 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDual Monte Carlo Tree Search
Mar 21, 2021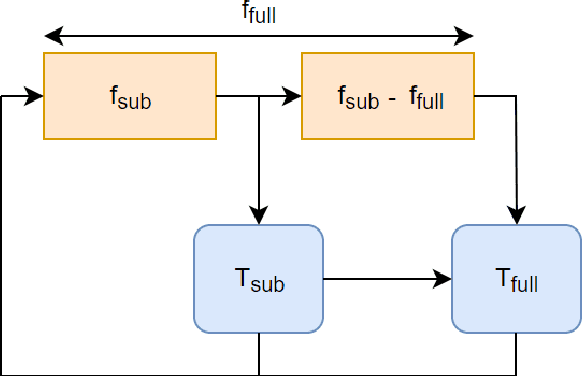

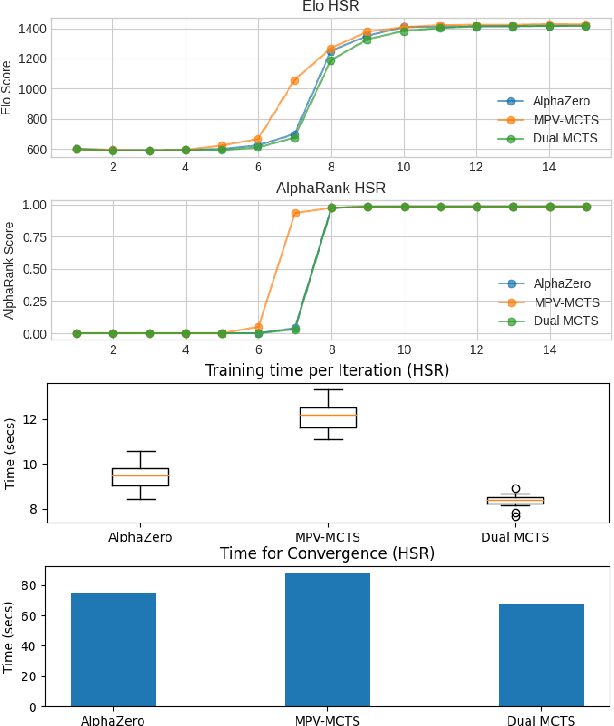

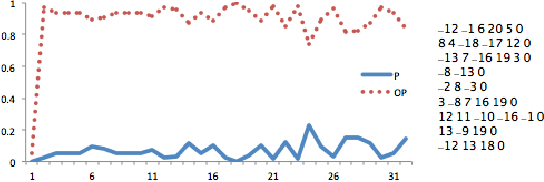
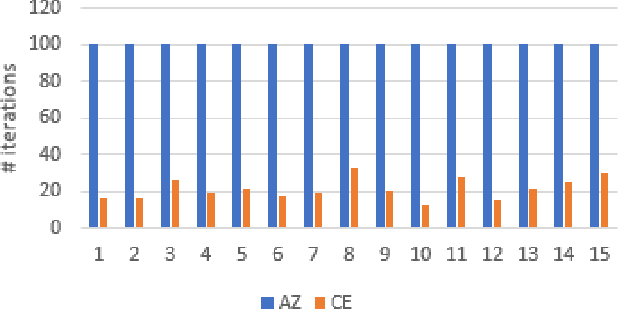
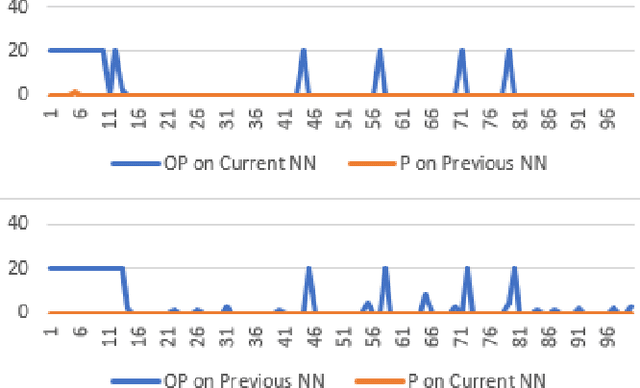
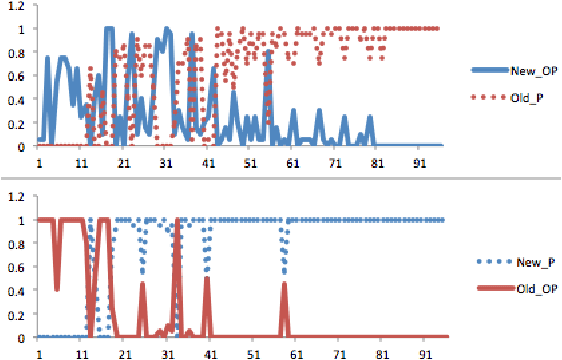
AlphaZero, using a combination of Deep Neural Networks and Monte Carlo Tree Search (MCTS), has successfully trained reinforcement learning agents in a tabula-rasa way. The neural MCTS algorithm has been successful in finding near-optimal strategies for games through self-play. However, the AlphaZero algorithm has a significant drawback; it takes a long time to converge and requires high computational power due to complex neural networks for solving games like Chess, Go, Shogi, etc. Owing to this, it is very difficult to pursue neural MCTS research without cutting-edge hardware, which is a roadblock for many aspiring neural MCTS researchers. In this paper, we propose a new neural MCTS algorithm, called Dual MCTS, which helps overcome these drawbacks. Dual MCTS uses two different search trees, a single deep neural network, and a new update technique for the search trees using a combination of the PUCB, a sliding-window, and the epsilon-greedy algorithm. This technique is applicable to any MCTS