 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFace2Scene: Using Facial Degradation as an Oracle for Diffusion-Based Scene Restoration
Mar 17, 2026Recent advances in image restoration have enabled high-fidelity recovery of faces from degraded inputs using reference-based face restoration models (Ref-FR). However, such methods focus solely on facial regions, neglecting degradation across the full scene, including body and background, which limits practical usability. Meanwhile, full-scene restorers often ignore degradation cues entirely, leading to underdetermined predictions and visual artifacts. In this work, we propose Face2Scene, a two-stage restoration framework that leverages the face as a perceptual oracle to estimate degradation and guide the restoration of the entire image. Given a degraded image and one or more identity references, we first apply a Ref-FR model to reconstruct high-quality facial details. From the restored-degraded face pair, we extract a face-derived degradation code that captures degradation attributes (e.g., noise, blur, compression), which is then transformed into multi-scale degradation-aware tokens. These tokens condition a diffusion model to restore the full scene in a single step, including the body and background. Extensive experiments demonstrate the superior effectiveness of the proposed method compared to state-of-the-art methods.
Qonvolution: Towards Learning High-Frequency Signals with Queried Convolution
Dec 15, 2025Accurately learning high-frequency signals is a challenge in computer vision and graphics, as neural networks often struggle with these signals due to spectral bias or optimization difficulties. While current techniques like Fourier encodings have made great strides in improving performance, there remains scope for improvement when presented with high-frequency information. This paper introduces Queried-Convolutions (Qonvolutions), a simple yet powerful modification using the neighborhood properties of convolution. Qonvolution convolves a low-frequency signal with queries (such as coordinates) to enhance the learning of intricate high-frequency signals. We empirically demonstrate that Qonvolutions enhance performance across a variety of high-frequency learning tasks crucial to both the computer vision and graphics communities, including 1D regression, 2D super-resolution, 2D image regression, and novel view synthesis (NVS). In particular, by combining Gaussian splatting with Qonvolutions for NVS, we showcase state-of-the-art performance on real-world complex scenes, even outperforming powerful radiance field models on image quality.
Augmenting Perceptual Super-Resolution via Image Quality Predictors
Apr 25, 2025



Super-resolution (SR), a classical inverse problem in computer vision, is inherently ill-posed, inducing a distribution of plausible solutions for every input. However, the desired result is not simply the expectation of this distribution, which is the blurry image obtained by minimizing pixelwise error, but rather the sample with the highest image quality. A variety of techniques, from perceptual metrics to adversarial losses, are employed to this end. In this work, we explore an alternative: utilizing powerful non-reference image quality assessment (NR-IQA) models in the SR context. We begin with a comprehensive analysis of NR-IQA metrics on human-derived SR data, identifying both the accuracy (human alignment) and complementarity of different metrics. Then, we explore two methods of applying NR-IQA models to SR learning: (i) altering data sampling, by building on an existing multi-ground-truth SR framework, and (ii) directly optimizing a differentiable quality score. Our results demonstrate a more human-centric perception-distortion tradeoff, focusing less on non-perceptual pixel-wise distortion, instead improving the balance between perceptual fidelity and human-tuned NR-IQA measures.
Learn Your Scales: Towards Scale-Consistent Generative Novel View Synthesis
Mar 19, 2025Conventional depth-free multi-view datasets are captured using a moving monocular camera without metric calibration. The scales of camera positions in this monocular setting are ambiguous. Previous methods have acknowledged scale ambiguity in multi-view data via various ad-hoc normalization pre-processing steps, but have not directly analyzed the effect of incorrect scene scales on their application. In this paper, we seek to understand and address the effect of scale ambiguity when used to train generative novel view synthesis methods (GNVS). In GNVS, new views of a scene or object can be minimally synthesized given a single image and are, thus, unconstrained, necessitating the use of generative methods. The generative nature of these models captures all aspects of uncertainty, including any uncertainty of scene scales, which act as nuisance variables for the task. We study the effect of scene scale ambiguity in GNVS when sampled from a single image by isolating its effect on the resulting models and, based on these intuitions, define new metrics that measure the scale inconsistency of generated views. We then propose a framework to estimate scene scales jointly with the GNVS model in an end-to-end fashion. Empirically, we show that our method reduces the scale inconsistency of generated views without the complexity or downsides of previous scale normalization methods. Further, we show that removing this ambiguity improves generated image quality of the resulting GNVS model.
