. It comprises at least 600 subjects for each language, along with 19K content-consistent tests in total. In particular, the construction pipeline of CRUXEVAL-X works in a fully automated and test-guided manner, which iteratively generates and repairs based on execution feedback. Also, to cross language barriers (e.g., dynamic/static type systems in Python/C++), we formulated various transition rules between language pairs to facilitate translation. Our intensive evaluation of 24 representative LLMs reveals the correlation between language pairs. For example, TypeScript and JavaScript show a significant positive correlation, while Racket has less correlation with other languages. More interestingly, even a model trained solely on Python can achieve at most 34.4% Pass@1 in other languages, revealing the cross-language generalization of LLMs.
Pearl: A Production-ready Reinforcement Learning Agent
Dec 06, 2023



Reinforcement Learning (RL) offers a versatile framework for achieving long-term goals. Its generality allows us to formalize a wide range of problems that real-world intelligent systems encounter, such as dealing with delayed rewards, handling partial observability, addressing the exploration and exploitation dilemma, utilizing offline data to improve online performance, and ensuring safety constraints are met. Despite considerable progress made by the RL research community in addressing these issues, existing open-source RL libraries tend to focus on a narrow portion of the RL solution pipeline, leaving other aspects largely unattended. This paper introduces Pearl, a Production-ready RL agent software package explicitly designed to embrace these challenges in a modular fashion. In addition to presenting preliminary benchmark results, this paper highlights Pearl's industry adoptions to demonstrate its readiness for production usage. Pearl is open sourced on Github at github.com/facebookresearch/pearl and its official website is located at pearlagent.github.io.
Optimizing Long-term Value for Auction-Based Recommender Systems via On-Policy Reinforcement Learning
May 24, 2023Auction-based recommender systems are prevalent in online advertising platforms, but they are typically optimized to allocate recommendation slots based on immediate expected return metrics, neglecting the downstream effects of recommendations on user behavior. In this study, we employ reinforcement learning to optimize for long-term return metrics in an auction-based recommender system. Utilizing temporal difference learning, a fundamental reinforcement learning algorithm, we implement an one-step policy improvement approach that biases the system towards recommendations with higher long-term user engagement metrics. This optimizes value over long horizons while maintaining compatibility with the auction framework. Our approach is grounded in dynamic programming ideas which show that our method provably improves upon the existing auction-based base policy. Through an online A/B test conducted on an auction-based recommender system which handles billions of impressions and users daily, we empirically establish that our proposed method outperforms the current production system in terms of long-term user engagement metrics.
AMOM: Adaptive Masking over Masking for Conditional Masked Language Model
Mar 13, 2023



Transformer-based autoregressive (AR) methods have achieved appealing performance for varied sequence-to-sequence generation tasks, e.g., neural machine translation, summarization, and code generation, but suffer from low inference efficiency. To speed up the inference stage, many non-autoregressive (NAR) strategies have been proposed in the past few years. Among them, the conditional masked language model (CMLM) is one of the most versatile frameworks, as it can support many different sequence generation scenarios and achieve very competitive performance on these tasks. In this paper, we further introduce a simple yet effective adaptive masking over masking strategy to enhance the refinement capability of the decoder and make the encoder optimization easier. Experiments on \textbf{3} different tasks (neural machine translation, summarization, and code generation) with \textbf{15} datasets in total confirm that our proposed simple method achieves significant performance improvement over the strong CMLM model. Surprisingly, our proposed model yields state-of-the-art performance on neural machine translation (\textbf{34.62} BLEU on WMT16 EN$\to$RO, \textbf{34.82} BLEU on WMT16 RO$\to$EN, and \textbf{34.84} BLEU on IWSLT De$\to$En) and even better performance than the \textbf{AR} Transformer on \textbf{7} benchmark datasets with at least \textbf{2.2$\times$} speedup. Our code is available at GitHub.
A Validation Tool for Designing Reinforcement Learning Environments
Dec 10, 2021
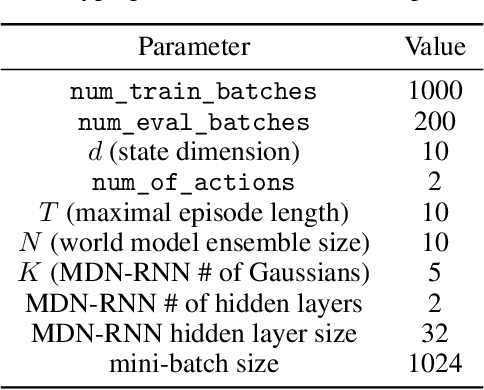
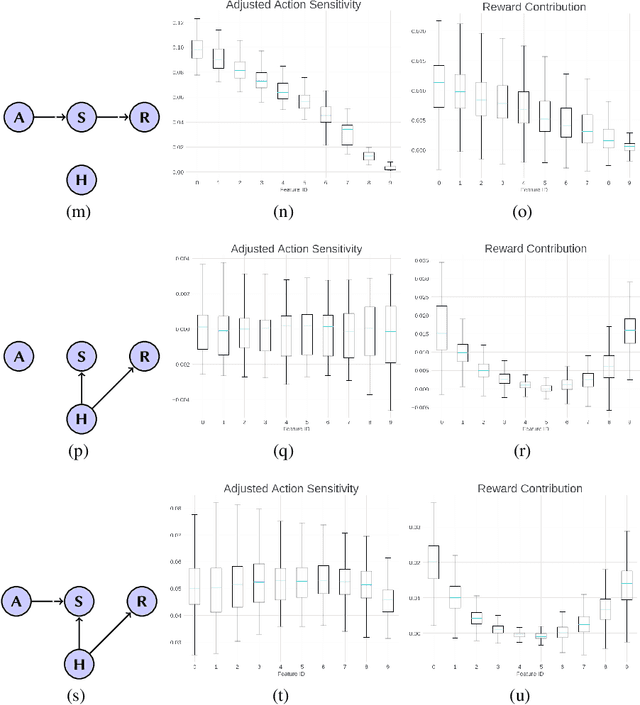
Reinforcement learning (RL) has gained increasing attraction in the academia and tech industry with launches to a variety of impactful applications and products. Although research is being actively conducted on many fronts (e.g., offline RL, performance, etc.), many RL practitioners face a challenge that has been largely ignored: determine whether a designed Markov Decision Process (MDP) is valid and meaningful. This study proposes a heuristic-based feature analysis method to validate whether an MDP is well formulated. We believe an MDP suitable for applying RL should contain a set of state features that are both sensitive to actions and predictive in rewards. We tested our method in constructed environments showing that our approach can identify certain invalid environment formulations. As far as we know, performing validity analysis for RL problem formulation is a novel direction. We envision that our tool will serve as a motivational example to help practitioners apply RL in real-world problems more easily.