based algorithm to reduce the number of updates to the tree. We show that Dual MCTS performs better than one of the most widely used neural MCTS algorithms, AlphaZero, for various symmetric and asymmetric games.
Solving QSAT problems with neural MCTS
Jan 17, 2021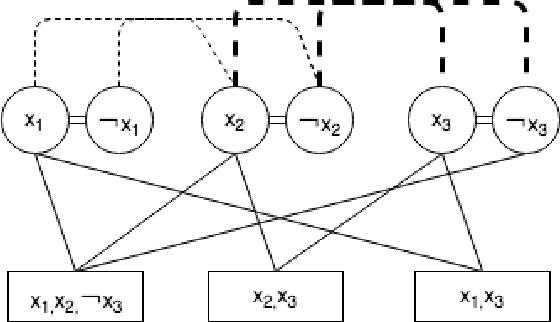
Recent achievements from AlphaZero using self-play has shown remarkable performance on several board games. It is plausible to think that self-play, starting from zero knowledge, can gradually approximate a winning strategy for certain two-player games after an amount of training. In this paper, we try to leverage the computational power of neural Monte Carlo Tree Search (neural MCTS), the core algorithm from AlphaZero, to solve Quantified Boolean Formula Satisfaction (QSAT) problems, which are PSPACE complete. Knowing that every QSAT problem is equivalent to a QSAT game, the game outcome can be used to derive the solutions of the original QSAT problems. We propose a way to encode Quantified Boolean Formulas (QBFs) as graphs and apply a graph neural network (GNN) to embed the QBFs into the neural MCTS. After training, an off-the-shelf QSAT solver is used to evaluate the performance of the algorithm. Our result shows that, for problems within a limited size, the algorithm learns to solve the problem correctly merely from self-play.
