 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProbabilistic Directed Distance Fields for Ray-Based Shape Representations
Apr 13, 2024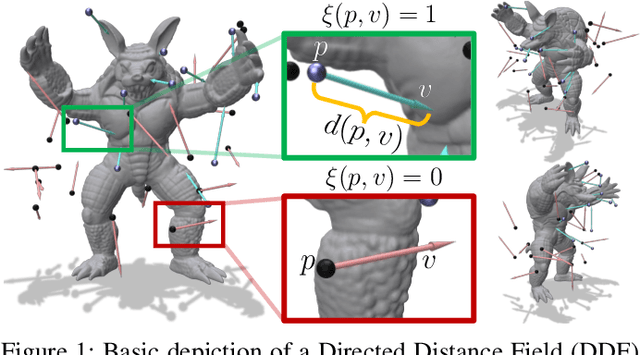

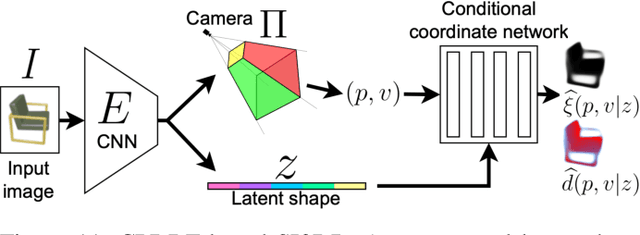

In modern computer vision, the optimal representation of 3D shape continues to be task-dependent. One fundamental operation applied to such representations is differentiable rendering, as it enables inverse graphics approaches in learning frameworks. Standard explicit shape representations (voxels, point clouds, or meshes) are often easily rendered, but can suffer from limited geometric fidelity, among other issues. On the other hand, implicit representations (occupancy, distance, or radiance fields) preserve greater fidelity, but suffer from complex or inefficient rendering processes, limiting scalability. In this work, we devise Directed Distance Fields (DDFs), a novel neural shape representation that builds upon classical distance fields. The fundamental operation in a DDF maps an oriented point (position and direction) to surface visibility and depth. This enables efficient differentiable rendering, obtaining depth with a single forward pass per pixel, as well as differential geometric quantity extraction (e.g., surface normals), with only additional backward passes. Using probabilistic DDFs (PDDFs), we show how to model inherent discontinuities in the underlying field. We then apply DDFs to several applications, including single-shape fitting, generative modelling, and single-image 3D reconstruction, showcasing strong performance with simple architectural components via the versatility of our representation. Finally, since the dimensionality of DDFs permits view-dependent geometric artifacts, we conduct a theoretical investigation of the constraints necessary for view consistency. We find a small set of field properties that are sufficient to guarantee a DDF is consistent, without knowing, for instance, which shape the field is expressing.
Efficient Flow-Guided Multi-frame De-fencing
Jan 25, 2023


