 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevolution or Hype? Seeking the Limits of Large Models in Hardware Design
Sep 05, 2025Recent breakthroughs in Large Language Models (LLMs) and Large Circuit Models (LCMs) have sparked excitement across the electronic design automation (EDA) community, promising a revolution in circuit design and optimization. Yet, this excitement is met with significant skepticism: Are these AI models a genuine revolution in circuit design, or a temporary wave of inflated expectations? This paper serves as a foundational text for the corresponding ICCAD 2025 panel, bringing together perspectives from leading experts in academia and industry. It critically examines the practical capabilities, fundamental limitations, and future prospects of large AI models in hardware design. The paper synthesizes the core arguments surrounding reliability, scalability, and interpretability, framing the debate on whether these models can meaningfully outperform or complement traditional EDA methods. The result is an authoritative overview offering fresh insights into one of today's most contentious and impactful technology trends.
The False Dawn: Reevaluating Google's Reinforcement Learning for Chip Macro Placement
Jun 28, 2023Reinforcement learning (RL) for physical design of silicon chips in a Google 2021 Nature paper stirred controversy due to poorly documented claims that raised eyebrows and attracted critical media coverage. The Nature paper withheld most inputs needed to produce reported results and some critical steps in the methodology. But two separate evaluations filled in the gaps and demonstrated that Google RL lags behind human designers, behind a well-known algorithm (Simulated Annealing), and also behind generally-available commercial software. Crosschecked data indicate that the integrity of the Nature paper is substantially undermined owing to errors in the conduct, analysis and reporting.
Scalable End-to-End ML Platforms: from AutoML to Self-serve
Mar 04, 2023


ML platforms help enable intelligent data-driven applications and maintain them with limited engineering effort. Upon sufficiently broad adoption, such platforms reach economies of scale that bring greater component reuse while improving efficiency of system development and maintenance. For an end-to-end ML platform with broad adoption, scaling relies on pervasive ML automation and system integration to reach the quality we term self-serve that we define with ten requirements and six optional capabilities. With this in mind, we identify long-term goals for platform development, discuss related tradeoffs and future work. Our reasoning is illustrated on two commercially-deployed end-to-end ML platforms that host hundreds of real-time use cases -- one general-purpose and one specialized.
Practical Knowledge Distillation: Using DNNs to Beat DNNs
Mar 01, 2023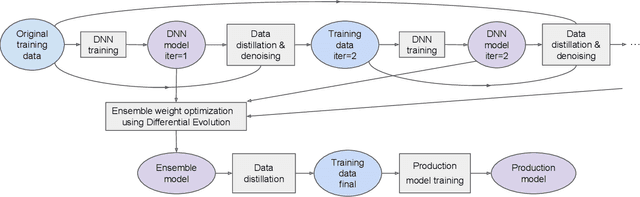
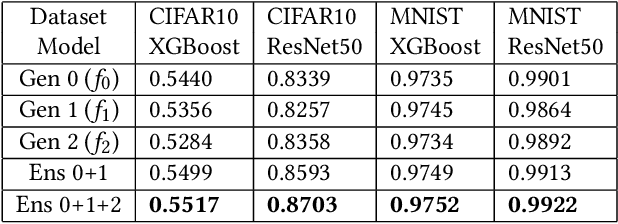
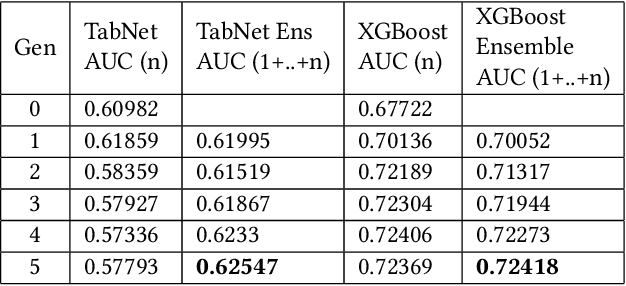

For tabular data sets, we explore data and model distillation, as well as data denoising. These techniques improve both gradient-boosting models and a specialized DNN architecture. While gradient boosting is known to outperform DNNs on tabular data, we close the gap for datasets with 100K+ rows and give DNNs an advantage on small data sets. We extend these results with input-data distillation and optimized ensembling to help DNN performance match or exceed that of gradient boosting. As a theoretical justification of our practical method, we prove its equivalence to classical cross-entropy knowledge distillation. We also qualitatively explain the superiority of DNN ensembles over XGBoost on small data sets. For an industry end-to-end real-time ML platform with 4M production inferences per second, we develop a model-training workflow based on data sampling that distills ensembles of models into a single gradient-boosting model favored for high-performance real-time inference, without performance loss. Empirical evaluation shows that the proposed combination of methods consistently improves model accuracy over prior best models across several production applications deployed worldwide.
