 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMaMa: A Game-Theoretic Approach for Designing Safe Agentic Systems
Feb 04, 2026LLM-based multi-agent systems have demonstrated impressive capabilities, but they also introduce significant safety risks when individual agents fail or behave adversarially. In this work, we study the automated design of agentic systems that remain safe even when a subset of agents is compromised. We formalize this challenge as a Stackelberg security game between a system designer (the Meta-Agent) and a best-responding Meta-Adversary that selects and compromises a subset of agents to minimize safety. We propose Meta-Adversary-Meta-Agent (MaMa), a novel algorithm for approximately solving this game and automatically designing safe agentic systems. Our approach uses LLM-based adversarial search, where the Meta-Agent iteratively proposes system designs and receives feedback based on the strongest attacks discovered by the Meta-Adversary. Empirical evaluations across diverse environments show that systems designed with MaMa consistently defend against worst-case attacks while maintaining performance comparable to systems optimized solely for task success. Moreover, the resulting systems generalize to stronger adversaries, as well as ones with different attack objectives or underlying LLMs, demonstrating robust safety beyond the training setting.
AgenticRed: Optimizing Agentic Systems for Automated Red-teaming
Jan 20, 2026While recent automated red-teaming methods show promise for systematically exposing model vulnerabilities, most existing approaches rely on human-specified workflows. This dependence on manually designed workflows suffers from human biases and makes exploring the broader design space expensive. We introduce AgenticRed, an automated pipeline that leverages LLMs' in-context learning to iteratively design and refine red-teaming systems without human intervention. Rather than optimizing attacker policies within predefined structures, AgenticRed treats red-teaming as a system design problem. Inspired by methods like Meta Agent Search, we develop a novel procedure for evolving agentic systems using evolutionary selection, and apply it to the problem of automatic red-teaming. Red-teaming systems designed by AgenticRed consistently outperform state-of-the-art approaches, achieving 96% attack success rate (ASR) on Llama-2-7B (36% improvement) and 98% on Llama-3-8B on HarmBench. Our approach exhibits strong transferability to proprietary models, achieving 100% ASR on GPT-3.5-Turbo and GPT-4o-mini, and 60% on Claude-Sonnet-3.5 (24% improvement). This work highlights automated system design as a powerful paradigm for AI safety evaluation that can keep pace with rapidly evolving models.
Policy Teaching via Data Poisoning in Learning from Human Preferences
Mar 13, 2025
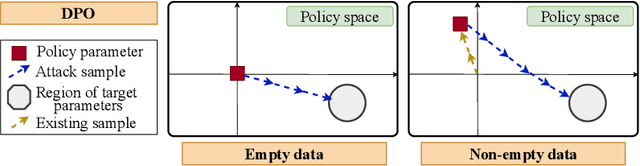
We study data poisoning attacks in learning from human preferences. More specifically, we consider the problem of teaching/enforcing a target policy $\pi^\dagger$ by synthesizing preference data. We seek to understand the susceptibility of different preference-based learning paradigms to poisoned preference data by analyzing the number of samples required by the attacker to enforce $\pi^\dagger$. We first propose a general data poisoning formulation in learning from human preferences and then study it for two popular paradigms, namely: (a) reinforcement learning from human feedback (RLHF) that operates by learning a reward model using preferences; (b) direct preference optimization (DPO) that directly optimizes policy using preferences. We conduct a theoretical analysis of the effectiveness of data poisoning in a setting where the attacker is allowed to augment a pre-existing dataset and also study its special case where the attacker can synthesize the entire preference dataset from scratch. As our main results, we provide lower/upper bounds on the number of samples required to enforce $\pi^\dagger$. Finally, we discuss the implications of our results in terms of the susceptibility of these learning paradigms under such data poisoning attacks.
Text-Diffusion Red-Teaming of Large Language Models: Unveiling Harmful Behaviors with Proximity Constraints
Jan 14, 2025Recent work has proposed automated red-teaming methods for testing the vulnerabilities of a given target large language model (LLM). These methods use red-teaming LLMs to uncover inputs that induce harmful behavior in a target LLM. In this paper, we study red-teaming strategies that enable a targeted security assessment. We propose an optimization framework for red-teaming with proximity constraints, where the discovered prompts must be similar to reference prompts from a given dataset. This dataset serves as a template for the discovered prompts, anchoring the search for test-cases to specific topics, writing styles, or types of harmful behavior. We show that established auto-regressive model architectures do not perform well in this setting. We therefore introduce a black-box red-teaming method inspired by text-diffusion models: Diffusion for Auditing and Red-Teaming (DART). DART modifies the reference prompt by perturbing it in the embedding space, directly controlling the amount of change introduced. We systematically evaluate our method by comparing its effectiveness with established methods based on model fine-tuning and zero- and few-shot prompting. Our results show that DART is significantly more effective at discovering harmful inputs in close proximity to the reference prompt.
Implicit Poisoning Attacks in Two-Agent Reinforcement Learning: Adversarial Policies for Training-Time Attacks
Feb 27, 2023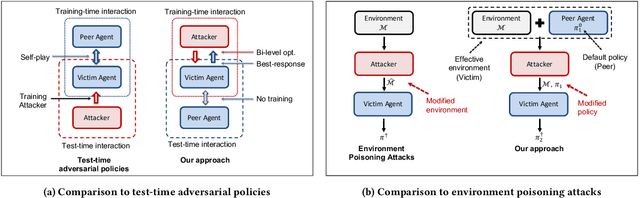

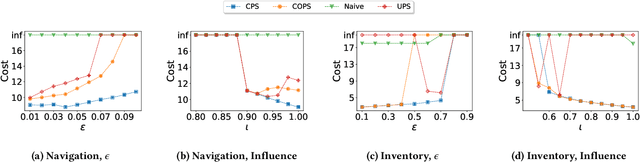
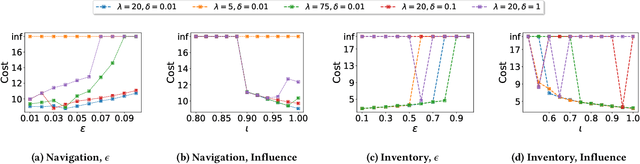
In targeted poisoning attacks, an attacker manipulates an agent-environment interaction to force the agent into adopting a policy of interest, called target policy. Prior work has primarily focused on attacks that modify standard MDP primitives, such as rewards or transitions. In this paper, we study targeted poisoning attacks in a two-agent setting where an attacker implicitly poisons the effective environment of one of the agents by modifying the policy of its peer. We develop an optimization framework for designing optimal attacks, where the cost of the attack measures how much the solution deviates from the assumed default policy of the peer agent. We further study the computational properties of this optimization framework. Focusing on a tabular setting, we show that in contrast to poisoning attacks based on MDP primitives (transitions and (unbounded) rewards), which are always feasible, it is NP-hard to determine the feasibility of implicit poisoning attacks. We provide characterization results that establish sufficient conditions for the feasibility of the attack problem, as well as an upper and a lower bound on the optimal cost of the attack. We propose two algorithmic approaches for finding an optimal adversarial policy: a model-based approach with tabular policies and a model-free approach with parametric/neural policies. We showcase the efficacy of the proposed algorithms through experiments.