 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeREVES: REvision and VErification--Augmented Training for Test-Time Scaling
Jun 17, 2026Test-time scaling via sequential revision has emerged as a powerful paradigm for enhancing Large Language Model (LLM) reasoning. However, standard post-training methods primarily optimize single-shot objectives, creating a fundamental misalignment with multi-step inference dynamics. While recent work treats this as multi-turn reinforcement learning (RL), conventional approaches optimize over the multi-step trajectories directly, failing to further exploit the high-quality mistakes in intermediate steps that model can learn from correcting them. We propose a two-stage iterative framework that alternates between online data/prompt augmentation and policy optimization. By converting the intermediate steps (``near-miss'' answers) in the successful recovery trajectories into decoupled revision and verification prompts, our approach concentrates training on both effective answer transformation and error identification. This approach enables efficient off-policy data generation and reduces the computational overhead of long-horizon sampling compared to standard multi-turn RL. On LiveCodeBench, using publicly available test cases as feedback, we observe gains of +6.5 points over the RL baseline and +4.0 points over standard multi-turn training. Beyond coding, our approach matches the previously reported SOTA result on circle packing while using the smallest base model (4B) and far fewer rollouts than the much larger evolutionary search systems. Math results under ground-truth verification further confirm improved correction ability. It also generalizes to out-of-distribution constraint-satisfaction puzzles such as n\_queens and mini\_sudoku, where correctness is defined entirely by problem constraints. Code is available at https://github.com/yxliu02/REVES.git.
MAPLE: Latent Multi-Agent Play for End-to-End Autonomous Driving
May 13, 2026Vision-language-action (VLA) models are effective as end-to-end motion planners, but can be brittle when evaluated in closed-loop settings due to being trained under traditional imitation learning framework. Existing closed-loop supervision approaches lack scalability and fail to completely model a reactive environment. We propose MAPLE, a novel framework for reactive, multi-agent rollout of a dynamic driving scenario in the latent space of the VLA model. The ego vehicle and nearby traffic agents are independently controlled over multi-step horizons, while being reactive to other agents in the scene, enabling closed-loop training. MAPLE consists of two training stages: (1) supervised fine-tuning on the latent rollouts based on ground-truth trajectories, followed by (2) reinforcement learning with global and agent -specific rewards that encourage safety, progress, and interaction realism. We further propose diversity rewards that encourage the model to generate planning behaviors that may not be present in logged driving data. Notably, our closed-loop training framework is scalable and does not require external simulators, which can be computationally expensive to run and have limited visual fidelity to the real-world. MAPLE achieves state-of-the-art driving performance on Bench2Drive and demonstrates scalable, closed-loop multi-agent play for robust E2E autonomous driving systems.
Maximum Entropy Semi-Supervised Inverse Reinforcement Learning
Apr 22, 2026A popular approach to apprenticeship learning (AL) is to formulate it as an inverse reinforcement learning (IRL) problem. The MaxEnt-IRL algorithm successfully integrates the maximum entropy principle into IRL and unlike its predecessors, it resolves the ambiguity arising from the fact that a possibly large number of policies could match the expert's behavior. In this paper, we study an AL setting in which in addition to the expert's trajectories, a number of unsupervised trajectories is available. We introduce MESSI, a novel algorithm that combines MaxEnt-IRL with principles coming from semi-supervised learning. In particular, MESSI integrates the unsupervised data into the MaxEnt-IRL framework using a pairwise penalty on trajectories. Empirical results in a highway driving and grid-world problems indicate that MESSI is able to take advantage of the unsupervised trajectories and improve the performance of MaxEnt-IRL.
Displacement-Resistant Extensions of DPO with Nonconvex $f$-Divergences
Feb 06, 2026DPO and related algorithms align language models by directly optimizing the RLHF objective: find a policy that maximizes the Bradley-Terry reward while staying close to a reference policy through a KL divergence penalty. Previous work showed that this approach could be further generalized: the original problem remains tractable even if the KL divergence is replaced by a family of $f$-divergence with a convex generating function $f$. Our first contribution is to show that convexity of $f$ is not essential. Instead, we identify a more general condition, referred to as DPO-inducing, that precisely characterizes when the RLHF problem remains tractable. Our next contribution is to establish a second condition on $f$ that is necessary to prevent probability displacement, a known empirical phenomenon in which the probabilities of the winner and the loser responses approach zero. We refer to any $f$ that satisfies this condition as displacement-resistant. We finally focus on a specific DPO-inducing and displacement-resistant $f$, leading to our novel SquaredPO loss. Compared to DPO, this new loss offers stronger theoretical guarantees while performing competitively in practice.