Looper: An end-to-end ML platform for product decisions
Nov 10, 2021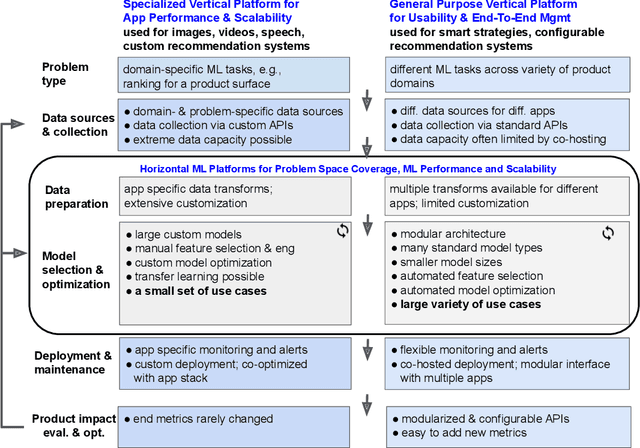
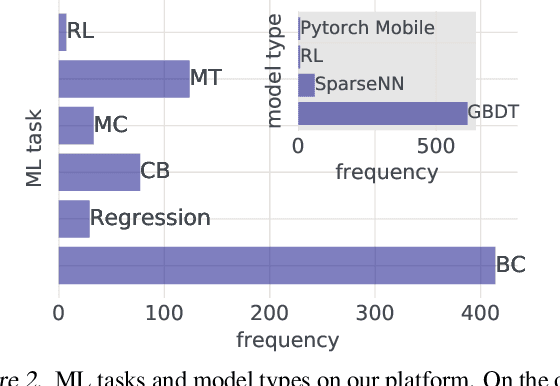
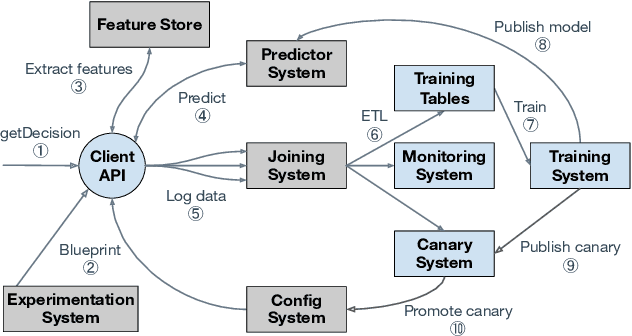
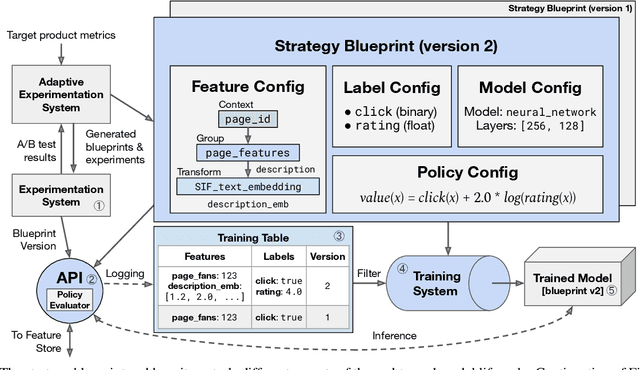
Modern software systems and products increasingly rely on machine learning models to make data-driven decisions based on interactions with users and systems, e.g., compute infrastructure. For broader adoption, this practice must (i) accommodate software engineers without ML backgrounds, and (ii) provide mechanisms to optimize for product goals. In this work, we describe general principles and a specific end-to-end ML platform, Looper, which offers easy-to-use APIs for decision-making and feedback collection. Looper supports the full end-to-end ML lifecycle from online data collection to model training, deployment, inference, and extends support to evaluation and tuning against product goals. We outline the platform architecture and overall impact of production deployment -- Looper currently hosts 700 ML models and makes 6 million decisions per second. We also describe the learning curve and summarize experiences of platform adopters.
