 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLUMINA: Long-horizon Understanding for Multi-turn Interactive Agents
Jan 23, 2026Large language models can perform well on many isolated tasks, yet they continue to struggle on multi-turn, long-horizon agentic problems that require skills such as planning, state tracking, and long context processing. In this work, we aim to better understand the relative importance of advancing these underlying capabilities for success on such tasks. We develop an oracle counterfactual framework for multi-turn problems that asks: how would an agent perform if it could leverage an oracle to perfectly perform a specific task? The change in the agent's performance due to this oracle assistance allows us to measure the criticality of such oracle skill in the future advancement of AI agents. We introduce a suite of procedurally generated, game-like tasks with tunable complexity. These controlled environments allow us to provide precise oracle interventions, such as perfect planning or flawless state tracking, and make it possible to isolate the contribution of each oracle without confounding effects present in real-world benchmarks. Our results show that while some interventions (e.g., planning) consistently improve performance across settings, the usefulness of other skills is dependent on the properties of the environment and language model. Our work sheds light on the challenges of multi-turn agentic environments to guide the future efforts in the development of AI agents and language models.
Deflated Dynamics Value Iteration
Jul 15, 2024



The Value Iteration (VI) algorithm is an iterative procedure to compute the value function of a Markov decision process, and is the basis of many reinforcement learning (RL) algorithms as well. As the error convergence rate of VI as a function of iteration $k$ is $O(\gamma^k)$, it is slow when the discount factor $\gamma$ is close to $1$. To accelerate the computation of the value function, we propose Deflated Dynamics Value Iteration (DDVI). DDVI uses matrix splitting and matrix deflation techniques to effectively remove (deflate) the top $s$ dominant eigen-structure of the transition matrix $\mathcal{P}^{\pi}$. We prove that this leads to a $\tilde{O}(\gamma^k |\lambda_{s+1}|^k)$ convergence rate, where $\lambda_{s+1}$is $(s+1)$-th largest eigenvalue of the dynamics matrix. We then extend DDVI to the RL setting and present Deflated Dynamics Temporal Difference (DDTD) algorithm. We empirically show the effectiveness of the proposed algorithms.
PID Accelerated Temporal Difference Algorithms
Jul 11, 2024



Long-horizon tasks, which have a large discount factor, pose a challenge for most conventional reinforcement learning (RL) algorithms. Algorithms such as Value Iteration and Temporal Difference (TD) learning have a slow convergence rate and become inefficient in these tasks. When the transition distributions are given, PID VI was recently introduced to accelerate the convergence of Value Iteration using ideas from control theory. Inspired by this, we introduce PID TD Learning and PID Q-Learning algorithms for the RL setting in which only samples from the environment are available. We give theoretical analysis of their convergence and acceleration compared to their traditional counterparts. We also introduce a method for adapting PID gains in the presence of noise and empirically verify its effectiveness.
Maximum Entropy Model Correction in Reinforcement Learning
Nov 29, 2023We propose and theoretically analyze an approach for planning with an approximate model in reinforcement learning that can reduce the adverse impact of model error. If the model is accurate enough, it accelerates the convergence to the true value function too. One of its key components is the MaxEnt Model Correction (MoCo) procedure that corrects the model's next-state distributions based on a Maximum Entropy density estimation formulation. Based on MoCo, we introduce the Model Correcting Value Iteration (MoCoVI) algorithm, and its sampled-based variant MoCoDyna. We show that MoCoVI and MoCoDyna's convergence can be much faster than the conventional model-free algorithms. Unlike traditional model-based algorithms, MoCoVI and MoCoDyna effectively utilize an approximate model and still converge to the correct value function.
Operator Splitting Value Iteration
Nov 25, 2022We introduce new planning and reinforcement learning algorithms for discounted MDPs that utilize an approximate model of the environment to accelerate the convergence of the value function. Inspired by the splitting approach in numerical linear algebra, we introduce Operator Splitting Value Iteration (OS-VI) for both Policy Evaluation and Control problems. OS-VI achieves a much faster convergence rate when the model is accurate enough. We also introduce a sample-based version of the algorithm called OS-Dyna. Unlike the traditional Dyna architecture, OS-Dyna still converges to the correct value function in presence of model approximation error.
Reward Poisoning in Reinforcement Learning: Attacks Against Unknown Learners in Unknown Environments
Feb 16, 2021We study black-box reward poisoning attacks against reinforcement learning (RL), in which an adversary aims to manipulate the rewards to mislead a sequence of RL agents with unknown algorithms to learn a nefarious policy in an environment unknown to the adversary a priori. That is, our attack makes minimum assumptions on the prior knowledge of the adversary: it has no initial knowledge of the environment or the learner, and neither does it observe the learner's internal mechanism except for its performed actions. We design a novel black-box attack, U2, that can provably achieve a near-matching performance to the state-of-the-art white-box attack, demonstrating the feasibility of reward poisoning even in the most challenging black-box setting.