First-Order Problem Solving through Neural MCTS based Reinforcement Learning
Jan 11, 2021
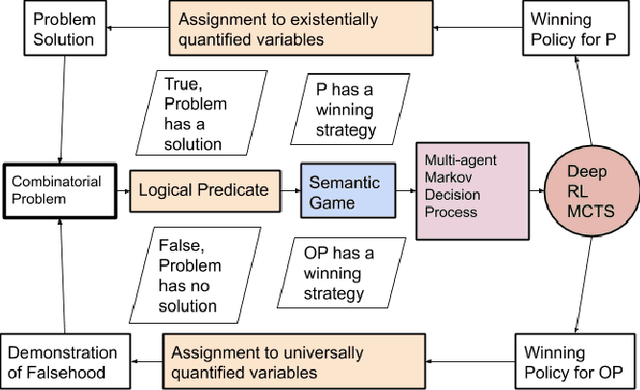
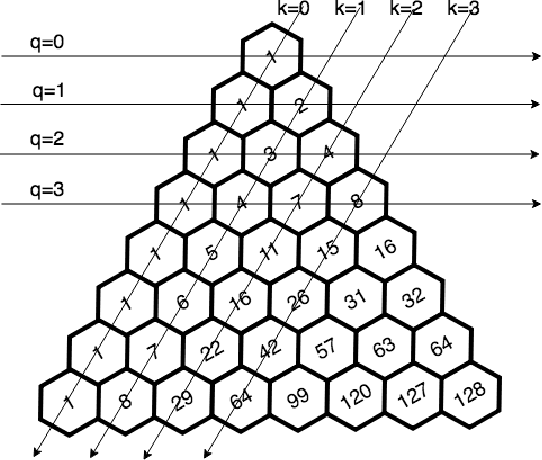
The formal semantics of an interpreted first-order logic (FOL) statement can be given in Tarskian Semantics or a basically equivalent Game Semantics. The latter maps the statement and the interpretation into a two-player semantic game. Many combinatorial problems can be described using interpreted FOL statements and can be mapped into a semantic game. Therefore, learning to play a semantic game perfectly leads to the solution of a specific instance of a combinatorial problem. We adapt the AlphaZero algorithm so that it becomes better at learning to play semantic games that have different characteristics than Go and Chess. We propose a general framework, Persephone, to map the FOL description of a combinatorial problem to a semantic game so that it can be solved through a neural MCTS based reinforcement learning algorithm. Our goal for Persephone is to make it tabula-rasa, mapping a problem stated in interpreted FOL to a solution without human intervention.
Learning Self-Game-Play Agents for Combinatorial Optimization Problems
Mar 08, 2019
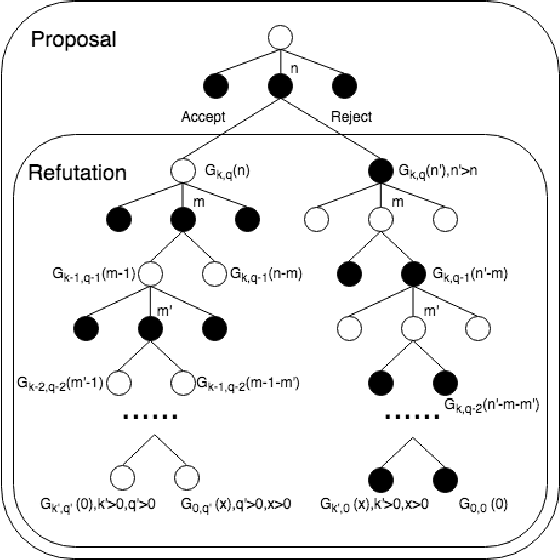
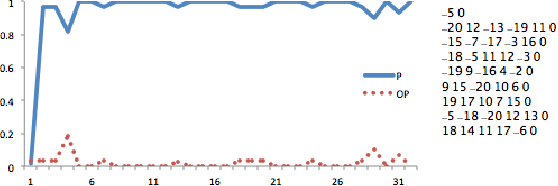
Recent progress in reinforcement learning (RL) using self-game-play has shown remarkable performance on several board games (e.g., Chess and Go) as well as video games (e.g., Atari games and Dota2). It is plausible to consider that RL, starting from zero knowledge, might be able to gradually approximate a winning strategy after a certain amount of training. In this paper, we explore neural Monte-Carlo-Tree-Search (neural MCTS), an RL algorithm which has been applied successfully by DeepMind to play Go and Chess at a super-human level. We try to leverage the computational power of neural MCTS to solve a class of combinatorial optimization problems. Following the idea of Hintikka's Game-Theoretical Semantics, we propose the Zermelo Gamification (ZG) to transform specific combinatorial optimization problems into Zermelo games whose winning strategies correspond to the solutions of the original optimization problem. The ZG also provides a specially designed neural MCTS. We use a combinatorial planning problem for which the ground-truth policy is efficiently computable to demonstrate that ZG is promising.