 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Truncated Newton Method for Optimal Transport
Apr 02, 2025Developing a contemporary optimal transport (OT) solver requires navigating trade-offs among several critical requirements: GPU parallelization, scalability to high-dimensional problems, theoretical convergence guarantees, empirical performance in terms of precision versus runtime, and numerical stability in practice. With these challenges in mind, we introduce a specialized truncated Newton algorithm for entropic-regularized OT. In addition to proving that locally quadratic convergence is possible without assuming a Lipschitz Hessian, we provide strategies to maximally exploit the high rate of local convergence in practice. Our GPU-parallel algorithm exhibits exceptionally favorable runtime performance, achieving high precision orders of magnitude faster than many existing alternatives. This is evidenced by wall-clock time experiments on 24 problem sets (12 datasets $\times$ 2 cost functions). The scalability of the algorithm is showcased on an extremely large OT problem with $n \approx 10^6$, solved approximately under weak entopric regularization.
Maximum Entropy Model Correction in Reinforcement Learning
Nov 29, 2023We propose and theoretically analyze an approach for planning with an approximate model in reinforcement learning that can reduce the adverse impact of model error. If the model is accurate enough, it accelerates the convergence to the true value function too. One of its key components is the MaxEnt Model Correction (MoCo) procedure that corrects the model's next-state distributions based on a Maximum Entropy density estimation formulation. Based on MoCo, we introduce the Model Correcting Value Iteration (MoCoVI) algorithm, and its sampled-based variant MoCoDyna. We show that MoCoVI and MoCoDyna's convergence can be much faster than the conventional model-free algorithms. Unlike traditional model-based algorithms, MoCoVI and MoCoDyna effectively utilize an approximate model and still converge to the correct value function.
Efficient and Accurate Optimal Transport with Mirror Descent and Conjugate Gradients
Jul 17, 2023We design a novel algorithm for optimal transport by drawing from the entropic optimal transport, mirror descent and conjugate gradients literatures. Our algorithm is able to compute optimal transport costs with arbitrary accuracy without running into numerical stability issues. The algorithm is implemented efficiently on GPUs and is shown empirically to converge more quickly than traditional algorithms such as Sinkhorn's Algorithm both in terms of number of iterations and wall-clock time in many cases. We pay particular attention to the entropy of marginal distributions and show that high entropy marginals make for harder optimal transport problems, for which our algorithm is a good fit. We provide a careful ablation analysis with respect to algorithm and problem parameters, and present benchmarking over the MNIST dataset. The results suggest that our algorithm can be a useful addition to the practitioner's optimal transport toolkit. Our code is open-sourced at https://github.com/adaptive-agents-lab/MDOT-PNCG .
Trusted Approximate Policy Iteration with Bisimulation Metrics
Feb 06, 2022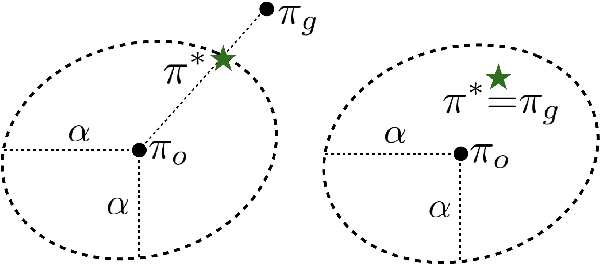
Bisimulation metrics define a distance measure between states of a Markov decision process (MDP) based on a comparison of reward sequences. Due to this property they provide theoretical guarantees in value function approximation. In this work we first prove that bisimulation metrics can be defined via any $p$-Wasserstein metric for $p\geq 1$. Then we describe an approximate policy iteration (API) procedure that uses $\epsilon$-aggregation with $\pi$-bisimulation and prove performance bounds for continuous state spaces. We bound the difference between $\pi$-bisimulation metrics in terms of the change in the policies themselves. Based on these theoretical results, we design an API($\alpha$) procedure that employs conservative policy updates and enjoys better performance bounds than the naive API approach. In addition, we propose a novel trust region approach which circumvents the requirement to explicitly solve a constrained optimization problem. Finally, we provide experimental evidence of improved stability compared to non-conservative alternatives in simulated continuous control.