DISPO: Enhancing Training Efficiency and Stability in Reinforcement Learning for Large Language Model Mathematical Reasoning
Feb 01, 2026Reinforcement learning with verifiable rewards has emerged as a promising paradigm for enhancing the reasoning capabilities of large language models particularly in mathematics. Current approaches in this domain present a clear trade-off: PPO-style methods (e.g., GRPO/DAPO) offer training stability but exhibit slow learning trajectories due to their trust-region constraints on policy updates, while REINFORCE-style approaches (e.g., CISPO) demonstrate improved learning efficiency but suffer from performance instability as they clip importance sampling weights while still permitting non-zero gradients outside the trust-region. To address these limitations, we introduce DISPO, a simple yet effective REINFORCE-style algorithm that decouples the up-clipping and down-clipping of importance sampling weights for correct and incorrect responses, yielding four controllable policy update regimes. Through targeted ablations, we uncover how each regime impacts training: for correct responses, weights >1 increase the average token entropy (i.e., exploration) while weights <1 decrease it (i.e., distillation) -- both beneficial but causing gradual performance degradation when excessive. For incorrect responses, overly restrictive clipping triggers sudden performance collapse through repetitive outputs (when weights >1) or vanishing response lengths (when weights <1). By separately tuning these four clipping parameters, DISPO maintains the exploration-distillation balance while preventing catastrophic failures, achieving 61.04% on AIME'24 (vs. 55.42% CISPO and 50.21% DAPO) with similar gains across various benchmarks and models.
Direct Preference Optimization with Rating Information: Practical Algorithms and Provable Gains
Jan 31, 2026The class of direct preference optimization (DPO) algorithms has emerged as a promising approach for solving the alignment problem in foundation models. These algorithms work with very limited feedback in the form of pairwise preferences and fine-tune models to align with these preferences without explicitly learning a reward model. While the form of feedback used by these algorithms makes the data collection process easy and relatively more accurate, its ambiguity in terms of the quality of responses could have negative implications. For example, it is not clear if a decrease (increase) in the likelihood of preferred (dispreferred) responses during the execution of these algorithms could be interpreted as a positive or negative phenomenon. In this paper, we study how to design algorithms that can leverage additional information in the form of rating gap, which informs the learner how much the chosen response is better than the rejected one. We present new algorithms that can achieve faster statistical rates than DPO in presence of accurate rating gap information. Moreover, we theoretically prove and empirically show that the performance of our algorithms is robust to inaccuracy in rating gaps. Finally, we demonstrate the solid performance of our methods in comparison to a number of DPO-style algorithms across a wide range of LLMs and evaluation benchmarks.
Does Thinking More always Help? Understanding Test-Time Scaling in Reasoning Models
