 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRepresentation Learning Enables Scalable Multitask Deep Reinforcement Learning
Jun 04, 2026Scaling reinforcement learning (RL) to diverse multitask settings remains a central challenge. While recent advances in model-based RL achieve strong performance, they rely on planning and complex training pipelines, making it unclear which components are essential for scalability. We revisit this question and argue that the primary driver of scalable multitask RL is not model-based control, but \emph{representation learning}. In particular, we show that combining predictive, model-based representations with high-capacity value function approximation is sufficient to achieve strong performance, even without planning. We evaluate a simple model-free algorithm, MR.Q, coupled with auxiliary predictive objectives into a scalable actor-critic architecture. This approach outperforms a recent world-model-based method and a range of deep RL baselines across a diverse suite of multitask continuous control tasks, while significantly reducing computational overhead and improving wall-clock efficiency. We observe consistent improvements with increased model capacity and show through ablations that predictive representation learning is critical for performance.
Drift Q-Learning
May 29, 2026Offline reinforcement learning requires improving a policy from fixed data while avoiding out-of-distribution actions with unreliable value estimates. Diffusion and flow policies handle this trade-off by modeling the behavior distribution to regularize the RL objective, but they require iterative denoising, solver integrations, and in more efficient variants, distillation or other approximations at inference. We propose DriftQL, which combines a drift-based behavioral regularizer with critic-driven policy improvement. The value signal biases the policy toward high-value regions of the data support, while attraction and repulsion together keep generated actions near the data and prevent collapse onto a single mode. DriftQL is implemented as a single network with a unified training objective and generates actions in a single forward pass. On D4RL and OGBench, DriftQL consistently outperforms diffusion and flow methods, advancing the state of the art. Under degraded data quality, where the baselines visibly struggle, DriftQL remains close to its clean-data performance, positioning it as a promising alternative to diffusion and flow-based methods while maintaining the simplicity and efficiency of deterministic approaches. Project page: https://driftql.github.io/
Goal-Conditioned Agents that Learn Everything All at Once
May 22, 2026A goal-conditioned reinforcement learning agent exploring an environment will see a wealth of information throughout a trajectory, most of which is discarded when only performing on-policy updates with respect to the commanded goal. All-goals learning, where each transition is used for learning off-policy with respect to every goal, allows agents to extract maximal information, however it is usually computationally infeasible when done via naive relabelling. This can be overcome by jointly outputting values and actions for every goal at once, allowing for efficient, parallel all-goals updates with a single pass through the network, in a process we call Learning Everything all at Once (LEO). We show that this approach significantly outperforms other methods on goal-conditioned Craftax and is competitive with existing baselines on continuous control environments, while achieving a >250x speed-up compared to all-goals relabelling. We then go on to show that this approach can be made even more powerful by using LEO as a teacher network, rather than a direct actor. We hope that, by unlocking all-goals learning at scale, LEO can serve as a useful tool for RL practitioners in complex environments. We open source our code.
Debiased Model-based Representations for Sample-efficient Continuous Control
May 12, 2026Model-based representations recently stand out as a promising framework that embeds latent dynamics information into the representations for downstream off-policy actor-critic learning. It implicitly combines the advantages of both model-free and model-based approaches while avoiding the training costs associated with model-based methods. Nevertheless, existing model-based representation methods can fail to capture sufficient information about relevant variables and can overfit to early experiences in the replay buffer. These incur biases in representation and actor-critic learning, leading to inferior performance. To address this, we propose Debiased model-based Representations for Q-learning, tagged DR.Q algorithm. DR.Q explicitly maximizes the mutual information between the representations of the current state-action pair and the next state besides minimizing their deviations, and samples transitions with faded prioritized experience replay. We evaluate DR.Q on numerous continuous control benchmarks with a single set of hyperparameters, and the results demonstrate that DR.Q can match or surpass recent strong baselines, sometimes outperforming them by a large margin. Our code is available at https://github.com/dmksjfl/DR.Q.
Hierarchical Behaviour Spaces
Apr 27, 2026Recent work in hierarchical reinforcement learning has shown success in scaling to billions of timesteps when learning over a set of predefined option reward functions. We show that, instead of using a single reward function per option, the reward functions can be effectively used to induce a space of behaviours, by letting the controller specify linear combinations over reward functions, allowing a more expressive set of policies to be represented. We call this method Hierarchical Behaviour Spaces (HBS). We evaluate HBS on the NetHack Learning Environment, demonstrating strong performance. We conduct a series of experiments and determine that, perhaps going against conventional wisdom, the benefits of hierarchy in our method come from increased exploration rather than long term reasoning.
The Surprising Difficulty of Search in Model-Based Reinforcement Learning
Jan 29, 2026This paper investigates search in model-based reinforcement learning (RL). Conventional wisdom holds that long-term predictions and compounding errors are the primary obstacles for model-based RL. We challenge this view, showing that search is not a plug-and-play replacement for a learned policy. Surprisingly, we find that search can harm performance even when the model is highly accurate. Instead, we show that mitigating distribution shift matters more than improving model or value function accuracy. Building on this insight, we identify key techniques for enabling effective search, achieving state-of-the-art performance across multiple popular benchmark domains.
Imbalanced Gradients in RL Post-Training of Multi-Task LLMs
Oct 22, 2025Multi-task post-training of large language models (LLMs) is typically performed by mixing datasets from different tasks and optimizing them jointly. This approach implicitly assumes that all tasks contribute gradients of similar magnitudes; when this assumption fails, optimization becomes biased toward large-gradient tasks. In this paper, however, we show that this assumption fails in RL post-training: certain tasks produce significantly larger gradients, thus biasing updates toward those tasks. Such gradient imbalance would be justified only if larger gradients implied larger learning gains on the tasks (i.e., larger performance improvements) -- but we find this is not true. Large-gradient tasks can achieve similar or even much lower learning gains than small-gradient ones. Further analyses reveal that these gradient imbalances cannot be explained by typical training statistics such as training rewards or advantages, suggesting that they arise from the inherent differences between tasks. This cautions against naive dataset mixing and calls for future work on principled gradient-level corrections for LLMs.
Towards General-Purpose Model-Free Reinforcement Learning
Jan 27, 2025



