 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePractical Policy Optimization with Personalized Experimentation
Mar 30, 2023

Many organizations measure treatment effects via an experimentation platform to evaluate the casual effect of product variations prior to full-scale deployment. However, standard experimentation platforms do not perform optimally for end user populations that exhibit heterogeneous treatment effects (HTEs). Here we present a personalized experimentation framework, Personalized Experiments (PEX), which optimizes treatment group assignment at the user level via HTE modeling and sequential decision policy optimization to optimize multiple short-term and long-term outcomes simultaneously. We describe an end-to-end workflow that has proven to be successful in practice and can be readily implemented using open-source software.
Looper: An end-to-end ML platform for product decisions
Nov 10, 2021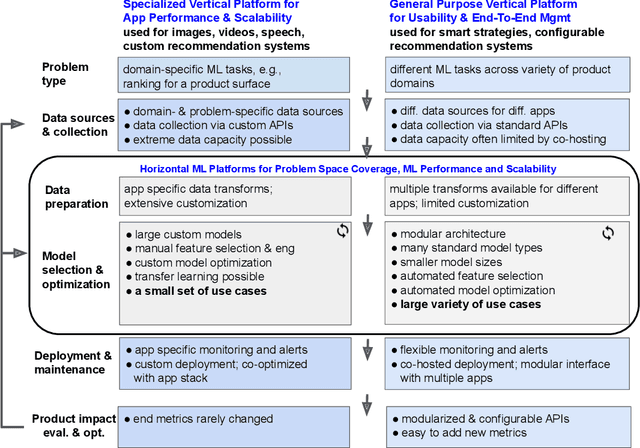
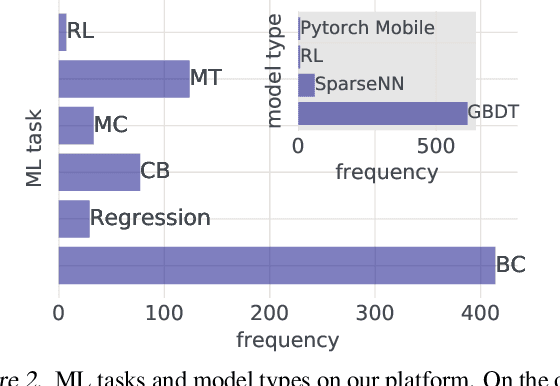
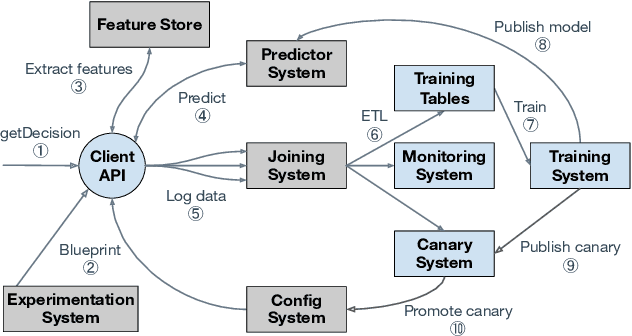
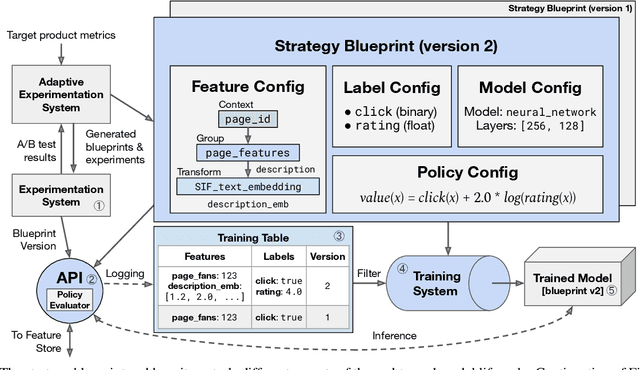
Modern software systems and products increasingly rely on machine learning models to make data-driven decisions based on interactions with users and systems, e.g., compute infrastructure. For broader adoption, this practice must (i) accommodate software engineers without ML backgrounds, and (ii) provide mechanisms to optimize for product goals. In this work, we describe general principles and a specific end-to-end ML platform, Looper, which offers easy-to-use APIs for decision-making and feedback collection. Looper supports the full end-to-end ML lifecycle from online data collection to model training, deployment, inference, and extends support to evaluation and tuning against product goals. We outline the platform architecture and overall impact of production deployment -- Looper currently hosts 700 ML models and makes 6 million decisions per second. We also describe the learning curve and summarize experiences of platform adopters.