Geometry-Aware Diffusion Models for Multiview Scene Inpainting
Feb 18, 2025In this paper, we focus on 3D scene inpainting, where parts of an input image set, captured from different viewpoints, are masked out. The main challenge lies in generating plausible image completions that are geometrically consistent across views. Most recent work addresses this challenge by combining generative models with a 3D radiance field to fuse information across viewpoints. However, a major drawback of these methods is that they often produce blurry images due to the fusion of inconsistent cross-view images. To avoid blurry inpaintings, we eschew the use of an explicit or implicit radiance field altogether and instead fuse cross-view information in a learned space. In particular, we introduce a geometry-aware conditional generative model, capable of inpainting multi-view consistent images based on both geometric and appearance cues from reference images. A key advantage of our approach over existing methods is its unique ability to inpaint masked scenes with a limited number of views (i.e., few-view inpainting), whereas previous methods require relatively large image sets for their 3D model fitting step. Empirically, we evaluate and compare our scene-centric inpainting method on two datasets, SPIn-NeRF and NeRFiller, which contain images captured at narrow and wide baselines, respectively, and achieve state-of-the-art 3D inpainting performance on both. Additionally, we demonstrate the efficacy of our approach in the few-view setting compared to prior methods.
Probabilistic Directed Distance Fields for Ray-Based Shape Representations
Apr 13, 2024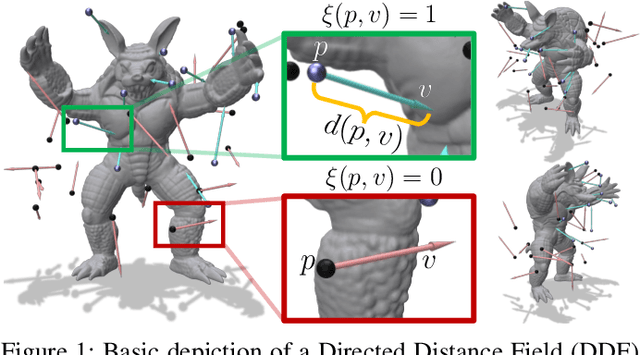

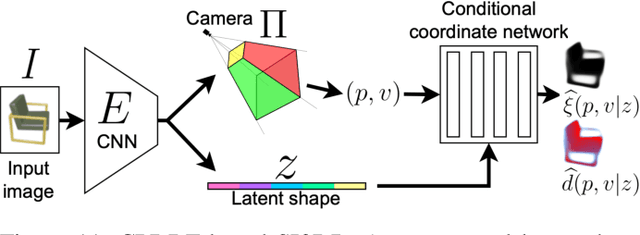

In modern computer vision, the optimal representation of 3D shape continues to be task-dependent. One fundamental operation applied to such representations is differentiable rendering, as it enables inverse graphics approaches in learning frameworks. Standard explicit shape representations (voxels, point clouds, or meshes) are often easily rendered, but can suffer from limited geometric fidelity, among other issues. On the other hand, implicit representations (occupancy, distance, or radiance fields) preserve greater fidelity, but suffer from complex or inefficient rendering processes, limiting scalability. In this work, we devise Directed Distance Fields (DDFs), a novel neural shape representation that builds upon classical distance fields. The fundamental operation in a DDF maps an oriented point (position and direction) to surface visibility and depth. This enables efficient differentiable rendering, obtaining depth with a single forward pass per pixel, as well as differential geometric quantity extraction (e.g., surface normals), with only additional backward passes. Using probabilistic DDFs (PDDFs), we show how to model inherent discontinuities in the underlying field. We then apply DDFs to several applications, including single-shape fitting, generative modelling, and single-image 3D reconstruction, showcasing strong performance with simple architectural components via the versatility of our representation. Finally, since the dimensionality of DDFs permits view-dependent geometric artifacts, we conduct a theoretical investigation of the constraints necessary for view consistency. We find a small set of field properties that are sufficient to guarantee a DDF is consistent, without knowing, for instance, which shape the field is expressing.