Jun 04, 2025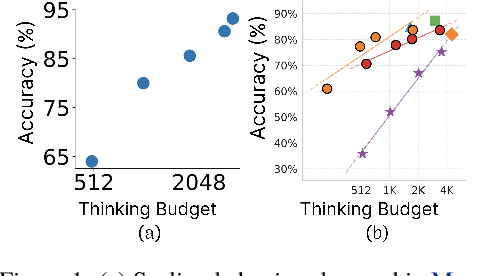
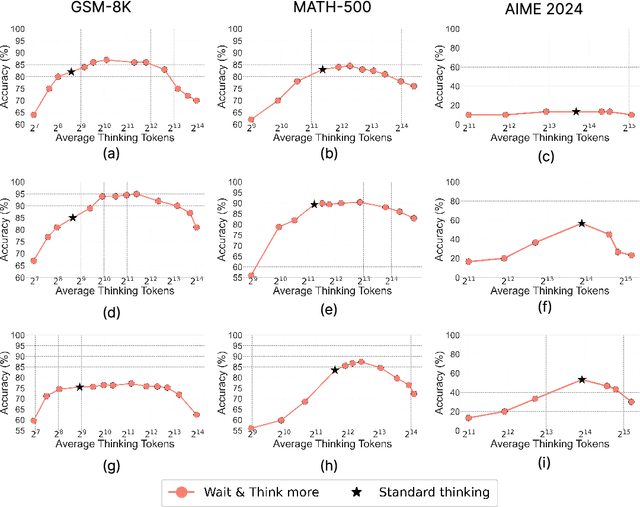
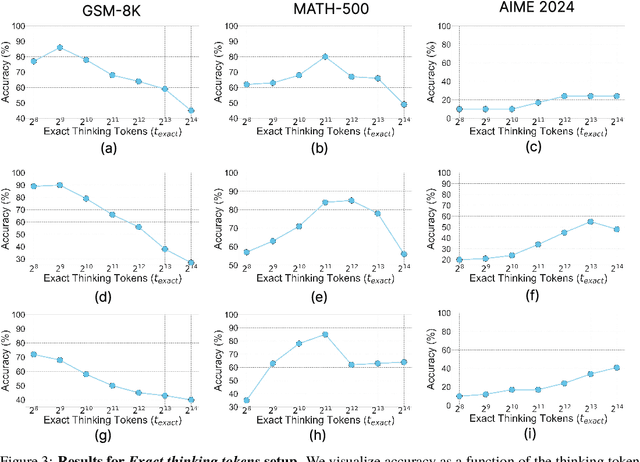
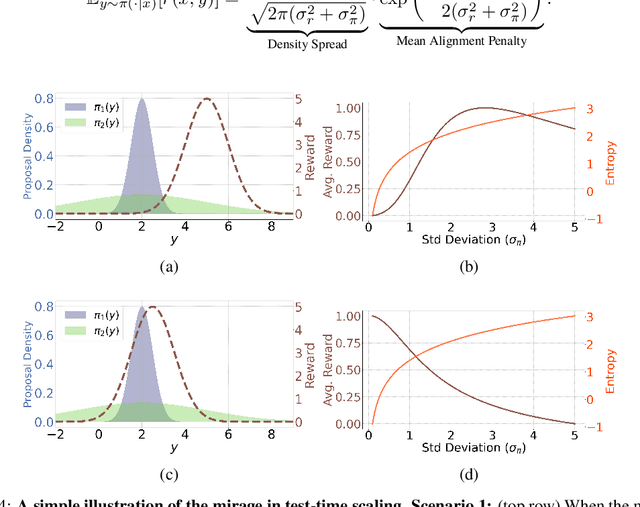
Recent trends in test-time scaling for reasoning models (e.g., OpenAI o1, DeepSeek R1) have led to a popular belief that extending thinking traces using prompts like "Wait" or "Let me rethink" can improve performance. This raises a natural question: Does thinking more at test-time truly lead to better reasoning? To answer this question, we perform a detailed empirical study across models and benchmarks, which reveals a consistent pattern of initial performance improvements from additional thinking followed by a decline, due to "overthinking". To understand this non-monotonic trend, we consider a simple probabilistic model, which reveals that additional thinking increases output variance-creating an illusion of improved reasoning while ultimately undermining precision. Thus, observed gains from "more thinking" are not true indicators of improved reasoning, but artifacts stemming from the connection between model uncertainty and evaluation metric. This suggests that test-time scaling through extended thinking is not an effective way to utilize the inference thinking budget. Recognizing these limitations, we introduce an alternative test-time scaling approach, parallel thinking, inspired by Best-of-N sampling. Our method generates multiple independent reasoning paths within the same inference budget and selects the most consistent response via majority vote, achieving up to 20% higher accuracy compared to extended thinking. This provides a simple yet effective mechanism for test-time scaling of reasoning models.
Diffusion Blend: Inference-Time Multi-Preference Alignment for Diffusion Models
May 24, 2025
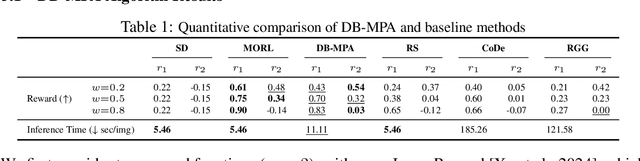


Reinforcement learning (RL) algorithms have been used recently to align diffusion models with downstream objectives such as aesthetic quality and text-image consistency by fine-tuning them to maximize a single reward function under a fixed KL regularization. However, this approach is inherently restrictive in practice, where alignment must balance multiple, often conflicting objectives. Moreover, user preferences vary across prompts, individuals, and deployment contexts, with varying tolerances for deviation from a pre-trained base model. We address the problem of inference-time multi-preference alignment: given a set of basis reward functions and a reference KL regularization strength, can we design a fine-tuning procedure so that, at inference time, it can generate images aligned with any user-specified linear combination of rewards and regularization, without requiring additional fine-tuning? We propose Diffusion Blend, a novel approach to solve inference-time multi-preference alignment by blending backward diffusion processes associated with fine-tuned models, and we instantiate this approach with two algorithms: DB-MPA for multi-reward alignment and DB-KLA for KL regularization control. Extensive experiments show that Diffusion Blend algorithms consistently outperform relevant baselines and closely match or exceed the performance of individually fine-tuned models, enabling efficient, user-driven alignment at inference-time. The code is available at https://github.com/bluewoods127/DB-2025}{github.com/bluewoods127/DB-2025.
