 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSolving QSAT problems with neural MCTS
Paper and Code
Jan 17, 2021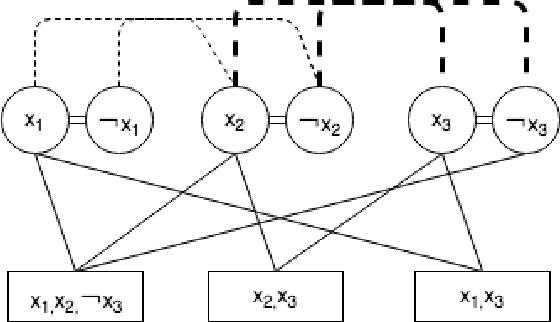
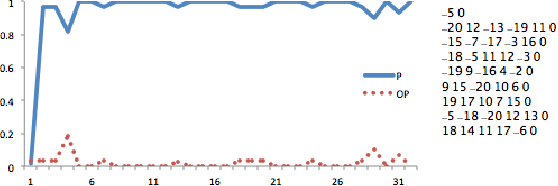
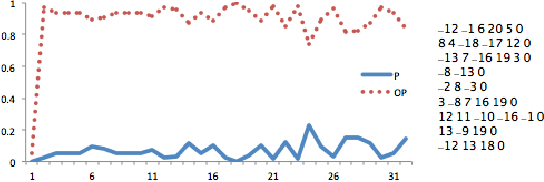
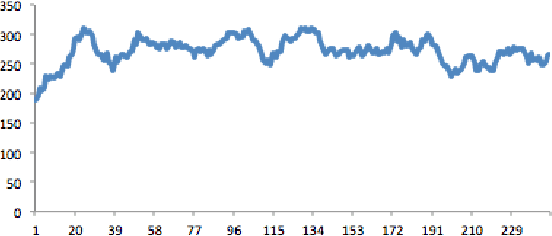
Recent achievements from AlphaZero using self-play has shown remarkable performance on several board games. It is plausible to think that self-play, starting from zero knowledge, can gradually approximate a winning strategy for certain two-player games after an amount of training. In this paper, we try to leverage the computational power of neural Monte Carlo Tree Search (neural MCTS), the core algorithm from AlphaZero, to solve Quantified Boolean Formula Satisfaction (QSAT) problems, which are PSPACE complete. Knowing that every QSAT problem is equivalent to a QSAT game, the game outcome can be used to derive the solutions of the original QSAT problems. We propose a way to encode Quantified Boolean Formulas (QBFs) as graphs and apply a graph neural network (GNN) to embed the QBFs into the neural MCTS. After training, an off-the-shelf QSAT solver is used to evaluate the performance of the algorithm. Our result shows that, for problems within a limited size, the algorithm learns to solve the problem correctly merely from self-play.