 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic Scheduling of MPI-based Distributed Deep Learning Training Jobs
Paper and Code
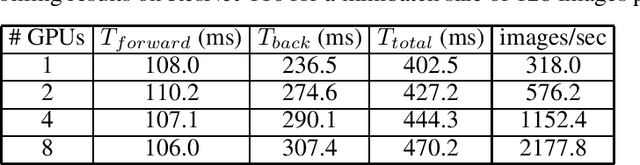
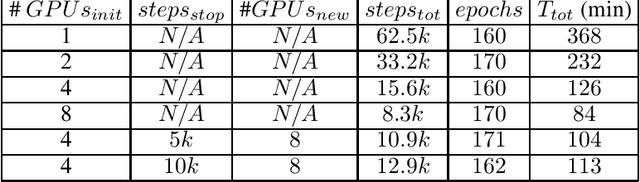
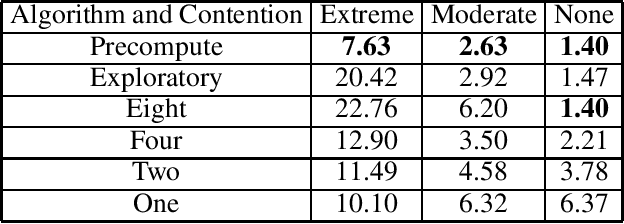
There is a general trend towards solving problems suited to deep learning with more complex deep learning architectures trained on larger training sets. This requires longer compute times and greater data parallelization or model parallelization. Both data and model parallelism have been historically faster in parameter server architectures, but data parallelism is starting to be faster in ring architectures due to algorithmic improvements. In this paper, we analyze the math behind ring architectures and make an informed adaptation of dynamic scheduling to ring architectures. To do so, we formulate a non-convex, non-linear, NP-hard integer programming problem and a new efficient doubling heuristic for its solution. We build upon Horovod: an open source ring architecture framework over TensorFlow. We show that Horovod jobs have a low cost to stop and restart and that stopping and restarting ring architecture jobs leads to faster completion times. These two facts make dynamic scheduling of ring architecture jobs feasible. Lastly, we simulate a scheduler using these runs and show a more than halving of average job time on some workload patterns.