Policy Teaching in Reinforcement Learning via Environment Poisoning Attacks
Nov 21, 2020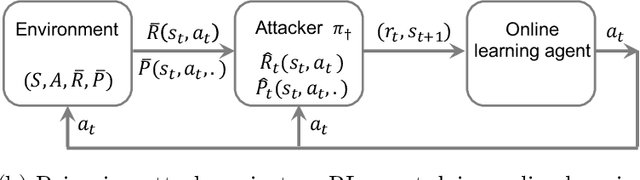
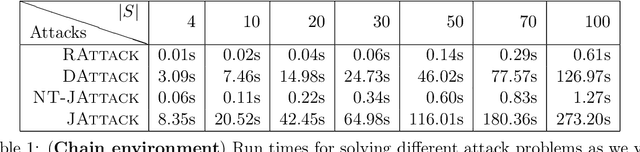
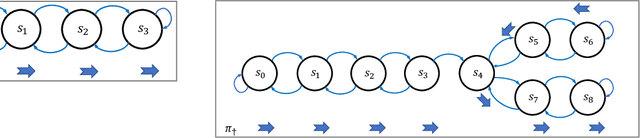
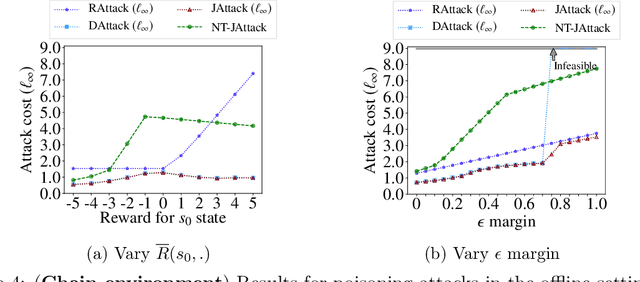
We study a security threat to reinforcement learning where an attacker poisons the learning environment to force the agent into executing a target policy chosen by the attacker. As a victim, we consider RL agents whose objective is to find a policy that maximizes reward in infinite-horizon problem settings. The attacker can manipulate the rewards and the transition dynamics in the learning environment at training-time, and is interested in doing so in a stealthy manner. We propose an optimization framework for finding an optimal stealthy attack for different measures of attack cost. We provide lower/upper bounds on the attack cost, and instantiate our attacks in two settings: (i) an offline setting where the agent is doing planning in the poisoned environment, and (ii) an online setting where the agent is learning a policy with poisoned feedback. Our results show that the attacker can easily succeed in teaching any target policy to the victim under mild conditions and highlight a significant security threat to reinforcement learning agents in practice.
Policy Teaching via Environment Poisoning: Training-time Adversarial Attacks against Reinforcement Learning
Mar 28, 2020
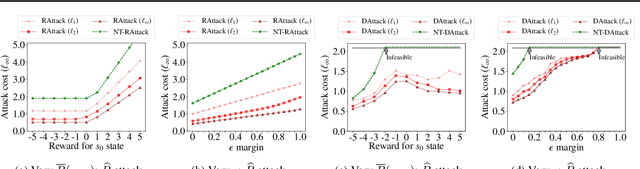
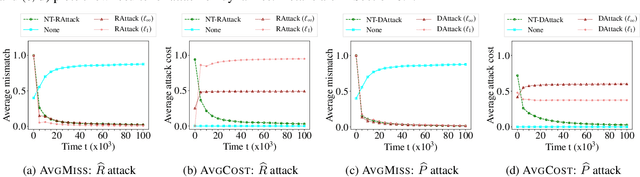
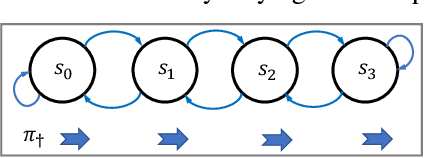
We study a security threat to reinforcement learning where an attacker poisons the learning environment to force the agent into executing a target policy chosen by the attacker. As a victim, we consider RL agents whose objective is to find a policy that maximizes average reward in undiscounted infinite-horizon problem settings. The attacker can manipulate the rewards or the transition dynamics in the learning environment at training-time and is interested in doing so in a stealthy manner. We propose an optimization framework for finding an \emph{optimal stealthy attack} for different measures of attack cost. We provide sufficient technical conditions under which the attack is feasible and provide lower/upper bounds on the attack cost. We instantiate our attacks in two settings: (i) an \emph{offline} setting where the agent is doing planning in the poisoned environment, and (ii) an \emph{online} setting where the agent is learning a policy using a regret-minimization framework with poisoned feedback. Our results show that the attacker can easily succeed in teaching any target policy to the victim under mild conditions and highlight a significant security threat to reinforcement learning agents in practice.