 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePersonalization for Web-based Services using Offline Reinforcement Learning
Feb 10, 2021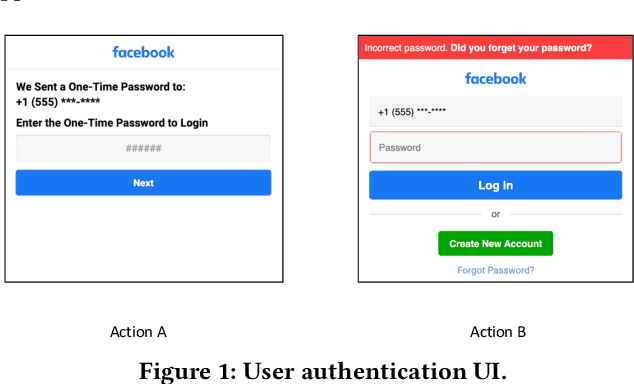

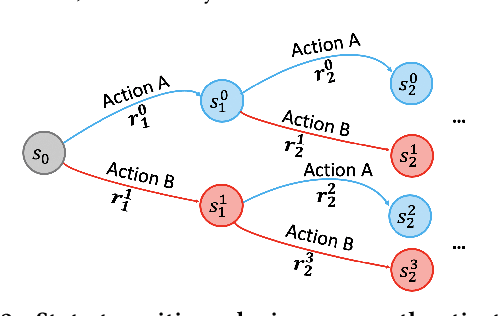
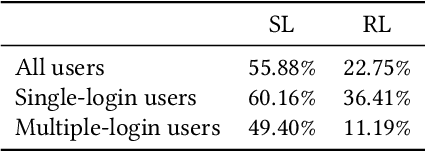
Large-scale Web-based services present opportunities for improving UI policies based on observed user interactions. We address challenges of learning such policies through model-free offline Reinforcement Learning (RL) with off-policy training. Deployed in a production system for user authentication in a major social network, it significantly improves long-term objectives. We articulate practical challenges, compare several ML techniques, provide insights on training and evaluation of RL models, and discuss generalizations.
Reinforcement Learning-based Product Delivery Frequency Control
Dec 20, 2020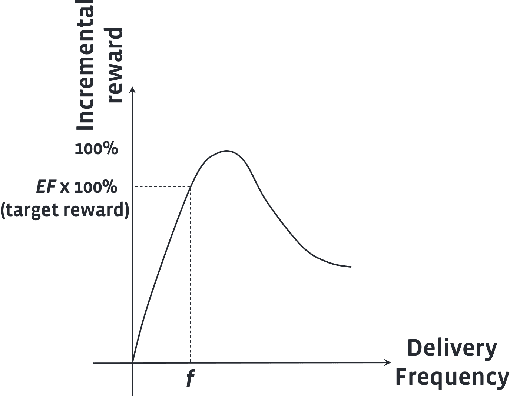

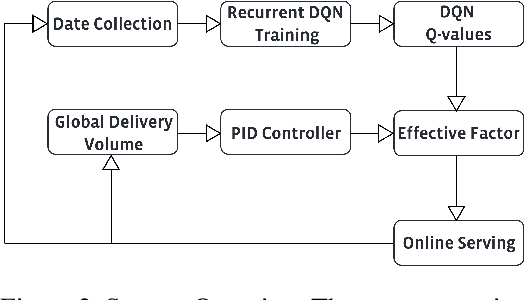
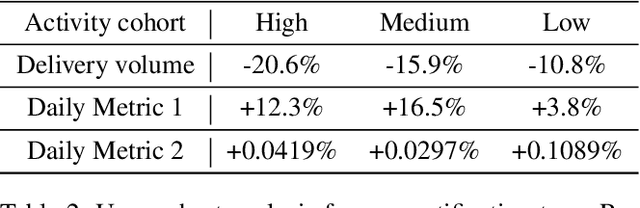
Frequency control is an important problem in modern recommender systems. It dictates the delivery frequency of recommendations to maintain product quality and efficiency. For example, the frequency of delivering promotional notifications impacts daily metrics as well as the infrastructure resource consumption (e.g. CPU and memory usage). There remain open questions on what objective we should optimize to represent business values in the long term best, and how we should balance between daily metrics and resource consumption in a dynamically fluctuating environment. We propose a personalized methodology for the frequency control problem, which combines long-term value optimization using reinforcement learning (RL) with a robust volume control technique we termed "Effective Factor". We demonstrate statistically significant improvement in daily metrics and resource efficiency by our method in several notification applications at a scale of billions of users. To our best knowledge, our study represents the first deep RL application on the frequency control problem at such an industrial scale.
Band-limited Soft Actor Critic Model
Jun 19, 2020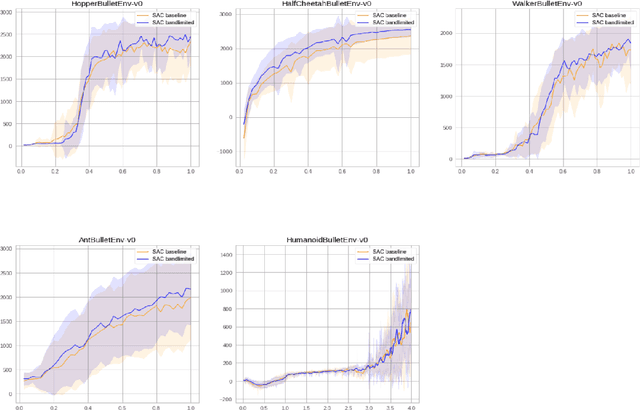


