 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDual Monte Carlo Tree Search
Paper and Code
Mar 21, 2021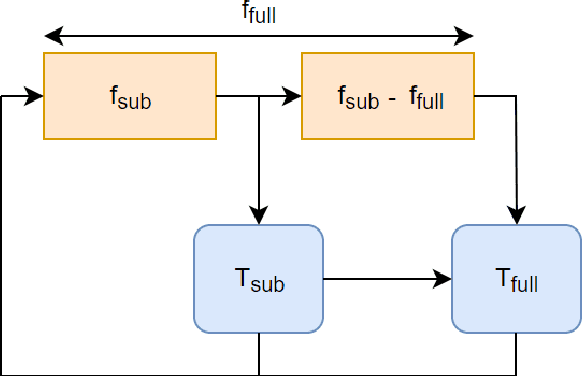

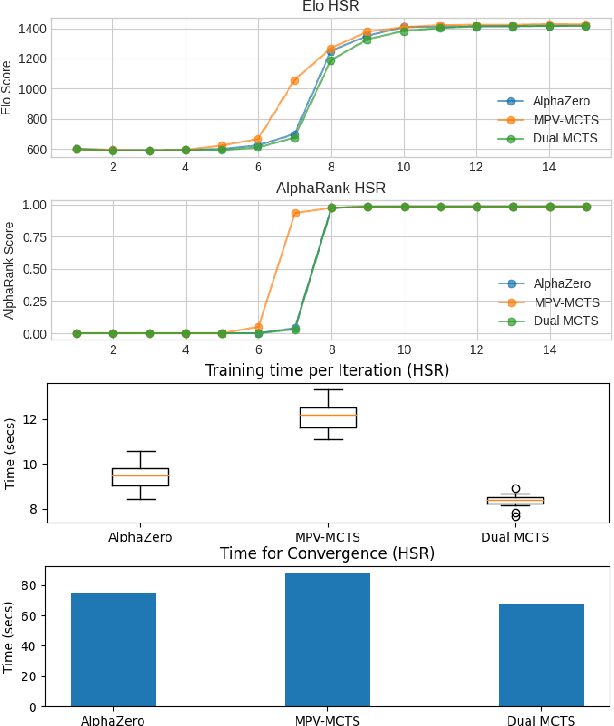

AlphaZero, using a combination of Deep Neural Networks and Monte Carlo Tree Search (MCTS), has successfully trained reinforcement learning agents in a tabula-rasa way. The neural MCTS algorithm has been successful in finding near-optimal strategies for games through self-play. However, the AlphaZero algorithm has a significant drawback; it takes a long time to converge and requires high computational power due to complex neural networks for solving games like Chess, Go, Shogi, etc. Owing to this, it is very difficult to pursue neural MCTS research without cutting-edge hardware, which is a roadblock for many aspiring neural MCTS researchers. In this paper, we propose a new neural MCTS algorithm, called Dual MCTS, which helps overcome these drawbacks. Dual MCTS uses two different search trees, a single deep neural network, and a new update technique for the search trees using a combination of the PUCB, a sliding-window, and the epsilon-greedy algorithm. This technique is applicable to any MCTS based algorithm to reduce the number of updates to the tree. We show that Dual MCTS performs better than one of the most widely used neural MCTS algorithms, AlphaZero, for various symmetric and asymmetric games.