 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCounterfactual Effect Decomposition in Multi-Agent Sequential Decision Making
Oct 16, 2024
We address the challenge of explaining counterfactual outcomes in multi-agent Markov decision processes. In particular, we aim to explain the total counterfactual effect of an agent's action on the outcome of a realized scenario through its influence on the environment dynamics and the agents' behavior. To achieve this, we introduce a novel causal explanation formula that decomposes the counterfactual effect by attributing to each agent and state variable a score reflecting their respective contributions to the effect. First, we show that the total counterfactual effect of an agent's action can be decomposed into two components: one measuring the effect that propagates through all subsequent agents' actions and another related to the effect that propagates through the state transitions. Building on recent advancements in causal contribution analysis, we further decompose these two effects as follows. For the former, we consider agent-specific effects -- a causal concept that quantifies the counterfactual effect of an agent's action that propagates through a subset of agents. Based on this notion, we use Shapley value to attribute the effect to individual agents. For the latter, we consider the concept of structure-preserving interventions and attribute the effect to state variables based on their "intrinsic" contributions. Through extensive experimentation, we demonstrate the interpretability of our decomposition approach in a Gridworld environment with LLM-assisted agents and a sepsis management simulator.
Performative Reinforcement Learning in Gradually Shifting Environments
Feb 15, 2024



When Reinforcement Learning (RL) agents are deployed in practice, they might impact their environment and change its dynamics. Ongoing research attempts to formally model this phenomenon and to analyze learning algorithms in these models. To this end, we propose a framework where the current environment depends on the deployed policy as well as its previous dynamics. This is a generalization of Performative RL (PRL) [Mandal et al., 2023]. Unlike PRL, our framework allows to model scenarios where the environment gradually adjusts to a deployed policy. We adapt two algorithms from the performative prediction literature to our setting and propose a novel algorithm called Mixed Delayed Repeated Retraining (MDRR). We provide conditions under which these algorithms converge and compare them using three metrics: number of retrainings, approximation guarantee, and number of samples per deployment. Unlike previous approaches, MDRR combines samples from multiple deployments in its training. This makes MDRR particularly suitable for scenarios where the environment's response strongly depends on its previous dynamics, which are common in practice. We experimentally compare the algorithms using a simulation-based testbed and our results show that MDRR converges significantly faster than previous approaches.
Agent-Specific Effects
Oct 17, 2023



Establishing causal relationships between actions and outcomes is fundamental for accountable multi-agent decision-making. However, interpreting and quantifying agents' contributions to such relationships pose significant challenges. These challenges are particularly prominent in the context of multi-agent sequential decision-making, where the causal effect of an agent's action on the outcome depends on how the other agents respond to that action. In this paper, our objective is to present a systematic approach for attributing the causal effects of agents' actions to the influence they exert on other agents. Focusing on multi-agent Markov decision processes, we introduce agent-specific effects (ASE), a novel causal quantity that measures the effect of an agent's action on the outcome that propagates through other agents. We then turn to the counterfactual counterpart of ASE (cf-ASE), provide a sufficient set of conditions for identifying cf-ASE, and propose a practical sampling-based algorithm for estimating it. Finally, we experimentally evaluate the utility of cf-ASE through a simulation-based testbed, which includes a sepsis management environment.