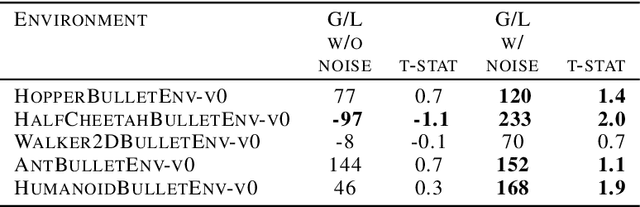
Soft Actor Critic (SAC) algorithms show remarkable performance in complex simulated environments. A key element of SAC networks is entropy regularization, which prevents the SAC actor from optimizing against fine grained features, oftentimes transient, of the state-action value function. This results in better sample efficiency during early training. We take this idea one step further by artificially bandlimiting the target critic spatial resolution through the addition of a convolutional filter. We derive the closed form solution in the linear case and show that bandlimiting reduces the interdependency between the low and high frequency components of the state-action value approximation, allowing the critic to learn faster. In experiments, the bandlimited SAC outperformed the classic twin-critic SAC in a number of Gym environments, and displayed more stability in returns. We derive novel insights about SAC by adding a stochastic noise disturbance, a technique that is increasingly being used to learn robust policies that transfer well to the real world counterparts.
Horizon: Facebook's Open Source Applied Reinforcement Learning Platform
Nov 01, 2018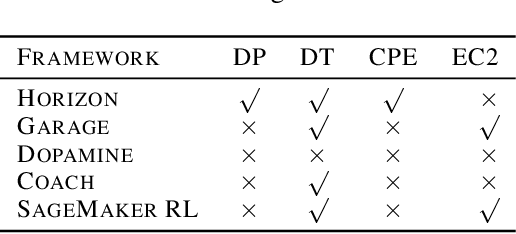
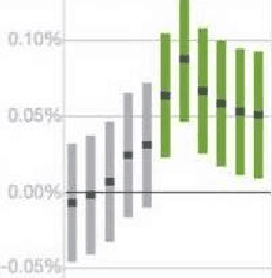
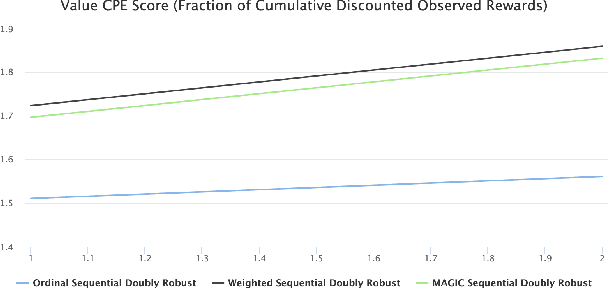
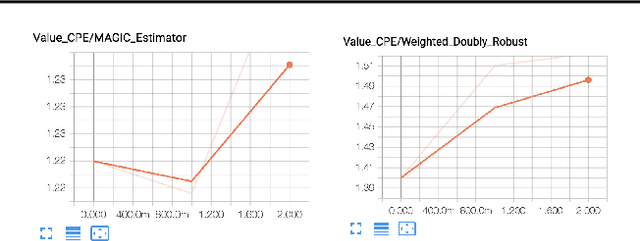
In this paper we present Horizon, Facebook's open source applied reinforcement learning (RL) platform. Horizon is an end-to-end platform designed to solve industry applied RL problems where datasets are large (millions to billions of observations), the feedback loop is slow (vs. a simulator), and experiments must be done with care because they don't run in a simulator. Unlike other RL platforms, which are often designed for fast prototyping and experimentation, Horizon is designed with production use cases as top of mind. The platform contains workflows to train popular deep RL algorithms and includes data preprocessing, feature transformation, distributed training, counterfactual policy evaluation, and optimized serving. We also showcase real examples of where models trained with Horizon significantly outperformed and replaced supervised learning systems at Facebook.