Text Ranking and Classification using Data Compression
Sep 23, 2021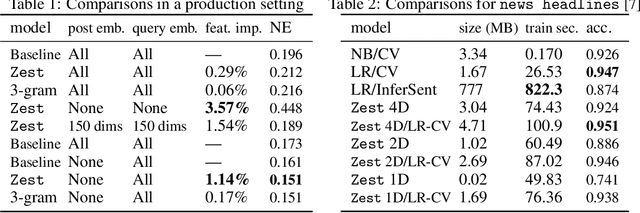
A well-known but rarely used approach to text categorization uses conditional entropy estimates computed using data compression tools. Text affinity scores derived from compressed sizes can be used for classification and ranking tasks, but their success depends on the compression tools used. We use the Zstandard compressor and strengthen these ideas in several ways, calling the resulting language-agnostic technique Zest. In applications, this approach simplifies configuration, avoiding careful feature extraction and large ML models. Our ablation studies confirm the value of individual enhancements we introduce. We show that Zest complements and can compete with language-specific multidimensional content embeddings in production, but cannot outperform other counting methods on public datasets.
Prioritizing Original News on Facebook
Mar 14, 2021
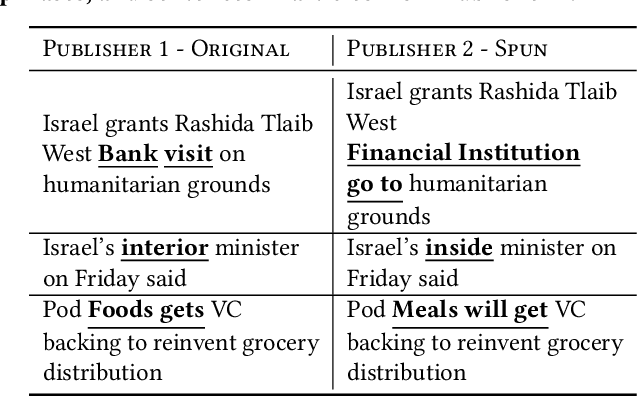
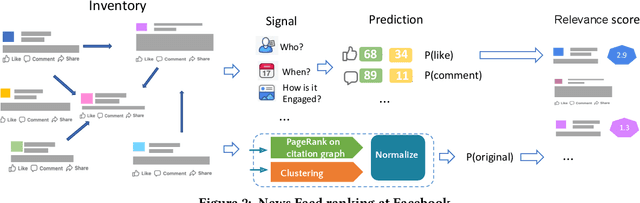
This work outlines how we prioritize original news, a critical indicator of news quality. By examining the landscape and life-cycle of news posts on our social media platform, we identify challenges of building and deploying an originality score. We pursue an approach based on normalized PageRank values and three-step clustering, and refresh the score on an hourly basis to capture the dynamics of online news. We describe a near real-time system architecture, evaluate our methodology, and deploy it to production. Our empirical results validate individual components and show that prioritizing original news increases user engagement with news and improves proprietary cumulative metrics.
Regular Expressions for Fast-response COVID-19 Text Classification
Feb 19, 2021
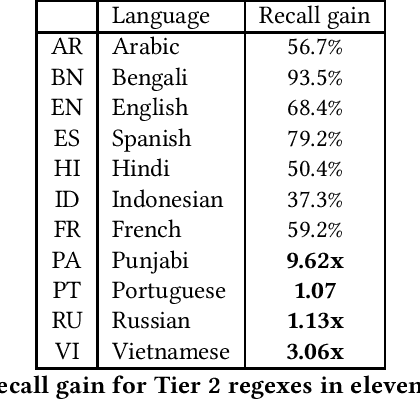
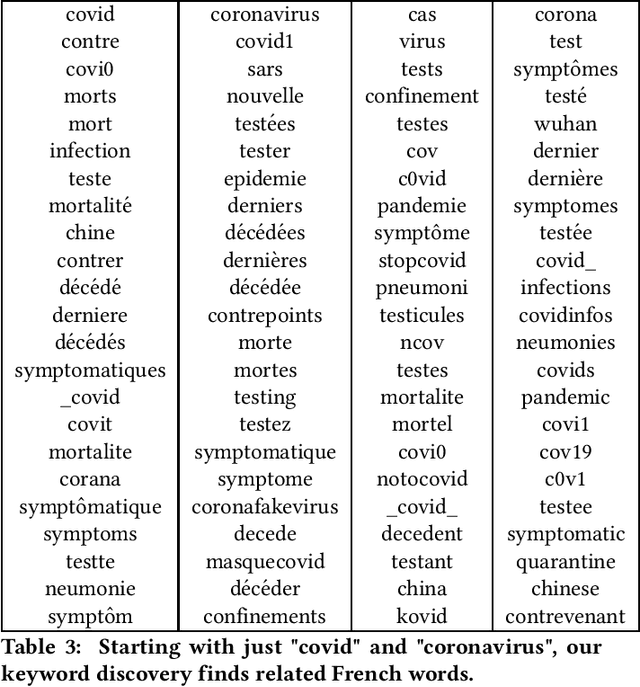

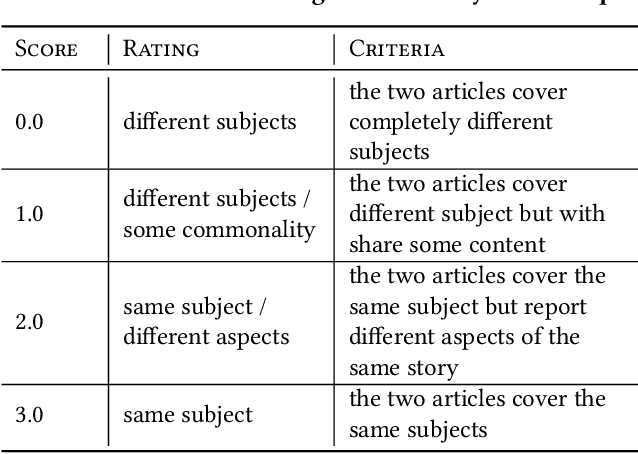