PolyOculus: Simultaneous Multi-view Image-based Novel View Synthesis
Feb 28, 2024
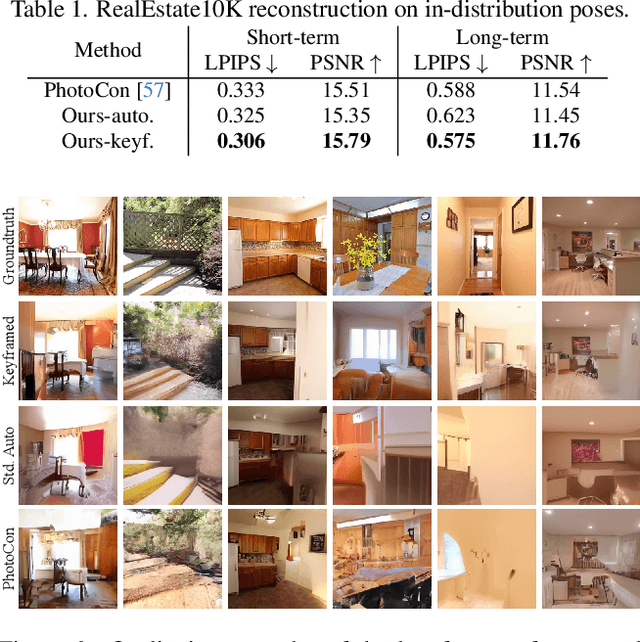
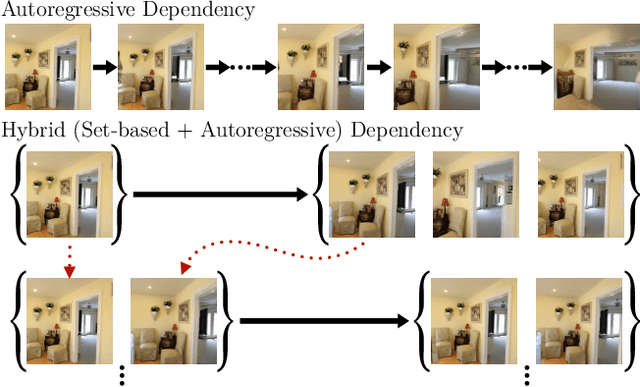

This paper considers the problem of generative novel view synthesis (GNVS), generating novel, plausible views of a scene given a limited number of known views. Here, we propose a set-based generative model that can simultaneously generate multiple, self-consistent new views, conditioned on any number of known views. Our approach is not limited to generating a single image at a time and can condition on zero, one, or more views. As a result, when generating a large number of views, our method is not restricted to a low-order autoregressive generation approach and is better able to maintain generated image quality over large sets of images. We evaluate the proposed model on standard NVS datasets and show that it outperforms the state-of-the-art image-based GNVS baselines. Further, we show that the model is capable of generating sets of camera views that have no natural sequential ordering, like loops and binocular trajectories, and significantly outperforms other methods on such tasks.
Reconstructive Latent-Space Neural Radiance Fields for Efficient 3D Scene Representations
Oct 27, 2023



Neural Radiance Fields (NeRFs) have proven to be powerful 3D representations, capable of high quality novel view synthesis of complex scenes. While NeRFs have been applied to graphics, vision, and robotics, problems with slow rendering speed and characteristic visual artifacts prevent adoption in many use cases. In this work, we investigate combining an autoencoder (AE) with a NeRF, in which latent features (instead of colours) are rendered and then convolutionally decoded. The resulting latent-space NeRF can produce novel views with higher quality than standard colour-space NeRFs, as the AE can correct certain visual artifacts, while rendering over three times faster. Our work is orthogonal to other techniques for improving NeRF efficiency. Further, we can control the tradeoff between efficiency and image quality by shrinking the AE architecture, achieving over 13 times faster rendering with only a small drop in performance. We hope that our approach can form the basis of an efficient, yet high-fidelity, 3D scene representation for downstream tasks, especially when retaining differentiability is useful, as in many robotics scenarios requiring continual learning.