Distilling Heterogeneity: From Explanations of Heterogeneous Treatment Effect Models to Interpretable Policies
Nov 05, 2021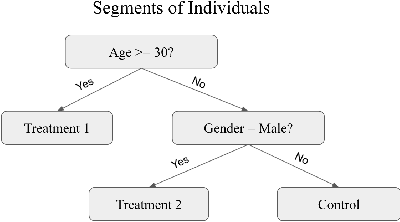
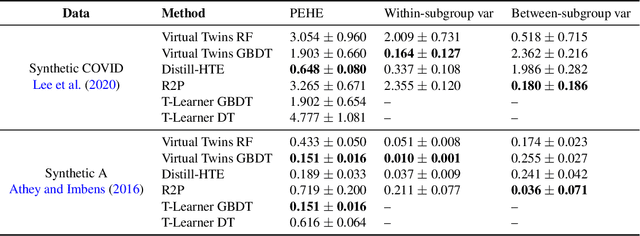
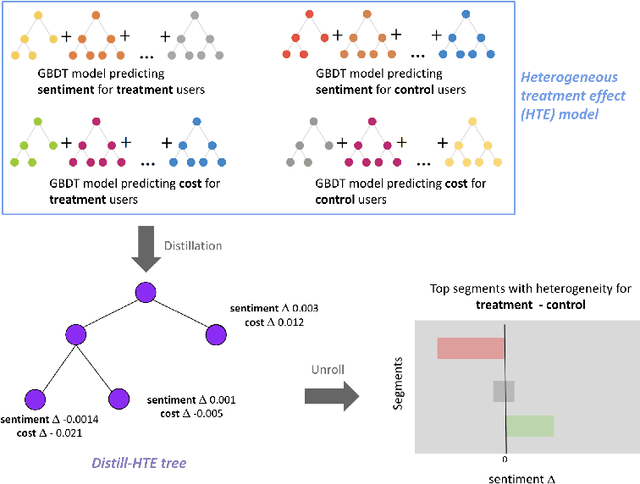
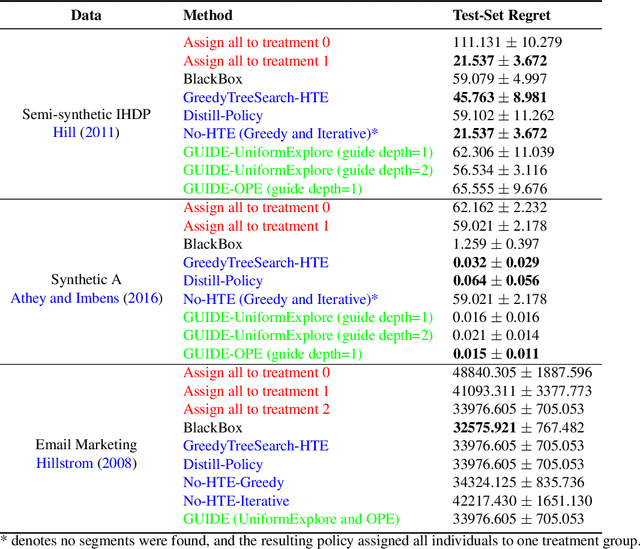
Internet companies are increasingly using machine learning models to create personalized policies which assign, for each individual, the best predicted treatment for that individual. They are frequently derived from black-box heterogeneous treatment effect (HTE) models that predict individual-level treatment effects. In this paper, we focus on (1) learning explanations for HTE models; (2) learning interpretable policies that prescribe treatment assignments. We also propose guidance trees, an approach to ensemble multiple interpretable policies without the loss of interpretability. These rule-based interpretable policies are easy to deploy and avoid the need to maintain a HTE model in a production environment.