 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBenchmarking Batch Deep Reinforcement Learning Algorithms
Oct 03, 2019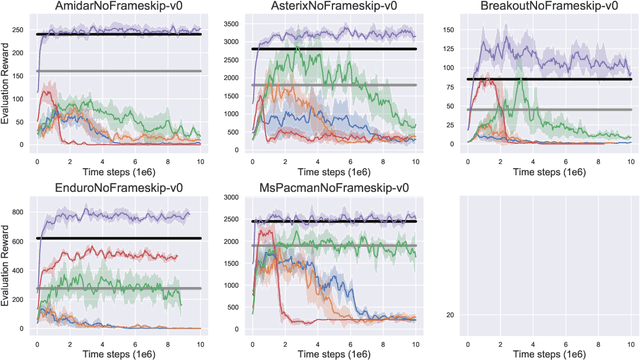
Widely-used deep reinforcement learning algorithms have been shown to fail in the batch setting--learning from a fixed data set without interaction with the environment. Following this result, there have been several papers showing reasonable performances under a variety of environments and batch settings. In this paper, we benchmark the performance of recent off-policy and batch reinforcement learning algorithms under unified settings on the Atari domain, with data generated by a single partially-trained behavioral policy. We find that under these conditions, many of these algorithms underperform DQN trained online with the same amount of data, as well as the partially-trained behavioral policy. To introduce a strong baseline, we adapt the Batch-Constrained Q-learning algorithm to a discrete-action setting, and show it outperforms all existing algorithms at this task.
Horizon: Facebook's Open Source Applied Reinforcement Learning Platform
Nov 01, 2018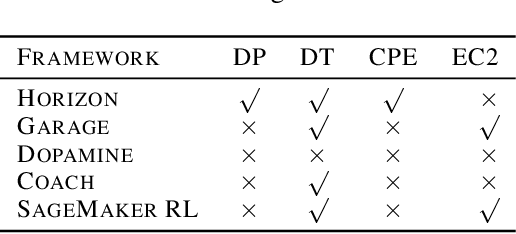
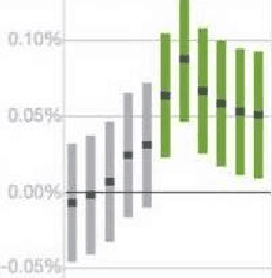
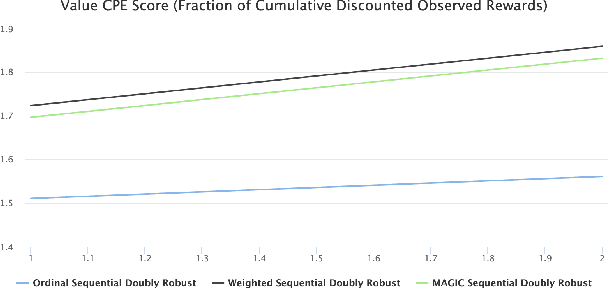
In this paper we present Horizon, Facebook's open source applied reinforcement learning (RL) platform. Horizon is an end-to-end platform designed to solve industry applied RL problems where datasets are large (millions to billions of observations), the feedback loop is slow (vs. a simulator), and experiments must be done with care because they don't run in a simulator. Unlike other RL platforms, which are often designed for fast prototyping and experimentation, Horizon is designed with production use cases as top of mind. The platform contains workflows to train popular deep RL algorithms and includes data preprocessing, feature transformation, distributed training, counterfactual policy evaluation, and optimized serving. We also showcase real examples of where models trained with Horizon significantly outperformed and replaced supervised learning systems at Facebook.
Improving Exploration in Evolution Strategies for Deep Reinforcement Learning via a Population of Novelty-Seeking Agents
Oct 29, 2018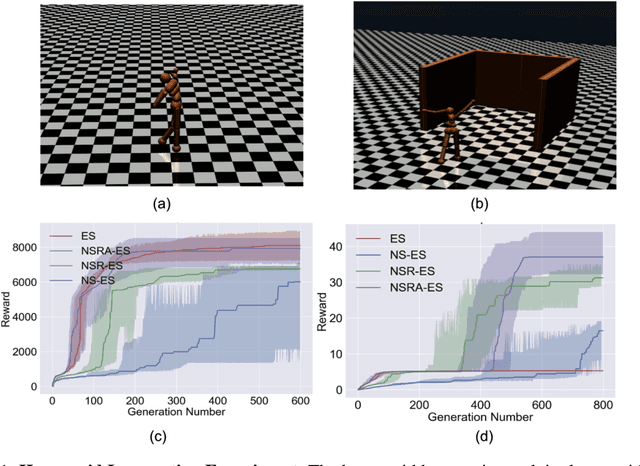
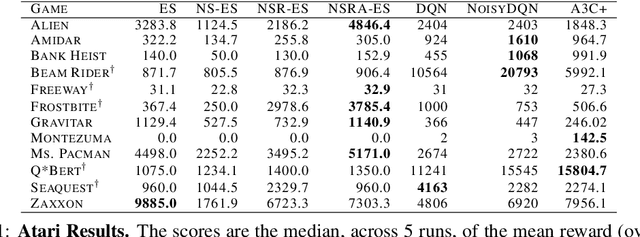

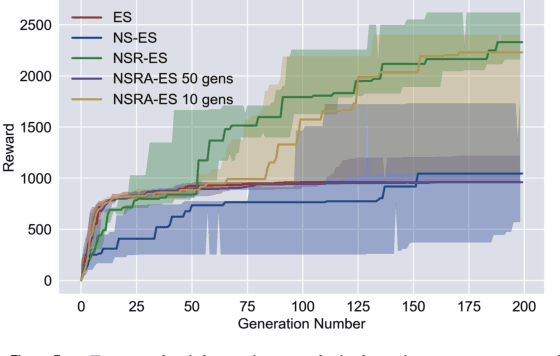
Evolution strategies (ES) are a family of black-box optimization algorithms able to train deep neural networks roughly as well as Q-learning and policy gradient methods on challenging deep reinforcement learning (RL) problems, but are much faster (e.g. hours vs. days) because they parallelize better. However, many RL problems require directed exploration because they have reward functions that are sparse or deceptive (i.e. contain local optima), and it is unknown how to encourage such exploration with ES. Here we show that algorithms that have been invented to promote