 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMarkov Decision Processes with Time-Varying Geometric Discounting
Paper and Code
Jul 19, 2023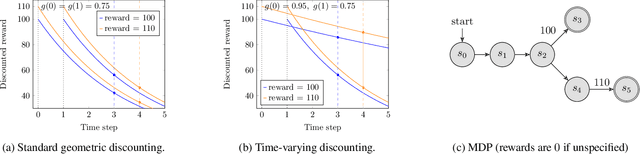

Canonical models of Markov decision processes (MDPs) usually consider geometric discounting based on a constant discount factor. While this standard modeling approach has led to many elegant results, some recent studies indicate the necessity of modeling time-varying discounting in certain applications. This paper studies a model of infinite-horizon MDPs with time-varying discount factors. We take a game-theoretic perspective -- whereby each time step is treated as an independent decision maker with their own (fixed) discount factor -- and we study the subgame perfect equilibrium (SPE) of the resulting game as well as the related algorithmic problems. We present a constructive proof of the existence of an SPE and demonstrate the EXPTIME-hardness of computing an SPE. We also turn to the approximate notion of $\epsilon$-SPE and show that an $\epsilon$-SPE exists under milder assumptions. An algorithm is presented to compute an $\epsilon$-SPE, of which an upper bound of the time complexity, as a function of the convergence property of the time-varying discount factor, is provided.