Towards Computationally Efficient Responsibility Attribution in Decentralized Partially Observable MDPs
Feb 24, 2023



Responsibility attribution is a key concept of accountable multi-agent decision making. Given a sequence of actions, responsibility attribution mechanisms quantify the impact of each participating agent to the final outcome. One such popular mechanism is based on actual causality, and it assigns (causal) responsibility based on the actions that were found to be pivotal for the considered outcome. However, the inherent problem of pinpointing actual causes and consequently determining the exact responsibility assignment has shown to be computationally intractable. In this paper, we aim to provide a practical algorithmic solution to the problem of responsibility attribution under a computational budget. We first formalize the problem in the framework of Decentralized Partially Observable Markov Decision Processes (Dec-POMDPs) augmented by a specific class of Structural Causal Models (SCMs). Under this framework, we introduce a Monte Carlo Tree Search (MCTS) type of method which efficiently approximates the agents' degrees of responsibility. This method utilizes the structure of a novel search tree and a pruning technique, both tailored to the problem of responsibility attribution. Other novel components of our method are (a) a child selection policy based on linear scalarization and (b) a backpropagation procedure that accounts for a minimality condition that is typically used to define actual causality. We experimentally evaluate the efficacy of our algorithm through a simulation-based test-bed, which includes three team-based card games.
Performative Reinforcement Learning
Jun 30, 2022
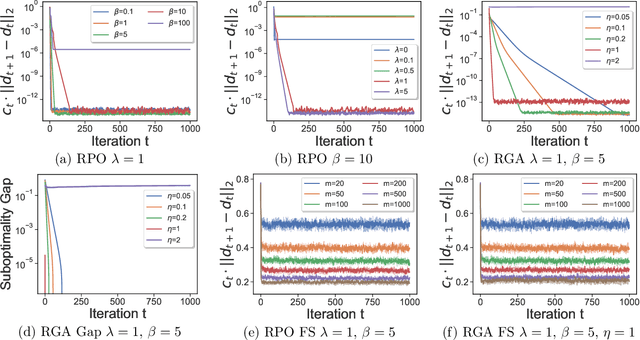

We introduce the framework of performative reinforcement learning where the policy chosen by the learner affects the underlying reward and transition dynamics of the environment. Following the recent literature on performative prediction~\cite{Perdomo et. al., 2020}, we introduce the concept of performatively stable policy. We then consider a regularized version of the reinforcement learning problem and show that repeatedly optimizing this objective converges to a performatively stable policy under reasonable assumptions on the transition dynamics. Our proof utilizes the dual perspective of the reinforcement learning problem and may be of independent interest in analyzing the convergence of other algorithms with decision-dependent environments. We then extend our results for the setting where the learner just performs gradient ascent steps instead of fully optimizing the objective, and for the