Reinforcement learning (RL) promises a framework for near-universal problem-solving. In practice however, RL algorithms are often tailored to specific benchmarks, relying on carefully tuned hyperparameters and algorithmic choices. Recently, powerful model-based RL methods have shown impressive general results across benchmarks but come at the cost of increased complexity and slow run times, limiting their broader applicability. In this paper, we attempt to find a unifying model-free deep RL algorithm that can address a diverse class of domains and problem settings. To achieve this, we leverage model-based representations that approximately linearize the value function, taking advantage of the denser task objectives used by model-based RL while avoiding the costs associated with planning or simulated trajectories. We evaluate our algorithm, MR.Q, on a variety of common RL benchmarks with a single set of hyperparameters and show a competitive performance against domain-specific and general baselines, providing a concrete step towards building general-purpose model-free deep RL algorithms.
Fairness in Reinforcement Learning with Bisimulation Metrics
Dec 22, 2024



Ensuring long-term fairness is crucial when developing automated decision making systems, specifically in dynamic and sequential environments. By maximizing their reward without consideration of fairness, AI agents can introduce disparities in their treatment of groups or individuals. In this paper, we establish the connection between bisimulation metrics and group fairness in reinforcement learning. We propose a novel approach that leverages bisimulation metrics to learn reward functions and observation dynamics, ensuring that learners treat groups fairly while reflecting the original problem. We demonstrate the effectiveness of our method in addressing disparities in sequential decision making problems through empirical evaluation on a standard fairness benchmark consisting of lending and college admission scenarios.
Exploiting Structure in Offline Multi-Agent RL: The Benefits of Low Interaction Rank
Oct 01, 2024
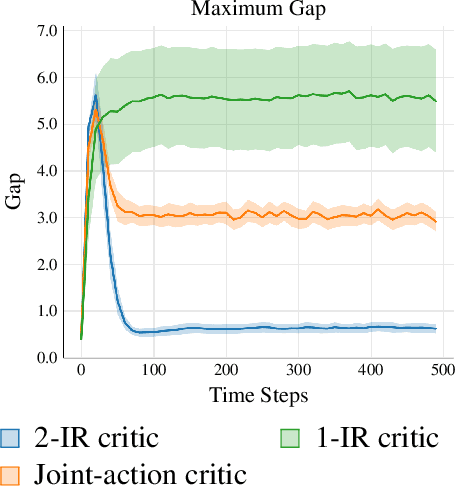

We study the problem of learning an approximate equilibrium in the offline multi-agent reinforcement learning (MARL) setting. We introduce a structural assumption -- the interaction rank -- and establish that functions with low interaction rank are significantly more robust to distribution shift compared to general ones. Leveraging this observation, we demonstrate that utilizing function classes with low interaction rank, when combined with regularization and no-regret learning, admits decentralized, computationally and statistically efficient learning in offline MARL. Our theoretical results are complemented by experiments that showcase the potential of critic architectures with low interaction rank in offline MARL, contrasting with commonly used single-agent value decomposition architectures.