 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMaMa: A Game-Theoretic Approach for Designing Safe Agentic Systems
Feb 04, 2026LLM-based multi-agent systems have demonstrated impressive capabilities, but they also introduce significant safety risks when individual agents fail or behave adversarially. In this work, we study the automated design of agentic systems that remain safe even when a subset of agents is compromised. We formalize this challenge as a Stackelberg security game between a system designer (the Meta-Agent) and a best-responding Meta-Adversary that selects and compromises a subset of agents to minimize safety. We propose Meta-Adversary-Meta-Agent (MaMa), a novel algorithm for approximately solving this game and automatically designing safe agentic systems. Our approach uses LLM-based adversarial search, where the Meta-Agent iteratively proposes system designs and receives feedback based on the strongest attacks discovered by the Meta-Adversary. Empirical evaluations across diverse environments show that systems designed with MaMa consistently defend against worst-case attacks while maintaining performance comparable to systems optimized solely for task success. Moreover, the resulting systems generalize to stronger adversaries, as well as ones with different attack objectives or underlying LLMs, demonstrating robust safety beyond the training setting.
Sparse Offline Reinforcement Learning with Corruption Robustness
Dec 31, 2025We investigate robustness to strong data corruption in offline sparse reinforcement learning (RL). In our setting, an adversary may arbitrarily perturb a fraction of the collected trajectories from a high-dimensional but sparse Markov decision process, and our goal is to estimate a near optimal policy. The main challenge is that, in the high-dimensional regime where the number of samples $N$ is smaller than the feature dimension $d$, exploiting sparsity is essential for obtaining non-vacuous guarantees but has not been systematically studied in offline RL. We analyse the problem under uniform coverage and sparse single-concentrability assumptions. While Least Square Value Iteration (LSVI), a standard approach for robust offline RL, performs well under uniform coverage, we show that integrating sparsity into LSVI is unnatural, and its analysis may break down due to overly pessimistic bonuses. To overcome this, we propose actor-critic methods with sparse robust estimator oracles, which avoid the use of pointwise pessimistic bonuses and provide the first non-vacuous guarantees for sparse offline RL under single-policy concentrability coverage. Moreover, we extend our results to the contaminated setting and show that our algorithm remains robust under strong contamination. Our results provide the first non-vacuous guarantees in high-dimensional sparse MDPs with single-policy concentrability coverage and corruption, showing that learning a near-optimal policy remains possible in regimes where traditional robust offline RL techniques may fail.
On Corruption-Robustness in Performative Reinforcement Learning
May 08, 2025In performative Reinforcement Learning (RL), an agent faces a policy-dependent environment: the reward and transition functions depend on the agent's policy. Prior work on performative RL has studied the convergence of repeated retraining approaches to a performatively stable policy. In the finite sample regime, these approaches repeatedly solve for a saddle point of a convex-concave objective, which estimates the Lagrangian of a regularized version of the reinforcement learning problem. In this paper, we aim to extend such repeated retraining approaches, enabling them to operate under corrupted data. More specifically, we consider Huber's $\epsilon$-contamination model, where an $\epsilon$ fraction of data points is corrupted by arbitrary adversarial noise. We propose a repeated retraining approach based on convex-concave optimization under corrupted gradients and a novel problem-specific robust mean estimator for the gradients. We prove that our approach exhibits last-iterate convergence to an approximately stable policy, with the approximation error linear in $\sqrt{\epsilon}$. We experimentally demonstrate the importance of accounting for corruption in performative RL.
Performative Reinforcement Learning with Linear Markov Decision Process
Nov 07, 2024We study the setting of \emph{performative reinforcement learning} where the deployed policy affects both the reward, and the transition of the underlying Markov decision process. Prior work~\parencite{MTR23} has addressed this problem under the tabular setting and established last-iterate convergence of repeated retraining with iteration complexity explicitly depending on the number of states. In this work, we generalize the results to \emph{linear Markov decision processes} which is the primary theoretical model of large-scale MDPs. The main challenge with linear MDP is that the regularized objective is no longer strongly convex and we want a bound that scales with the dimension of the features, rather than states which can be infinite. Our first result shows that repeatedly optimizing a regularized objective converges to a \emph{performatively stable policy}. In the absence of strong convexity, our analysis leverages a new recurrence relation that uses a specific linear combination of optimal dual solutions for proving convergence. We then tackle the finite sample setting where the learner has access to a set of trajectories drawn from the current policy. We consider a reparametrized version of the primal problem, and construct an empirical Lagrangian which is to be optimized from the samples. We show that, under a \emph{bounded coverage} condition, repeatedly solving a saddle point of this empirical Lagrangian converges to a performatively stable solution, and also construct a primal-dual algorithm that solves the empirical Lagrangian efficiently. Finally, we show several applications of the general framework of performative RL including multi-agent systems.
