 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCredit Assignment with Resets in Language Model Reasoning
May 26, 2026Contemporary reinforcement learning with verifiable reward methods post-train language models on multi-step reasoning by assigning a single outcome reward uniformly across all tokens in a trajectory. Such uniform assignment ignores which steps contributed to success or failure. Improving credit assignment can address this limitation by enabling targeted refinement of faulty reasoning steps, rather than updating entire trajectories uniformly. Resets are one such simple mechanism, enabling more precise credit assignment by returning to an intermediate state and resampling counterfactual continuations, so that outcome differences can be attributed to decisions made at that point. We propose two such methods: Random-Reset Policy Optimization (RRPO), where reset states are drawn randomly from reasoning steps, and Self-Reset Policy Optimization (SRPO), where the model self-localizes the erroneous step in an incorrect trajectory and resets there. We analyze these methods within the Conservative Policy Iteration (CPI) framework. Extending CPI with a credit-assignment oracle that targets improvable states yields provable improvements over random resets. Across models and reasoning benchmarks, SRPO consistently outperforms standard GRPO and RRPO by sampling multiple suffix continuations at a self-localized reset and learning from their rewards, using only the model itself with no external supervision.
Structure Enables Effective Self-Localization of Errors in LLMs
Feb 02, 2026Self-correction in language models remains elusive. In this work, we explore whether language models can explicitly localize errors in incorrect reasoning, as a path toward building AI systems that can effectively correct themselves. We introduce a prompting method that structures reasoning as discrete, semantically coherent thought steps, and show that models are able to reliably localize errors within this structure, while failing to do so in conventional, unstructured chain-of-thought reasoning. Motivated by how the human brain monitors errors at discrete decision points and resamples alternatives, we introduce Iterative Correction Sampling of Thoughts (Thought-ICS), a self-correction framework. Thought-ICS iteratively prompts the model to generate reasoning one discrete and complete thought at a time--where each thought represents a deliberate decision by the model--creating natural boundaries for precise error localization. Upon verification, the model localizes the first erroneous step, and the system backtracks to generate alternative reasoning from the last correct point. When asked to correct reasoning verified as incorrect by an oracle, Thought-ICS achieves 20-40% self-correction lift. In a completely autonomous setting without external verification, it outperforms contemporary self-correction baselines.
Locomotion Beyond Feet
Jan 07, 2026Most locomotion methods for humanoid robots focus on leg-based gaits, yet natural bipeds frequently rely on hands, knees, and elbows to establish additional contacts for stability and support in complex environments. This paper introduces Locomotion Beyond Feet, a comprehensive system for whole-body humanoid locomotion across extremely challenging terrains, including low-clearance spaces under chairs, knee-high walls, knee-high platforms, and steep ascending and descending stairs. Our approach addresses two key challenges: contact-rich motion planning and generalization across diverse terrains. To this end, we combine physics-grounded keyframe animation with reinforcement learning. Keyframes encode human knowledge of motor skills, are embodiment-specific, and can be readily validated in simulation or on hardware, while reinforcement learning transforms these references into robust, physically accurate motions. We further employ a hierarchical framework consisting of terrain-specific motion-tracking policies, failure recovery mechanisms, and a vision-based skill planner. Real-world experiments demonstrate that Locomotion Beyond Feet achieves robust whole-body locomotion and generalizes across obstacle sizes, obstacle instances, and terrain sequences.
Internalizing Self-Consistency in Language Models: Multi-Agent Consensus Alignment
Sep 18, 2025



Language Models (LMs) are inconsistent reasoners, often generating contradictory responses to identical prompts. While inference-time methods can mitigate these inconsistencies, they fail to address the core problem: LMs struggle to reliably select reasoning pathways leading to consistent outcomes under exploratory sampling. To address this, we formalize self-consistency as an intrinsic property of well-aligned reasoning models and introduce Multi-Agent Consensus Alignment (MACA), a reinforcement learning framework that post-trains models to favor reasoning trajectories aligned with their internal consensus using majority/minority outcomes from multi-agent debate. These trajectories emerge from deliberative exchanges where agents ground reasoning in peer arguments, not just aggregation of independent attempts, creating richer consensus signals than single-round majority voting. MACA enables agents to teach themselves to be more decisive and concise, and better leverage peer insights in multi-agent settings without external supervision, driving substantial improvements across self-consistency (+27.6% on GSM8K), single-agent reasoning (+23.7% on MATH), sampling-based inference (+22.4% Pass@20 on MATH), and multi-agent ensemble decision-making (+42.7% on MathQA). These findings, coupled with strong generalization to unseen benchmarks (+16.3% on GPQA, +11.6% on CommonsenseQA), demonstrate robust self-alignment that more reliably unlocks latent reasoning potential of language models.
