 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeometry-Aware Diffusion Models for Multiview Scene Inpainting
Feb 18, 2025In this paper, we focus on 3D scene inpainting, where parts of an input image set, captured from different viewpoints, are masked out. The main challenge lies in generating plausible image completions that are geometrically consistent across views. Most recent work addresses this challenge by combining generative models with a 3D radiance field to fuse information across viewpoints. However, a major drawback of these methods is that they often produce blurry images due to the fusion of inconsistent cross-view images. To avoid blurry inpaintings, we eschew the use of an explicit or implicit radiance field altogether and instead fuse cross-view information in a learned space. In particular, we introduce a geometry-aware conditional generative model, capable of inpainting multi-view consistent images based on both geometric and appearance cues from reference images. A key advantage of our approach over existing methods is its unique ability to inpaint masked scenes with a limited number of views (i.e., few-view inpainting), whereas previous methods require relatively large image sets for their 3D model fitting step. Empirically, we evaluate and compare our scene-centric inpainting method on two datasets, SPIn-NeRF and NeRFiller, which contain images captured at narrow and wide baselines, respectively, and achieve state-of-the-art 3D inpainting performance on both. Additionally, we demonstrate the efficacy of our approach in the few-view setting compared to prior methods.
LAP: An Attention-Based Module for Faithful Interpretation and Knowledge Injection in Convolutional Neural Networks
Jan 27, 2022

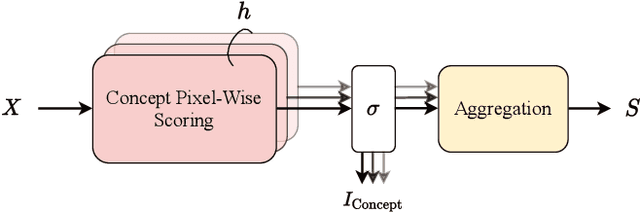

Despite the state-of-the-art performance of deep convolutional neural networks, they are susceptible to bias and malfunction in unseen situations. The complex computation behind their reasoning is not sufficiently human-understandable to develop trust. External explainer methods have tried to interpret the network decisions in a human-understandable way, but they are accused of fallacies due to their assumptions and simplifications. On the other side, the inherent self-interpretability of models, while being more robust to the mentioned fallacies, cannot be applied to the already trained models. In this work, we propose a new attention-based pooling layer, called Local Attention Pooling (LAP), that accomplishes self-interpretability and the possibility for knowledge injection while improving the model's performance. Moreover, several weakly-supervised knowledge injection methodologies are provided to enhance the process of training. We verified our claims by evaluating several LAP-extended models on three different datasets, including Imagenet. The proposed framework offers more valid human-understandable and more faithful-to-the-model interpretations than the commonly used white-box explainer methods.