Counterfactual Effect Decomposition in Multi-Agent Sequential Decision Making
Oct 16, 2024
We address the challenge of explaining counterfactual outcomes in multi-agent Markov decision processes. In particular, we aim to explain the total counterfactual effect of an agent's action on the outcome of a realized scenario through its influence on the environment dynamics and the agents' behavior. To achieve this, we introduce a novel causal explanation formula that decomposes the counterfactual effect by attributing to each agent and state variable a score reflecting their respective contributions to the effect. First, we show that the total counterfactual effect of an agent's action can be decomposed into two components: one measuring the effect that propagates through all subsequent agents' actions and another related to the effect that propagates through the state transitions. Building on recent advancements in causal contribution analysis, we further decompose these two effects as follows. For the former, we consider agent-specific effects -- a causal concept that quantifies the counterfactual effect of an agent's action that propagates through a subset of agents. Based on this notion, we use Shapley value to attribute the effect to individual agents. For the latter, we consider the concept of structure-preserving interventions and attribute the effect to state variables based on their "intrinsic" contributions. Through extensive experimentation, we demonstrate the interpretability of our decomposition approach in a Gridworld environment with LLM-assisted agents and a sepsis management simulator.
Reward Design for Justifiable Sequential Decision-Making
Feb 24, 2024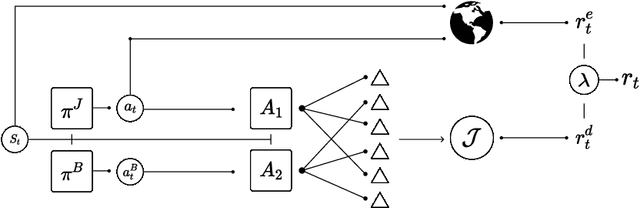
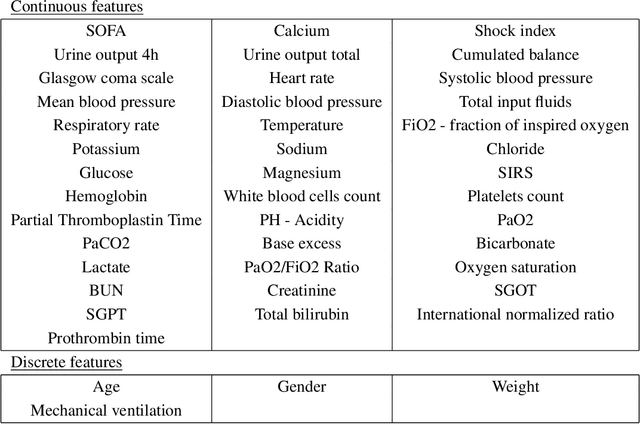
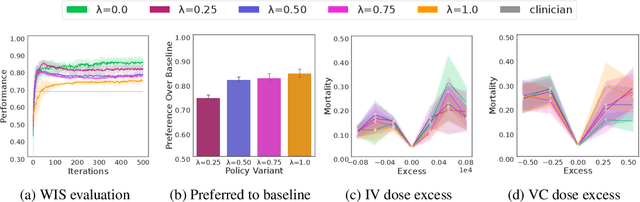
Equipping agents with the capacity to justify made decisions using supporting evidence represents a cornerstone of accountable decision-making. Furthermore, ensuring that justifications are in line with human expectations and societal norms is vital, especially in high-stakes situations such as healthcare. In this work, we propose the use of a debate-based reward model for reinforcement learning agents, where the outcome of a zero-sum debate game quantifies the justifiability of a decision in a particular state. This reward model is then used to train a justifiable policy, whose decisions can be more easily corroborated with supporting evidence. In the debate game, two argumentative agents take turns providing supporting evidence for two competing decisions. Given the proposed evidence, a proxy of a human judge evaluates which decision is better justified. We demonstrate the potential of our approach in learning policies for prescribing and justifying treatment decisions of septic patients. We show that augmenting the reward with the feedback signal generated by the debate-based reward model yields policies highly favored by the judge when compared to the policy obtained solely from the environment rewards, while hardly sacrificing any performance. Moreover, in terms of the overall performance and justifiability of trained policies, the debate-based feedback is comparable to the feedback obtained from an ideal judge proxy that evaluates decisions using the full information encoded in the state. This suggests that the debate game outputs key information contained in states that is most relevant for evaluating decisions, which in turn substantiates the practicality of combining our approach with human-in-the-loop evaluations. Lastly, we showcase that agents trained via multi-agent debate learn to propose evidence that is resilient to refutations and closely aligns with human preferences.
