 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCounterfactual Effect Decomposition in Multi-Agent Sequential Decision Making
Oct 16, 2024
We address the challenge of explaining counterfactual outcomes in multi-agent Markov decision processes. In particular, we aim to explain the total counterfactual effect of an agent's action on the outcome of a realized scenario through its influence on the environment dynamics and the agents' behavior. To achieve this, we introduce a novel causal explanation formula that decomposes the counterfactual effect by attributing to each agent and state variable a score reflecting their respective contributions to the effect. First, we show that the total counterfactual effect of an agent's action can be decomposed into two components: one measuring the effect that propagates through all subsequent agents' actions and another related to the effect that propagates through the state transitions. Building on recent advancements in causal contribution analysis, we further decompose these two effects as follows. For the former, we consider agent-specific effects -- a causal concept that quantifies the counterfactual effect of an agent's action that propagates through a subset of agents. Based on this notion, we use Shapley value to attribute the effect to individual agents. For the latter, we consider the concept of structure-preserving interventions and attribute the effect to state variables based on their "intrinsic" contributions. Through extensive experimentation, we demonstrate the interpretability of our decomposition approach in a Gridworld environment with LLM-assisted agents and a sepsis management simulator.
Reward Design for Justifiable Sequential Decision-Making
Feb 24, 2024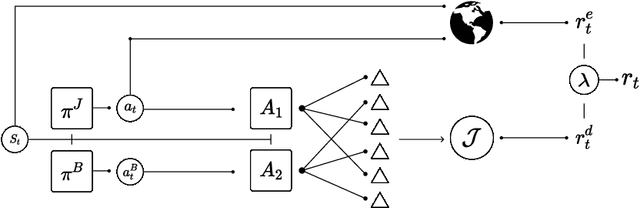
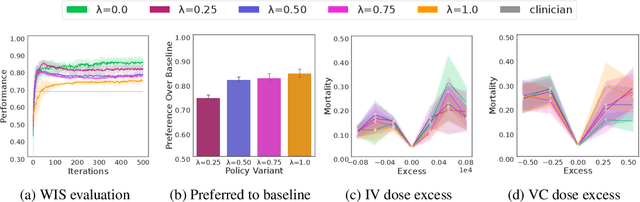
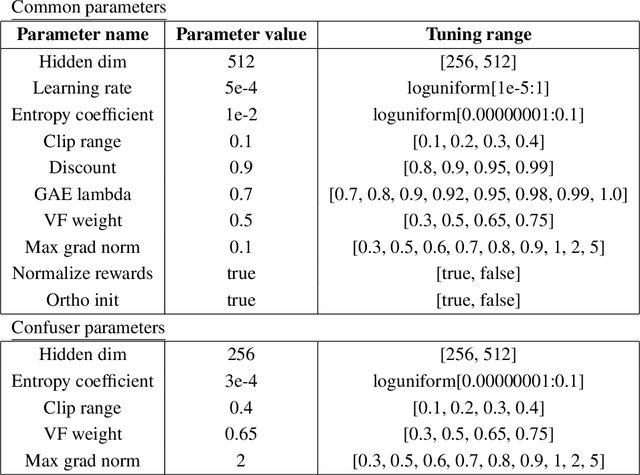
Equipping agents with the capacity to justify made decisions using supporting evidence represents a cornerstone of accountable decision-making. Furthermore, ensuring that justifications are in line with human expectations and societal norms is vital, especially in high-stakes situations such as healthcare. In this work, we propose the use of a debate-based reward model for reinforcement learning agents, where the outcome of a zero-sum debate game quantifies the justifiability of a decision in a particular state. This reward model is then used to train a justifiable policy, whose decisions can be more easily corroborated with supporting evidence. In the debate game, two argumentative agents take turns providing supporting evidence for two competing decisions. Given the proposed evidence, a proxy of a human judge evaluates which decision is better justified. We demonstrate the potential of our approach in learning policies for prescribing and justifying treatment decisions of septic patients. We show that augmenting the reward with the feedback signal generated by the debate-based reward model yields policies highly favored by the judge when compared to the policy obtained solely from the environment rewards, while hardly sacrificing any performance. Moreover, in terms of the overall performance and justifiability of trained policies, the debate-based feedback is comparable to the feedback obtained from an ideal judge proxy that evaluates decisions using the full information encoded in the state. This suggests that the debate game outputs key information contained in states that is most relevant for evaluating decisions, which in turn substantiates the practicality of combining our approach with human-in-the-loop evaluations. Lastly, we showcase that agents trained via multi-agent debate learn to propose evidence that is resilient to refutations and closely aligns with human preferences.
Agent-Specific Effects
Oct 17, 2023



Establishing causal relationships between actions and outcomes is fundamental for accountable multi-agent decision-making. However, interpreting and quantifying agents' contributions to such relationships pose significant challenges. These challenges are particularly prominent in the context of multi-agent sequential decision-making, where the causal effect of an agent's action on the outcome depends on how the other agents respond to that action. In this paper, our objective is to present a systematic approach for attributing the causal effects of agents' actions to the influence they exert on other agents. Focusing on multi-agent Markov decision processes, we introduce agent-specific effects (ASE), a novel causal quantity that measures the effect of an agent's action on the outcome that propagates through other agents. We then turn to the counterfactual counterpart of ASE (cf-ASE), provide a sufficient set of conditions for identifying cf-ASE, and propose a practical sampling-based algorithm for estimating it. Finally, we experimentally evaluate the utility of cf-ASE through a simulation-based testbed, which includes a sepsis management environment.