Watch Your Steps: Local Image and Scene Editing by Text Instructions
Aug 17, 2023Denoising diffusion models have enabled high-quality image generation and editing. We present a method to localize the desired edit region implicit in a text instruction. We leverage InstructPix2Pix (IP2P) and identify the discrepancy between IP2P predictions with and without the instruction. This discrepancy is referred to as the relevance map. The relevance map conveys the importance of changing each pixel to achieve the edits, and is used to to guide the modifications. This guidance ensures that the irrelevant pixels remain unchanged. Relevance maps are further used to enhance the quality of text-guided editing of 3D scenes in the form of neural radiance fields. A field is trained on relevance maps of training views, denoted as the relevance field, defining the 3D region within which modifications should be made. We perform iterative updates on the training views guided by rendered relevance maps from the relevance field. Our method achieves state-of-the-art performance on both image and NeRF editing tasks. Project page: https://ashmrz.github.io/WatchYourSteps/
Reference-guided Controllable Inpainting of Neural Radiance Fields
Apr 20, 2023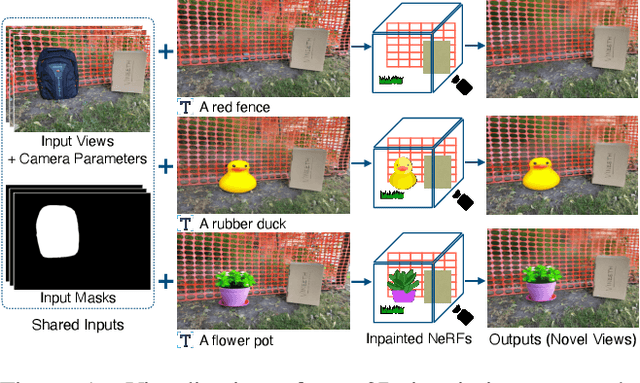
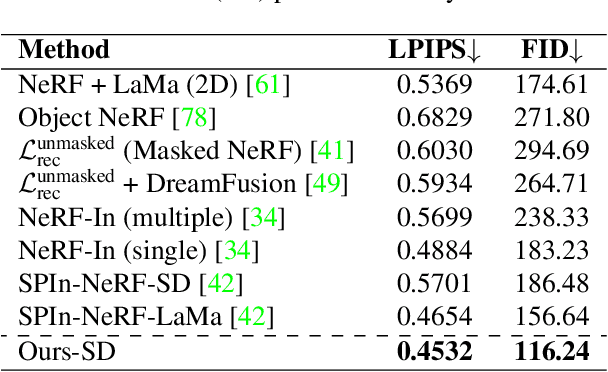

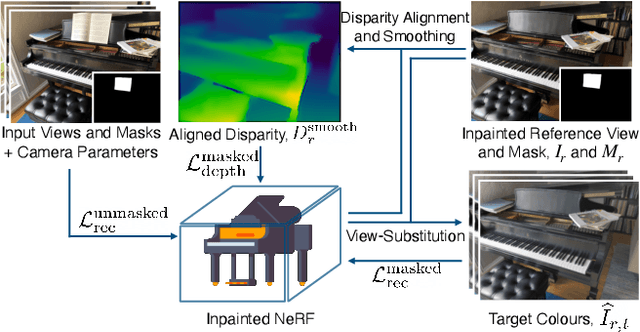
The popularity of Neural Radiance Fields (NeRFs) for view synthesis has led to a desire for NeRF editing tools. Here, we focus on inpainting regions in a view-consistent and controllable manner. In addition to the typical NeRF inputs and masks delineating the unwanted region in each view, we require only a single inpainted view of the scene, i.e., a reference view. We use monocular depth estimators to back-project the inpainted view to the correct 3D positions. Then, via a novel rendering technique, a bilateral solver can construct view-dependent effects in non-reference views, making the inpainted region appear consistent from any view. For non-reference disoccluded regions, which cannot be supervised by the single reference view, we devise a method based on image inpainters to guide both the geometry and appearance. Our approach shows superior performance to NeRF inpainting baselines, with the additional advantage that a user can control the generated scene via a single inpainted image. Project page: https://ashmrz.github.io/reference-guided-3d