 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCredit Assignment with Resets in Language Model Reasoning
May 26, 2026Contemporary reinforcement learning with verifiable reward methods post-train language models on multi-step reasoning by assigning a single outcome reward uniformly across all tokens in a trajectory. Such uniform assignment ignores which steps contributed to success or failure. Improving credit assignment can address this limitation by enabling targeted refinement of faulty reasoning steps, rather than updating entire trajectories uniformly. Resets are one such simple mechanism, enabling more precise credit assignment by returning to an intermediate state and resampling counterfactual continuations, so that outcome differences can be attributed to decisions made at that point. We propose two such methods: Random-Reset Policy Optimization (RRPO), where reset states are drawn randomly from reasoning steps, and Self-Reset Policy Optimization (SRPO), where the model self-localizes the erroneous step in an incorrect trajectory and resets there. We analyze these methods within the Conservative Policy Iteration (CPI) framework. Extending CPI with a credit-assignment oracle that targets improvable states yields provable improvements over random resets. Across models and reasoning benchmarks, SRPO consistently outperforms standard GRPO and RRPO by sampling multiple suffix continuations at a self-localized reset and learning from their rewards, using only the model itself with no external supervision.
Structure Enables Effective Self-Localization of Errors in LLMs
Feb 02, 2026Self-correction in language models remains elusive. In this work, we explore whether language models can explicitly localize errors in incorrect reasoning, as a path toward building AI systems that can effectively correct themselves. We introduce a prompting method that structures reasoning as discrete, semantically coherent thought steps, and show that models are able to reliably localize errors within this structure, while failing to do so in conventional, unstructured chain-of-thought reasoning. Motivated by how the human brain monitors errors at discrete decision points and resamples alternatives, we introduce Iterative Correction Sampling of Thoughts (Thought-ICS), a self-correction framework. Thought-ICS iteratively prompts the model to generate reasoning one discrete and complete thought at a time--where each thought represents a deliberate decision by the model--creating natural boundaries for precise error localization. Upon verification, the model localizes the first erroneous step, and the system backtracks to generate alternative reasoning from the last correct point. When asked to correct reasoning verified as incorrect by an oracle, Thought-ICS achieves 20-40% self-correction lift. In a completely autonomous setting without external verification, it outperforms contemporary self-correction baselines.
Aligned Multi Objective Optimization
Feb 19, 2025To date, the multi-objective optimization literature has mainly focused on conflicting objectives, studying the Pareto front, or requiring users to balance tradeoffs. Yet, in machine learning practice, there are many scenarios where such conflict does not take place. Recent findings from multi-task learning, reinforcement learning, and LLMs training show that diverse related tasks can enhance performance across objectives simultaneously. Despite this evidence, such phenomenon has not been examined from an optimization perspective. This leads to a lack of generic gradient-based methods that can scale to scenarios with a large number of related objectives. To address this gap, we introduce the Aligned Multi-Objective Optimization framework, propose new algorithms for this setting, and provide theoretical guarantees of their superior performance compared to naive approaches.
Pearl: A Production-ready Reinforcement Learning Agent
Dec 06, 2023



Reinforcement Learning (RL) offers a versatile framework for achieving long-term goals. Its generality allows us to formalize a wide range of problems that real-world intelligent systems encounter, such as dealing with delayed rewards, handling partial observability, addressing the exploration and exploitation dilemma, utilizing offline data to improve online performance, and ensuring safety constraints are met. Despite considerable progress made by the RL research community in addressing these issues, existing open-source RL libraries tend to focus on a narrow portion of the RL solution pipeline, leaving other aspects largely unattended. This paper introduces Pearl, a Production-ready RL agent software package explicitly designed to embrace these challenges in a modular fashion. In addition to presenting preliminary benchmark results, this paper highlights Pearl's industry adoptions to demonstrate its readiness for production usage. Pearl is open sourced on Github at github.com/facebookresearch/pearl and its official website is located at pearlagent.github.io.
Optimizing Long-term Value for Auction-Based Recommender Systems via On-Policy Reinforcement Learning
May 24, 2023Auction-based recommender systems are prevalent in online advertising platforms, but they are typically optimized to allocate recommendation slots based on immediate expected return metrics, neglecting the downstream effects of recommendations on user behavior. In this study, we employ reinforcement learning to optimize for long-term return metrics in an auction-based recommender system. Utilizing temporal difference learning, a fundamental reinforcement learning algorithm, we implement an one-step policy improvement approach that biases the system towards recommendations with higher long-term user engagement metrics. This optimizes value over long horizons while maintaining compatibility with the auction framework. Our approach is grounded in dynamic programming ideas which show that our method provably improves upon the existing auction-based base policy. Through an online A/B test conducted on an auction-based recommender system which handles billions of impressions and users daily, we empirically establish that our proposed method outperforms the current production system in terms of long-term user engagement metrics.