Carbon Aware Transformers Through Joint Model-Hardware Optimization
May 02, 2025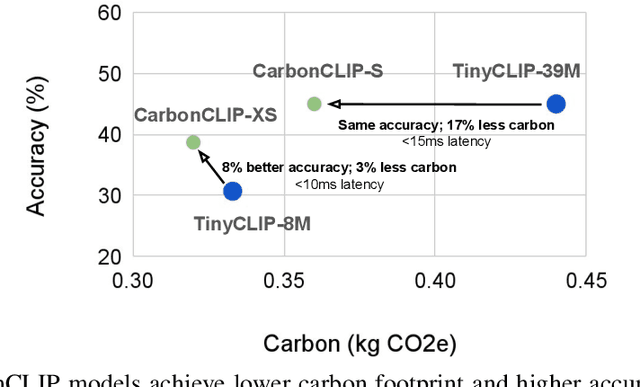
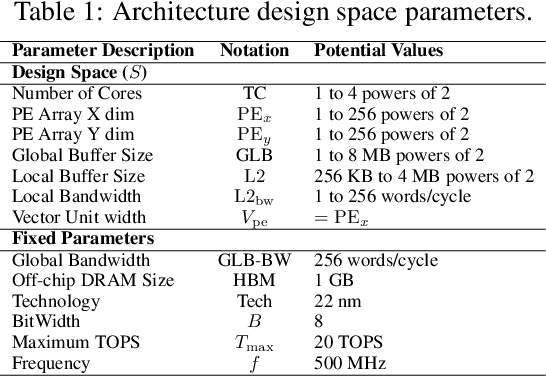
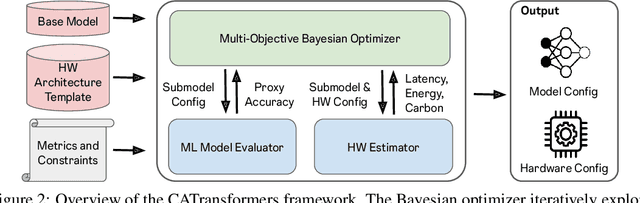
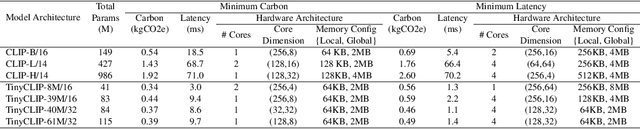
The rapid growth of machine learning (ML) systems necessitates a more comprehensive evaluation of their environmental impact, particularly their carbon footprint, which comprises operational carbon from training and inference execution and embodied carbon from hardware manufacturing and its entire life-cycle. Despite the increasing importance of embodied emissions, there is a lack of tools and frameworks to holistically quantify and optimize the total carbon footprint of ML systems. To address this, we propose CATransformers, a carbon-aware architecture search framework that enables sustainability-driven co-optimization of ML models and hardware architectures. By incorporating both operational and embodied carbon metrics into early design space exploration of domain-specific hardware accelerators, CATransformers demonstrates that optimizing for carbon yields design choices distinct from those optimized solely for latency or energy efficiency. We apply our framework to multi-modal CLIP-based models, producing CarbonCLIP, a family of CLIP models achieving up to 17% reduction in total carbon emissions while maintaining accuracy and latency compared to state-of-the-art edge small CLIP baselines. This work underscores the need for holistic optimization methods to design high-performance, environmentally sustainable AI systems.