setting where the learner has access to a finite number of trajectories from the changed environment. For both the settings, we leverage the dual formulation of performative reinforcement learning and establish convergence to a stable solution. Finally, through extensive experiments on a grid-world environment, we demonstrate the dependence of convergence on various parameters e.g. regularization, smoothness, and the number of samples.
Actual Causality and Responsibility Attribution in Decentralized Partially Observable Markov Decision Processes
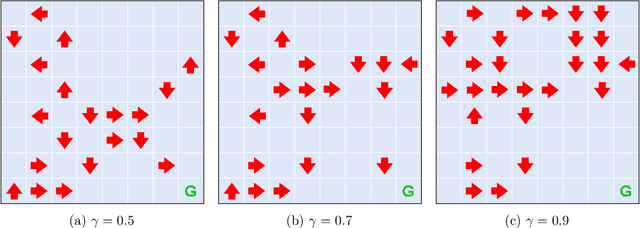
Apr 01, 2022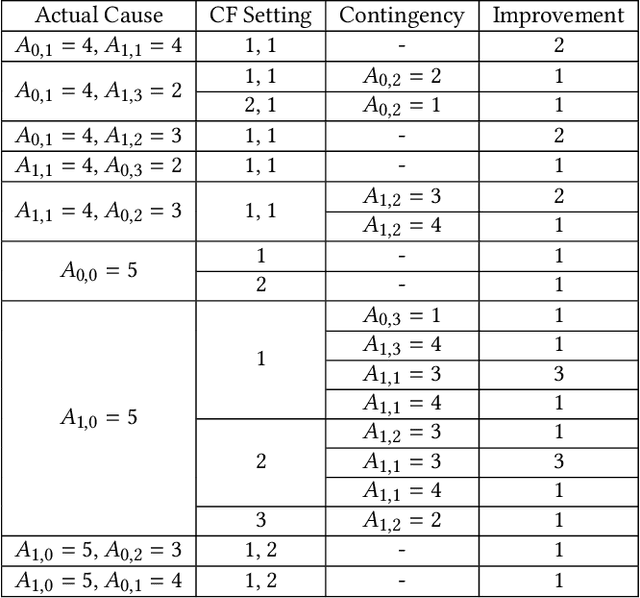
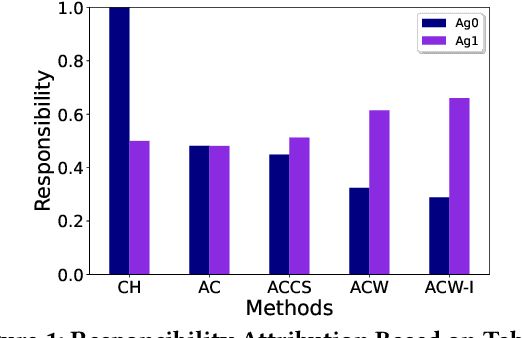
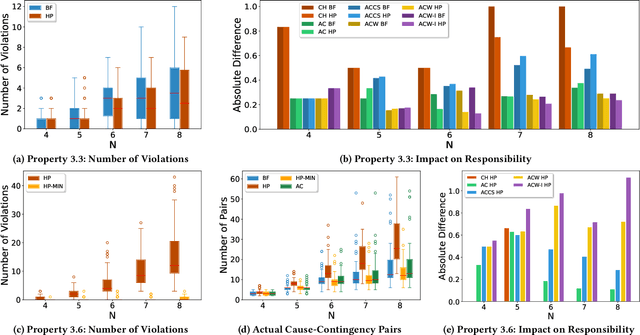
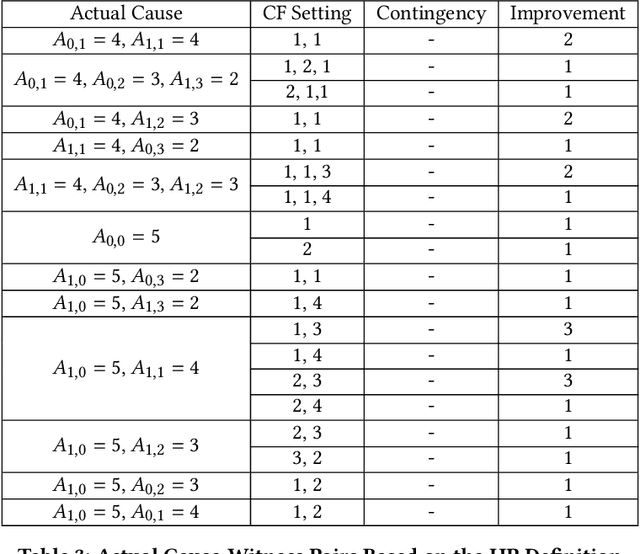
Actual causality and a closely related concept of responsibility attribution are central to accountable decision making. Actual causality focuses on specific outcomes and aims to identify decisions (actions) that were critical in realizing an outcome of interest. Responsibility attribution is complementary and aims to identify the extent to which decision makers (agents) are responsible for this outcome. In this paper, we study these concepts under a widely used framework for multi-agent sequential decision making under uncertainty: decentralized partially observable Markov decision processes (Dec-POMDPs). Following recent works in RL that show correspondence between POMDPs and Structural Causal Models (SCMs), we first establish a connection between Dec-POMDPs and SCMs. This connection enables us to utilize a language for describing actual causality from prior work and study existing definitions of actual causality in Dec-POMDPs. Given that some of the well-known definitions may lead to counter-intuitive actual causes, we introduce a novel definition that more explicitly accounts for causal dependencies between agents' actions. We then turn to responsibility attribution based on actual causality, where we argue that in ascribing responsibility to an agent it is important to consider both the number of actual causes in which the agent participates, as well as its ability to manipulate its own degree of responsibility. Motivated by these arguments we introduce a family of responsibility attribution methods that extends prior work, while accounting for the aforementioned considerations. Finally, through a simulation-based experiment, we compare different definitions of actual causality and responsibility attribution methods. The empirical results demonstrate the qualitative difference between the considered definitions of actual causality and their impact on attributed responsibility.
