 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGlobal Optimality Guarantees For Policy Gradient Methods
Paper and Code
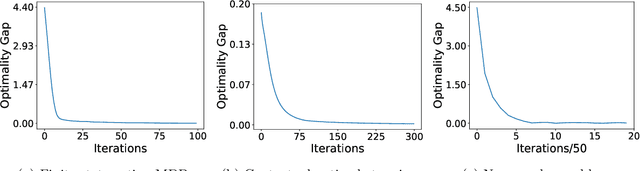
Policy gradients methods are perhaps the most widely used class of reinforcement learning algorithms. These methods apply to complex, poorly understood, control problems by performing stochastic gradient descent over a parameterized class of polices. Unfortunately, even for simple control problems solvable by classical techniques, policy gradient algorithms face non-convex optimization problems and are widely understood to converge only to local minima. This work identifies structural properties -- shared by finite MDPs and several classic control problems -- which guarantee that policy gradient objective function has no suboptimal local minima despite being non-convex. When these assumptions are relaxed, our work gives conditions under which any local minimum is near-optimal, where the error bound depends on a notion of the expressive capacity of the policy class.