Towards Understanding Camera Motions in Any Video
Apr 21, 2025
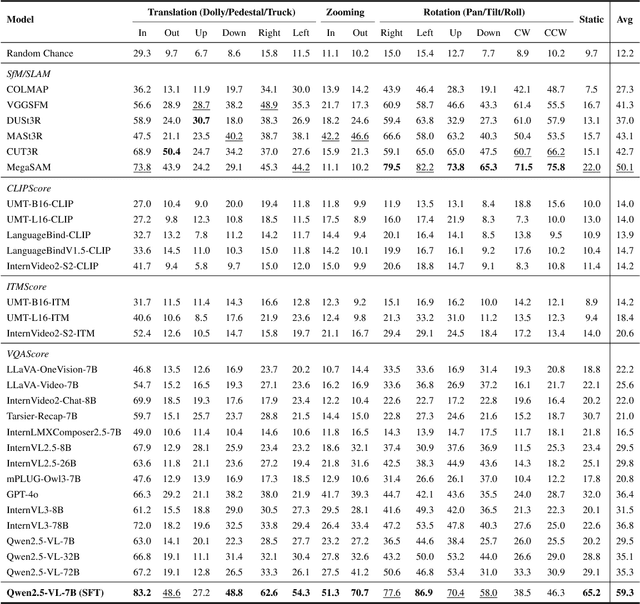
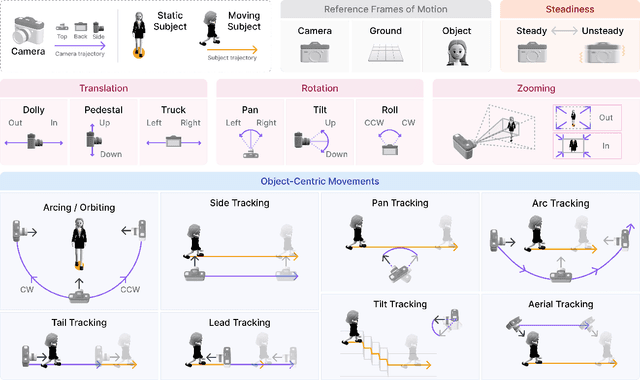
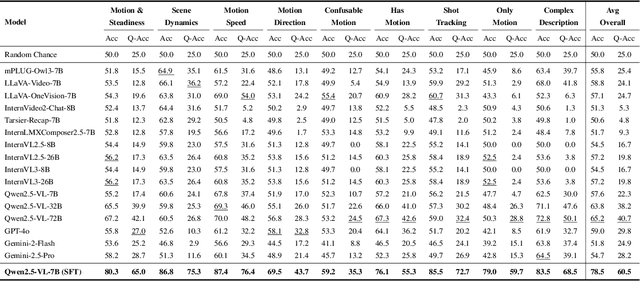
We introduce CameraBench, a large-scale dataset and benchmark designed to assess and improve camera motion understanding. CameraBench consists of ~3,000 diverse internet videos, annotated by experts through a rigorous multi-stage quality control process. One of our contributions is a taxonomy of camera motion primitives, designed in collaboration with cinematographers. We find, for example, that some motions like "follow" (or tracking) require understanding scene content like moving subjects. We conduct a large-scale human study to quantify human annotation performance, revealing that domain expertise and tutorial-based training can significantly enhance accuracy. For example, a novice may confuse zoom-in (a change of intrinsics) with translating forward (a change of extrinsics), but can be trained to differentiate the two. Using CameraBench, we evaluate Structure-from-Motion (SfM) and Video-Language Models (VLMs), finding that SfM models struggle to capture semantic primitives that depend on scene content, while VLMs struggle to capture geometric primitives that require precise estimation of trajectories. We then fine-tune a generative VLM on CameraBench to achieve the best of both worlds and showcase its applications, including motion-augmented captioning, video question answering, and video-text retrieval. We hope our taxonomy, benchmark, and tutorials will drive future efforts towards the ultimate goal of understanding camera motions in any video.
Aligned Multi Objective Optimization
Feb 19, 2025To date, the multi-objective optimization literature has mainly focused on conflicting objectives, studying the Pareto front, or requiring users to balance tradeoffs. Yet, in machine learning practice, there are many scenarios where such conflict does not take place. Recent findings from multi-task learning, reinforcement learning, and LLMs training show that diverse related tasks can enhance performance across objectives simultaneously. Despite this evidence, such phenomenon has not been examined from an optimization perspective. This leads to a lack of generic gradient-based methods that can scale to scenarios with a large number of related objectives. To address this gap, we introduce the Aligned Multi-Objective Optimization framework, propose new algorithms for this setting, and provide theoretical guarantees of their superior performance compared to naive approaches.
On the Linear Speedup of Personalized Federated Reinforcement Learning with Shared Representations
Nov 22, 2024Federated reinforcement learning (FedRL) enables multiple agents to collaboratively learn a policy without sharing their local trajectories collected during agent-environment interactions. However, in practice, the environments faced by different agents are often heterogeneous, leading to poor performance by the single policy learned by existing FedRL algorithms on individual agents. In this paper, we take a further step and introduce a \emph{personalized} FedRL framework (PFedRL) by taking advantage of possibly shared common structure among agents in heterogeneous environments. Specifically, we develop a class of PFedRL algorithms named PFedRL-Rep that learns (1) a shared feature representation collaboratively among all agents, and (2) an agent-specific weight vector personalized to its local environment. We analyze the convergence of PFedTD-Rep, a particular instance of the framework with temporal difference (TD) learning and linear representations. To the best of our knowledge, we are the first to prove a linear convergence speedup with respect to the number of agents in the PFedRL setting. To achieve this, we show that PFedTD-Rep is an example of the federated two-timescale stochastic approximation with Markovian noise. Experimental results demonstrate that PFedTD-Rep, along with an extension to the control setting based on deep Q-networks (DQN), not only improve learning in heterogeneous settings, but also provide better generalization to new environments.