A Note on the Linear Convergence of Policy Gradient Methods
Jul 21, 2020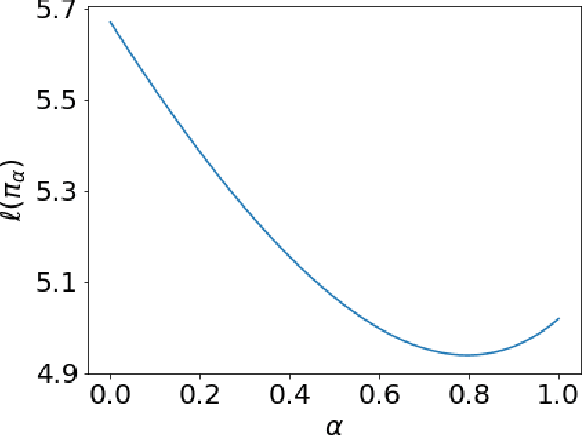
We revisit the finite time analysis of policy gradient methods in the simplest setting: finite state and action problems with a policy class consisting of all stochastic policies and with exact gradient evaluations. Some recent works have viewed these problems as instances of smooth nonlinear optimization problems, suggesting suggest small stepsizes and showing sublinear convergence rates. This note instead takes a policy iteration perspective and highlights that many versions of policy gradient succeed with extremely large stepsizes and attain a linear rate of convergence.
Global Optimality Guarantees For Policy Gradient Methods
Jun 05, 2019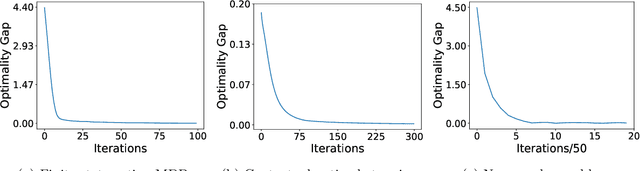
Policy gradients methods are perhaps the most widely used class of reinforcement learning algorithms. These methods apply to complex, poorly understood, control problems by performing stochastic gradient descent over a parameterized class of polices. Unfortunately, even for simple control problems solvable by classical techniques, policy gradient algorithms face non-convex optimization problems and are widely understood to converge only to local minima. This work identifies structural properties -- shared by finite MDPs and several classic control problems -- which guarantee that policy gradient objective function has no suboptimal local minima despite being non-convex. When these assumptions are relaxed, our work gives conditions under which any local minimum is near-optimal, where the error bound depends on a notion of the expressive capacity of the policy class.
A Finite Time Analysis of Temporal Difference Learning With Linear Function Approximation
Nov 06, 2018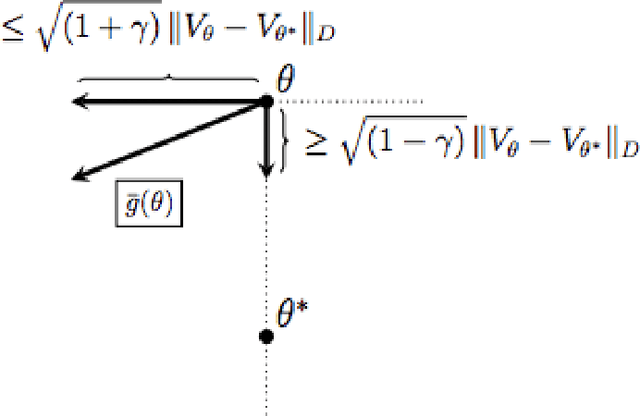
Temporal difference learning (TD) is a simple iterative algorithm used to estimate the value function corresponding to a given policy in a Markov decision process. Although TD is one of the most widely used algorithms in reinforcement learning, its theoretical analysis has proved challenging and few guarantees on its statistical efficiency are available. In this work, we provide a simple and explicit finite time analysis of temporal difference learning with linear function approximation. Except for a few key insights, our analysis mirrors standard techniques for analyzing stochastic gradient descent algorithms, and therefore inherits the simplicity and elegance of that literature. Final sections of the paper show how all of our main results extend to the study of TD learning with eligibility traces, known as TD($\lambda$), and to Q-learning applied in high-dimensional optimal stopping problems.