Text classifiers are at the core of many NLP applications and use a variety of algorithmic approaches and software. This paper describes how Facebook determines if a given piece of text - anything from a hashtag to a post - belongs to a narrow topic such as COVID-19. To fully define a topic and evaluate classifier performance we employ human-guided iterations of keyword discovery, but do not require labeled data. For COVID-19, we build two sets of regular expressions: (1) for 66 languages, with 99% precision and recall >50%, (2) for the 11 most common languages, with precision >90% and recall >90%. Regular expressions enable low-latency queries from multiple platforms. Response to challenges like COVID-19 is fast and so are revisions. Comparisons to a DNN classifier show explainable results, higher precision and recall, and less overfitting. Our learnings can be applied to other narrow-topic classifiers.
Personalization for Web-based Services using Offline Reinforcement Learning
Feb 10, 2021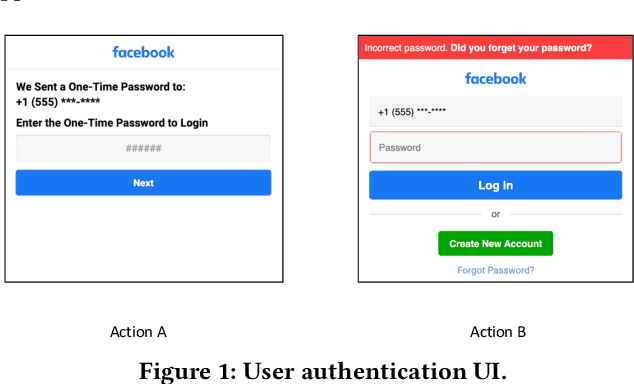

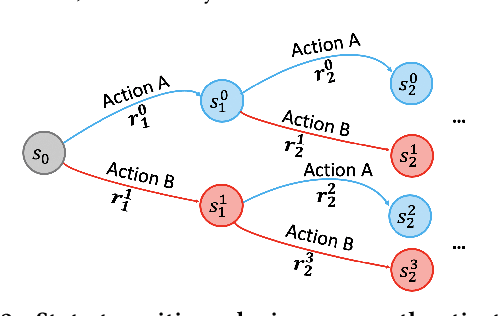
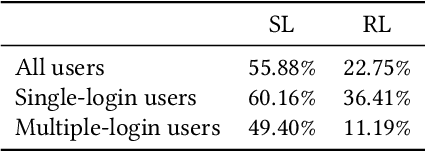
Large-scale Web-based services present opportunities for improving UI policies based on observed user interactions. We address challenges of learning such policies through model-free offline Reinforcement Learning (RL) with off-policy training. Deployed in a production system for user authentication in a major social network, it significantly improves long-term objectives. We articulate practical challenges, compare several ML techniques, provide insights on training and evaluation of RL models, and discuss generalizations.
A review of "Mem-computing NP-complete problems in polynomial time using polynomial resources"
Apr 22, 2015The reviewed paper describes an analog device that empirically solves small instances of the NP-complete Subset Sum Problem (SSP). The authors claim that this device can solve the SSP in polynomial time using polynomial space, in principle, and observe no exponential scaling in resource requirements. We point out that (a) the properties ascribed by the authors to their device are insufficient to solve NP-complete problems in poly-time, (b) runtime analysis offered does not cover the spectral measurement step, (c) the overall technique requires exponentially increasing resources when scaled up because of the spectral measurement step.