On Blame Attribution for Accountable Multi-Agent Sequential Decision Making
Jul 26, 2021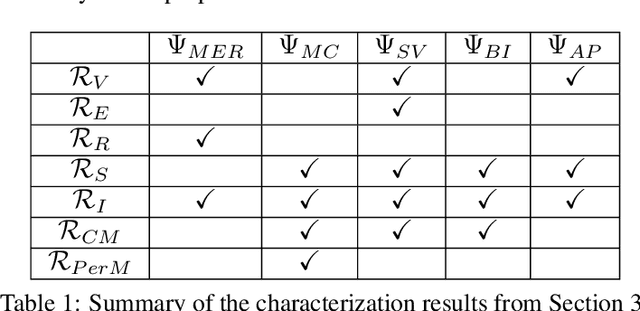
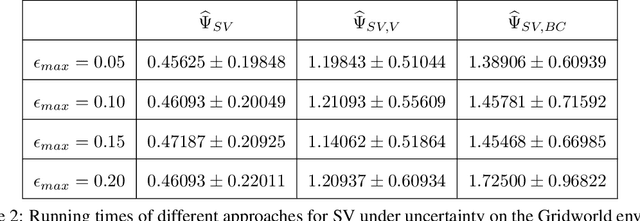
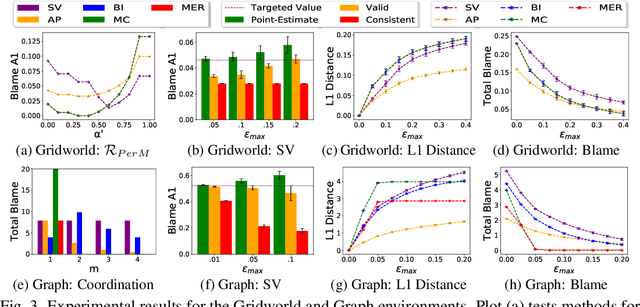
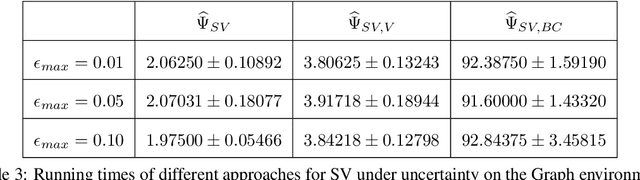
Blame attribution is one of the key aspects of accountable decision making, as it provides means to quantify the responsibility of an agent for a decision making outcome. In this paper, we study blame attribution in the context of cooperative multi-agent sequential decision making. As a particular setting of interest, we focus on cooperative decision making formalized by Multi-Agent Markov Decision Processes (MMDP), and we analyze different blame attribution methods derived from or inspired by existing concepts in cooperative game theory. We formalize desirable properties of blame attribution in the setting of interest, and we analyze the relationship between these properties and the studied blame attribution methods. Interestingly, we show that some of the well known blame attribution methods, such as Shapley value, are not performance-incentivizing, while others, such as Banzhaf index, may over-blame agents. To mitigate these value misalignment and fairness issues, we introduce a novel blame attribution method, unique in the set of properties it satisfies, which trade-offs explanatory power (by under-blaming agents) for the aforementioned properties. We further show how to account for uncertainty about agents' decision making policies, and we experimentally: a) validate the qualitative properties of the studied blame attribution methods, and b) analyze their robustness to uncertainty.