Towards Robust Bisimulation Metric Learning
Oct 27, 2021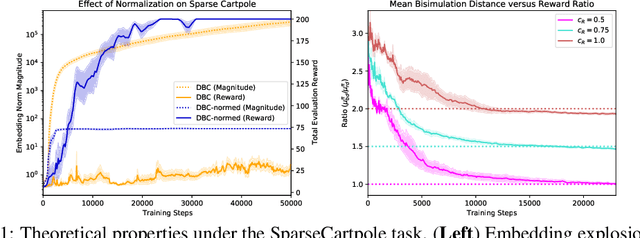

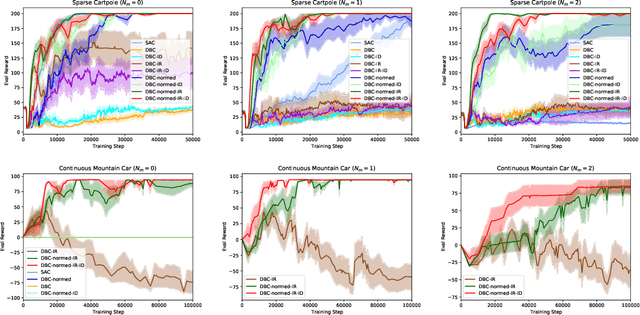
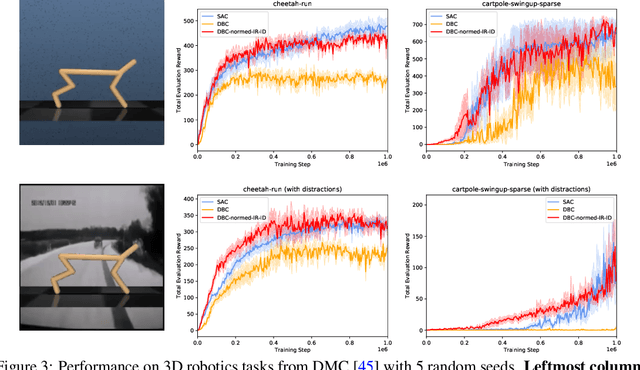
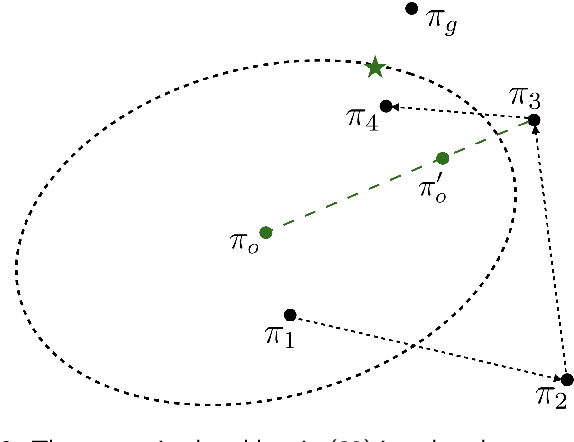
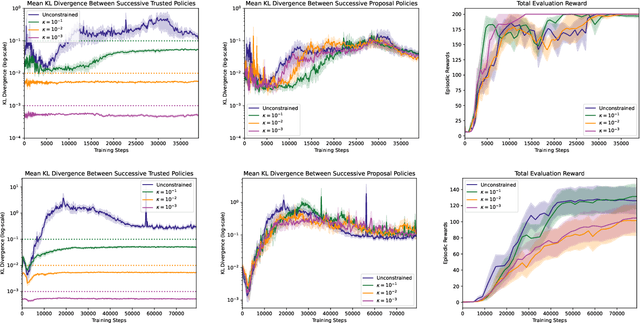
Learned representations in deep reinforcement learning (DRL) have to extract task-relevant information from complex observations, balancing between robustness to distraction and informativeness to the policy. Such stable and rich representations, often learned via modern function approximation techniques, can enable practical application of the policy improvement theorem, even in high-dimensional continuous state-action spaces. Bisimulation metrics offer one solution to this representation learning problem, by collapsing functionally similar states together in representation space, which promotes invariance to noise and distractors. In this work, we generalize value function approximation bounds for on-policy bisimulation metrics to non-optimal policies and approximate environment dynamics. Our theoretical results help us identify embedding pathologies that may occur in practical use. In particular, we find that these issues stem from an underconstrained dynamics model and an unstable dependence of the embedding norm on the reward signal in environments with sparse rewards. Further, we propose a set of practical remedies: (i) a norm constraint on the representation space, and (ii) an extension of prior approaches with intrinsic rewards and latent space regularization. Finally, we provide evidence that the resulting method is not only more robust to sparse reward functions, but also able to solve challenging continuous control tasks with observational distractions, where prior methods fail.
Dynamic Scheduling of MPI-based Distributed Deep Learning Training Jobs
Aug 21, 2019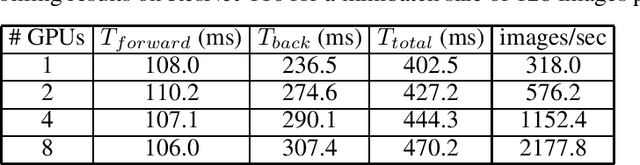
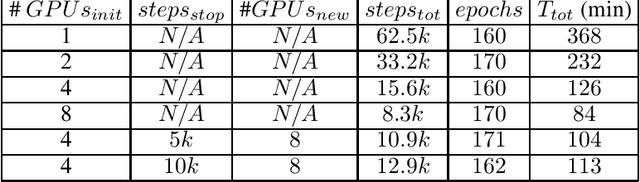
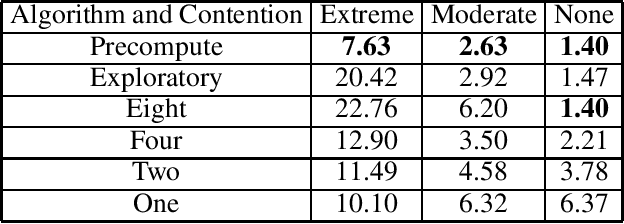
There is a general trend towards solving problems suited to deep learning with more complex deep learning architectures trained on larger training sets. This requires longer compute times and greater data parallelization or model parallelization. Both data and model parallelism have been historically faster in parameter server architectures, but data parallelism is starting to be faster in ring architectures due to algorithmic improvements. In this paper, we analyze the math behind ring architectures and make an informed adaptation of dynamic scheduling to ring architectures. To do so, we formulate a non-convex, non-linear, NP-hard integer programming problem and a new efficient doubling heuristic for its solution. We build upon Horovod: an open source ring architecture framework over TensorFlow. We show that Horovod jobs have a low cost to stop and restart and that stopping and restarting ring architecture jobs leads to faster completion times. These two facts make dynamic scheduling of ring architecture jobs feasible. Lastly, we simulate a scheduler using these runs and show a more than halving of average job time on some workload patterns.