NaturalBench: Evaluating Vision-Language Models on Natural Adversarial Samples
Oct 18, 2024
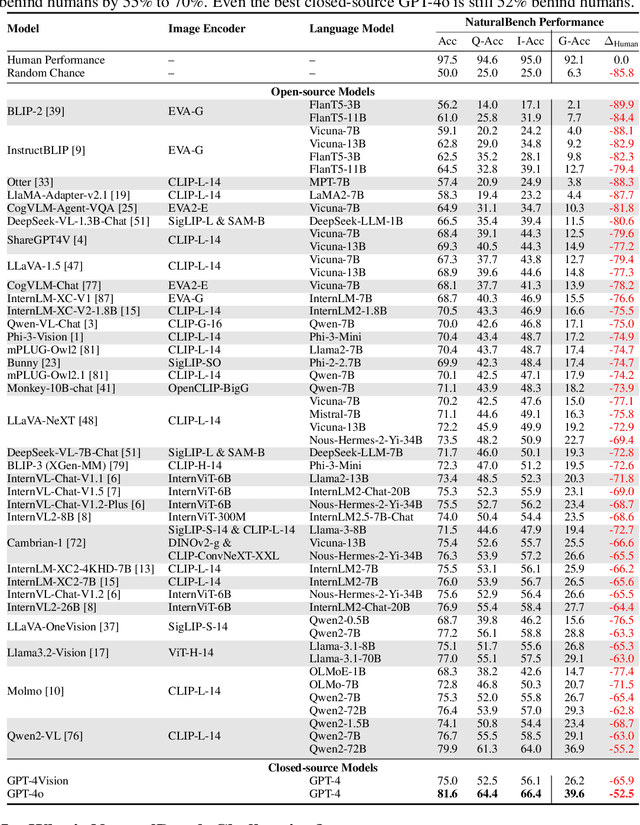

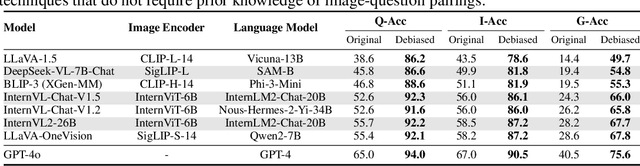
Vision-language models (VLMs) have made significant progress in recent visual-question-answering (VQA) benchmarks that evaluate complex visio-linguistic reasoning. However, are these models truly effective? In this work, we show that VLMs still struggle with natural images and questions that humans can easily answer, which we term natural adversarial samples. We also find it surprisingly easy to generate these VQA samples from natural image-text corpora using off-the-shelf models like CLIP and ChatGPT. We propose a semi-automated approach to collect a new benchmark, NaturalBench, for reliably evaluating VLMs with 10,000 human-verified VQA samples. Crucially, we adopt a $\textbf{vision-centric}$ design by pairing each question with two images that yield different answers, preventing blind solutions from answering without using the images. This makes NaturalBench more challenging than previous benchmarks that can be solved with commonsense priors. We evaluate 53 state-of-the-art VLMs on NaturalBench, showing that models like LLaVA-OneVision, Cambrian-1, Llama3.2-Vision, Molmo, Qwen2-VL, and even GPT-4o lag 50%-70% behind human performance (over 90%). We analyze why NaturalBench is hard from two angles: (1) Compositionality: Solving NaturalBench requires diverse visio-linguistic skills, including understanding attribute bindings, object relationships, and advanced reasoning like logic and counting. To this end, unlike prior work that uses a single tag per sample, we tag each NaturalBench sample with 1 to 8 skill tags for fine-grained evaluation. (2) Biases: NaturalBench exposes severe biases in VLMs, as models often choose the same answer regardless of the image. Lastly, we apply our benchmark curation method to diverse data sources, including long captions (over 100 words) and non-English languages like Chinese and Hindi, highlighting its potential for dynamic evaluations of VLMs.
Pearl: A Production-ready Reinforcement Learning Agent
Dec 06, 2023



Reinforcement Learning (RL) offers a versatile framework for achieving long-term goals. Its generality allows us to formalize a wide range of problems that real-world intelligent systems encounter, such as dealing with delayed rewards, handling partial observability, addressing the exploration and exploitation dilemma, utilizing offline data to improve online performance, and ensuring safety constraints are met. Despite considerable progress made by the RL research community in addressing these issues, existing open-source RL libraries tend to focus on a narrow portion of the RL solution pipeline, leaving other aspects largely unattended. This paper introduces Pearl, a Production-ready RL agent software package explicitly designed to embrace these challenges in a modular fashion. In addition to presenting preliminary benchmark results, this paper highlights Pearl's industry adoptions to demonstrate its readiness for production usage. Pearl is open sourced on Github at github.com/facebookresearch/pearl and its official website is located at pearlagent.github.io.