Ordering-based Conditions for Global Convergence of Policy Gradient Methods
Apr 02, 2025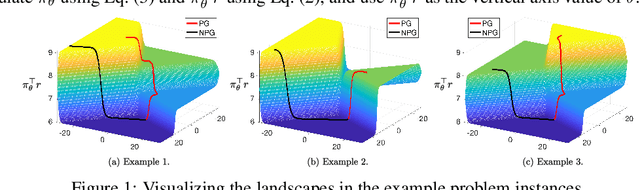
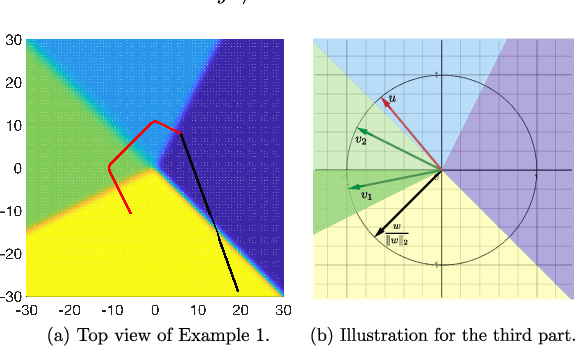
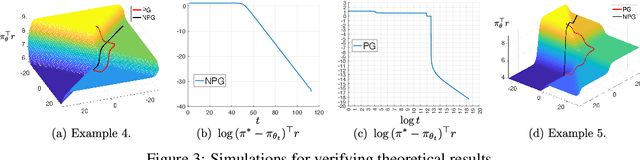
We prove that, for finite-arm bandits with linear function approximation, the global convergence of policy gradient (PG) methods depends on inter-related properties between the policy update and the representation. textcolor{blue}{First}, we establish a few key observations that frame the study: \textbf{(i)} Global convergence can be achieved under linear function approximation without policy or reward realizability, both for the standard Softmax PG and natural policy gradient (NPG). \textbf{(ii)} Approximation error is not a key quantity for characterizing global convergence in either algorithm. \textbf{(iii)} The conditions on the representation that imply global convergence are different between these two algorithms. Overall, these observations call into question approximation error as an appropriate quantity for characterizing the global convergence of PG methods under linear function approximation. \textcolor{blue}{Second}, motivated by these observations, we establish new general results: \textbf{(i)} NPG with linear function approximation achieves global convergence \emph{if and only if} the projection of the reward onto the representable space preserves the optimal action's rank, a quantity that is not strongly related to approximation error. \textbf{(ii)} The global convergence of Softmax PG occurs if the representation satisfies a non-domination condition and can preserve the ranking of rewards, which goes well beyond policy or reward realizability. We provide experimental results to support these theoretical findings.
C-3DPO: Constrained Controlled Classification for Direct Preference Optimization
Feb 22, 2025Direct preference optimization (DPO)-style algorithms have emerged as a promising approach for solving the alignment problem in AI. We present a novel perspective that formulates these algorithms as implicit classification algorithms. This classification framework enables us to recover many variants of DPO-style algorithms by choosing appropriate classification labels and loss functions. We then leverage this classification framework to demonstrate that the underlying problem solved in these algorithms is under-specified, making them susceptible to probability collapse of the winner-loser responses. We address this by proposing a set of constraints designed to control the movement of probability mass between the winner and loser in the reference and target policies. Our resulting algorithm, which we call Constrained Controlled Classification DPO (\texttt{C-3DPO}), has a meaningful RLHF interpretation. By hedging against probability collapse, \texttt{C-3DPO} provides practical improvements over vanilla \texttt{DPO} when aligning several large language models using standard preference datasets.