Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Note on the Linear Convergence of Policy Gradient Methods
Paper and Code
Jul 21, 2020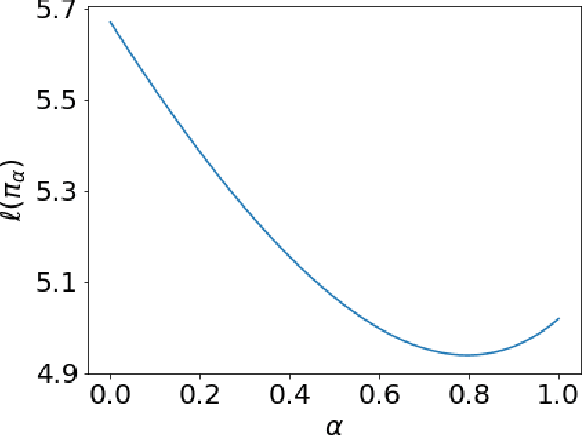
We revisit the finite time analysis of policy gradient methods in the simplest setting: finite state and action problems with a policy class consisting of all stochastic policies and with exact gradient evaluations. Some recent works have viewed these problems as instances of smooth nonlinear optimization problems, suggesting suggest small stepsizes and showing sublinear convergence rates. This note instead takes a policy iteration perspective and highlights that many versions of policy gradient succeed with extremely large stepsizes and attain a linear rate of convergence.
View paper on