Performative Reinforcement Learning in Gradually Shifting Environments
Feb 15, 2024



When Reinforcement Learning (RL) agents are deployed in practice, they might impact their environment and change its dynamics. Ongoing research attempts to formally model this phenomenon and to analyze learning algorithms in these models. To this end, we propose a framework where the current environment depends on the deployed policy as well as its previous dynamics. This is a generalization of Performative RL (PRL) [Mandal et al., 2023]. Unlike PRL, our framework allows to model scenarios where the environment gradually adjusts to a deployed policy. We adapt two algorithms from the performative prediction literature to our setting and propose a novel algorithm called Mixed Delayed Repeated Retraining (MDRR). We provide conditions under which these algorithms converge and compare them using three metrics: number of retrainings, approximation guarantee, and number of samples per deployment. Unlike previous approaches, MDRR combines samples from multiple deployments in its training. This makes MDRR particularly suitable for scenarios where the environment's response strongly depends on its previous dynamics, which are common in practice. We experimentally compare the algorithms using a simulation-based testbed and our results show that MDRR converges significantly faster than previous approaches.
Agent-Specific Effects
Oct 17, 2023



Establishing causal relationships between actions and outcomes is fundamental for accountable multi-agent decision-making. However, interpreting and quantifying agents' contributions to such relationships pose significant challenges. These challenges are particularly prominent in the context of multi-agent sequential decision-making, where the causal effect of an agent's action on the outcome depends on how the other agents respond to that action. In this paper, our objective is to present a systematic approach for attributing the causal effects of agents' actions to the influence they exert on other agents. Focusing on multi-agent Markov decision processes, we introduce agent-specific effects (ASE), a novel causal quantity that measures the effect of an agent's action on the outcome that propagates through other agents. We then turn to the counterfactual counterpart of ASE (cf-ASE), provide a sufficient set of conditions for identifying cf-ASE, and propose a practical sampling-based algorithm for estimating it. Finally, we experimentally evaluate the utility of cf-ASE through a simulation-based testbed, which includes a sepsis management environment.
Markov Decision Processes with Time-Varying Geometric Discounting
Jul 19, 2023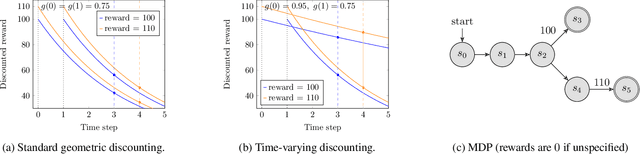

Canonical models of Markov decision processes (MDPs) usually consider geometric discounting based on a constant discount factor. While this standard modeling approach has led to many elegant results, some recent studies indicate the necessity of modeling time-varying discounting in certain applications. This paper studies a model of infinite-horizon MDPs with time-varying discount factors. We take a game-theoretic perspective -- whereby each time step is treated as an independent decision maker with their own (fixed) discount factor -- and we study the subgame perfect equilibrium (SPE) of the resulting game as well as the related algorithmic problems. We present a constructive proof of the existence of an SPE and demonstrate the EXPTIME-hardness of computing an SPE. We also turn to the approximate notion of $\epsilon$-SPE and show that an $\epsilon$-SPE exists under milder assumptions. An algorithm is presented to compute an $\epsilon$-SPE, of which an upper bound of the time complexity, as a function of the convergence property of the time-varying discount factor, is provided.
* 24 pages, 3 figures
Sequential Principal-Agent Problems with Communication: Efficient Computation and Learning
Jun 06, 2023
We study a sequential decision making problem between a principal and an agent with incomplete information on both sides. In this model, the principal and the agent interact in a stochastic environment, and each is privy to observations about the state not available to the other. The principal has the power of commitment, both to elicit information from the agent and to provide signals about her own information. The principal and the agent communicate their signals to each other, and select their actions independently based on this communication. Each player receives a payoff based on the state and their joint actions, and the environment moves to a new state. The interaction continues over a finite time horizon, and both players act to optimize their own total payoffs over the horizon. Our model encompasses as special cases stochastic games of incomplete information and POMDPs, as well as sequential Bayesian persuasion and mechanism design problems. We study both computation of optimal policies and learning in our setting. While the general problems are computationally intractable, we study algorithmic solutions under a conditional independence assumption on the underlying state-observation distributions. We present an polynomial-time algorithm to compute the principal's optimal policy up to an additive approximation. Additionally, we show an efficient learning algorithm in the case where the transition probabilities are not known beforehand. The algorithm guarantees sublinear regret for both players.