 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIL-flOw: Imitation Learning from Observation using Normalizing Flows
Paper and Code
May 19, 2022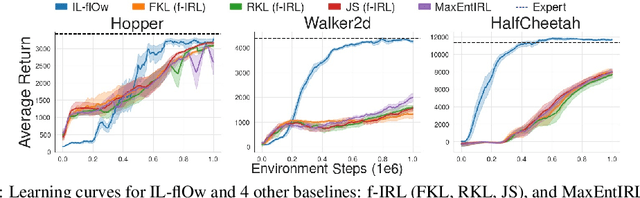
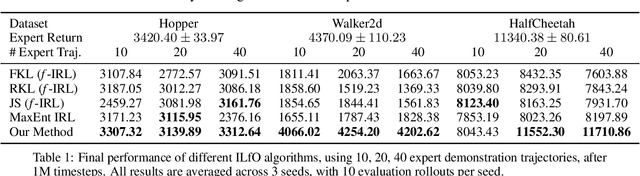
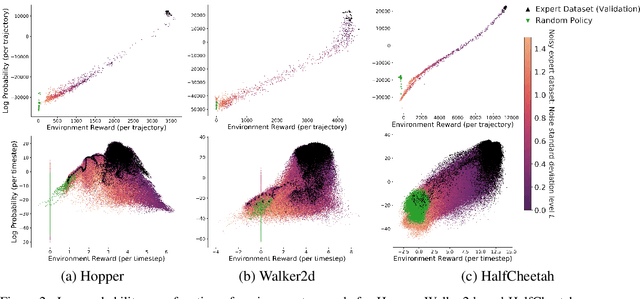
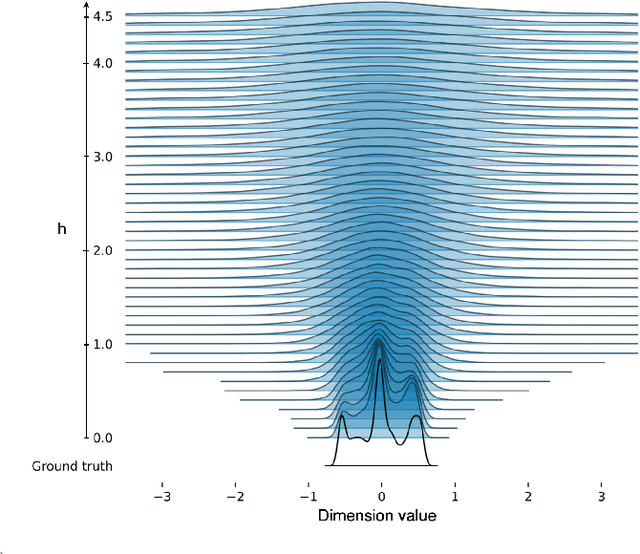
We present an algorithm for Inverse Reinforcement Learning (IRL) from expert state observations only. Our approach decouples reward modelling from policy learning, unlike state-of-the-art adversarial methods which require updating the reward model during policy search and are known to be unstable and difficult to optimize. Our method, IL-flOw, recovers the expert policy by modelling state-state transitions, by generating rewards using deep density estimators trained on the demonstration trajectories, avoiding the instability issues of adversarial methods. We demonstrate that using the state transition log-probability density as a reward signal for forward reinforcement learning translates to matching the trajectory distribution of the expert demonstrations, and experimentally show good recovery of the true reward signal as well as state of the art results for imitation from observation on locomotion and robotic continuous control tasks.