directed exploration in small-scale evolved neural networks via populations of exploring agents, specifically novelty search (NS) and quality diversity (QD) algorithms, can be hybridized with ES to improve its performance on sparse or deceptive deep RL tasks, while retaining scalability. Our experiments confirm that the resultant new algorithms, NS-ES and two QD algorithms, NSR-ES and NSRA-ES, avoid local optima encountered by ES to achieve higher performance on Atari and simulated robots learning to walk around a deceptive trap. This paper thus introduces a family of fast, scalable algorithms for reinforcement learning that are capable of directed exploration. It also adds this new family of exploration algorithms to the RL toolbox and raises the interesting possibility that analogous algorithms with multiple simultaneous paths of exploration might also combine well with existing RL algorithms outside ES.
Deep Neuroevolution: Genetic Algorithms Are a Competitive Alternative for Training Deep Neural Networks for Reinforcement Learning
Apr 20, 2018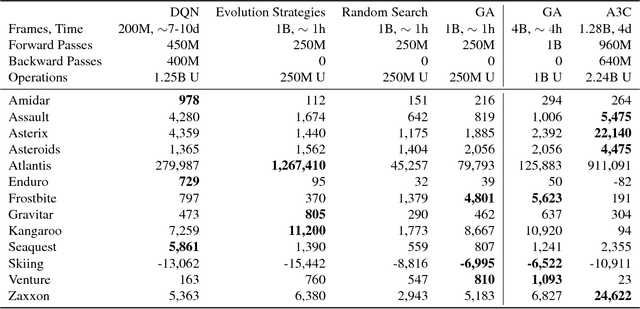
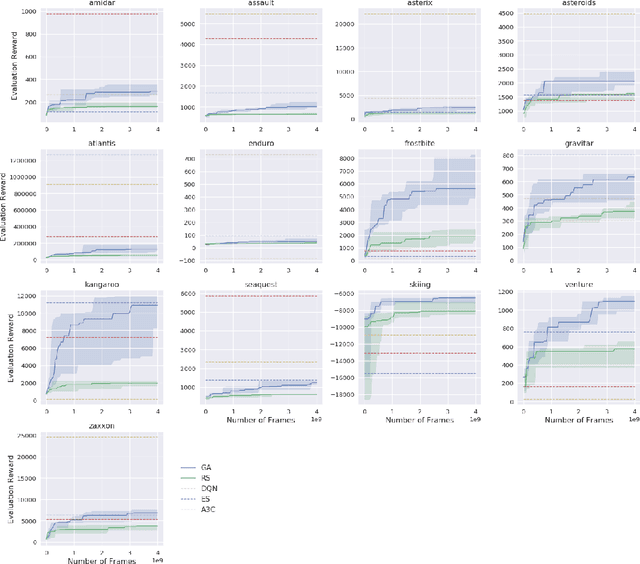
Deep artificial neural networks (DNNs) are typically trained via gradient-based learning algorithms, namely backpropagation. Evolution strategies (ES) can rival backprop-based algorithms such as Q-learning and policy gradients on challenging deep reinforcement learning (RL) problems. However, ES can be considered a gradient-based algorithm because it performs stochastic gradient descent via an operation similar to a finite-difference approximation of the gradient. That raises the question of whether non-gradient-based evolutionary algorithms can work at DNN scales. Here we demonstrate they can: we evolve the weights of a DNN with a simple, gradient-free, population-based genetic algorithm (GA) and it performs well on hard deep RL problems, including Atari and humanoid locomotion. The Deep GA successfully evolves networks with over four million free parameters, the largest neural networks ever evolved with a traditional evolutionary algorithm. These results (1) expand our sense of the scale at which GAs can operate, (2) suggest intriguingly that in some cases following the gradient is not the best choice for optimizing performance, and (3) make immediately available the multitude of neuroevolution techniques that improve performance. We demonstrate the latter by showing that combining DNNs with novelty search, which encourages exploration on tasks with deceptive or sparse reward functions, can solve a high-dimensional problem on which reward-maximizing algorithms (e.g.\ DQN, A3C, ES, and the GA) fail. Additionally, the Deep GA is faster than ES, A3C, and DQN (it can train Atari in ${\raise.17ex\hbox{$\scriptstyle\sim$}}$4 hours on one desktop or ${\raise.17ex\hbox{$\scriptstyle\sim$}}$1 hour distributed on 720 cores), and enables a state-of-the-art, up to 10,000-fold compact encoding technique.