Taking photographs ''in-the-wild'' is often hindered by fence obstructions that stand between the camera user and the scene of interest, and which are hard or impossible to avoid. De-fencing is the algorithmic process of automatically removing such obstructions from images, revealing the invisible parts of the scene. While this problem can be formulated as a combination of fence segmentation and image inpainting, this often leads to implausible hallucinations of the occluded regions. Existing multi-frame approaches rely on propagating information to a selected keyframe from its temporal neighbors, but they are often inefficient and struggle with alignment of severely obstructed images. In this work we draw inspiration from the video completion literature and develop a simplified framework for multi-frame de-fencing that computes high quality flow maps directly from obstructed frames and uses them to accurately align frames. Our primary focus is efficiency and practicality in a real-world setting: the input to our algorithm is a short image burst (5 frames) - a data modality commonly available in modern smartphones - and the output is a single reconstructed keyframe, with the fence removed. Our approach leverages simple yet effective CNN modules, trained on carefully generated synthetic data, and outperforms more complicated alternatives real bursts, both quantitatively and qualitatively, while running real-time.
* 16 pages, 12 figures. Published at the Winter Conference on Application of Computer Vision (WACV) 2023
Uncertainty-based Cross-Modal Retrieval with Probabilistic Representations
Apr 20, 2022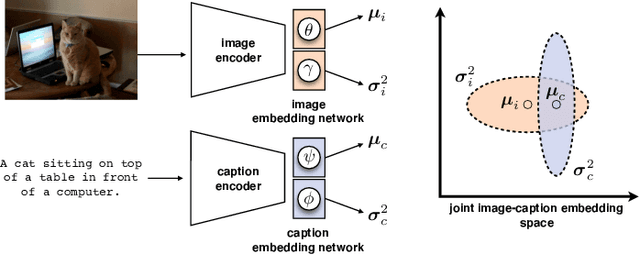
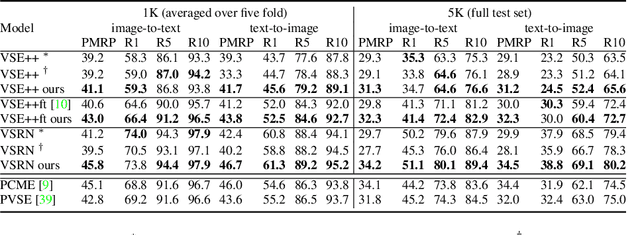
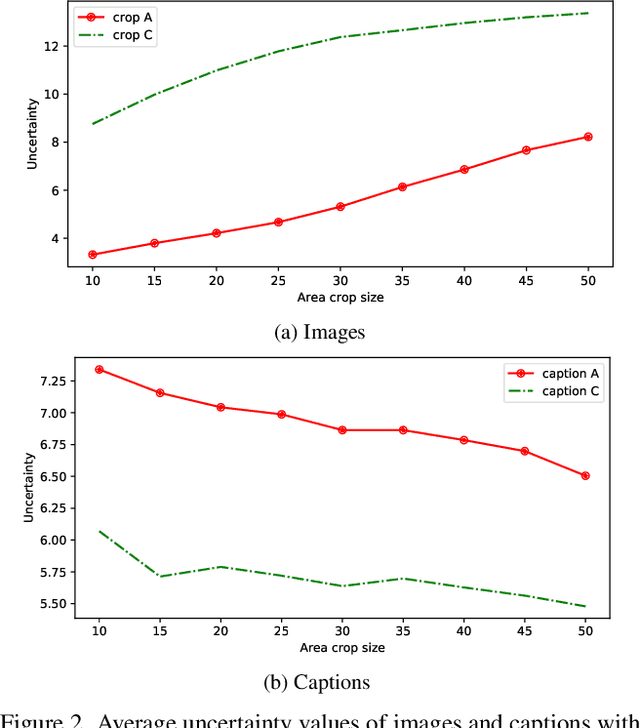
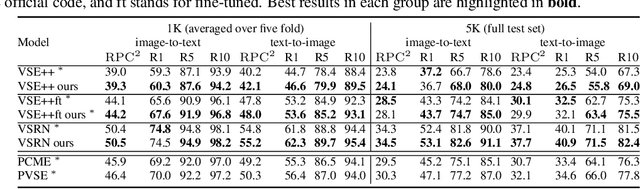
Probabilistic embeddings have proven useful for capturing polysemous word meanings, as well as ambiguity in image matching. In this paper, we study the advantages of probabilistic embeddings in a cross-modal setting (i.e., text and images), and propose a simple approach that replaces the standard vector point embeddings in extant image-text matching models with probabilistic distributions that are parametrically learned. Our guiding hypothesis is that the uncertainty encoded in the probabilistic embeddings captures the cross-modal ambiguity in the input instances, and that it is through capturing this uncertainty that the probabilistic models can perform better at downstream tasks, such as image-to-text or text-to-image retrieval. Through extensive experiments on standard and new benchmarks, we show a consistent advantage for probabilistic representations in cross-modal retrieval, and validate the ability of our embeddings to capture uncertainty.
Trusted Approximate Policy Iteration with Bisimulation Metrics
Feb 06, 2022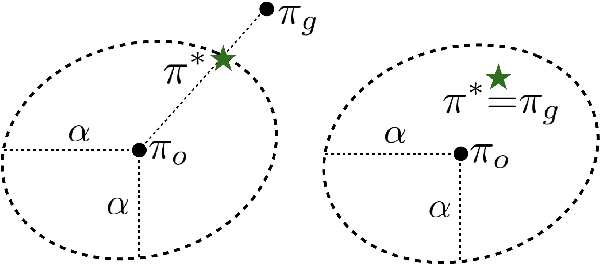
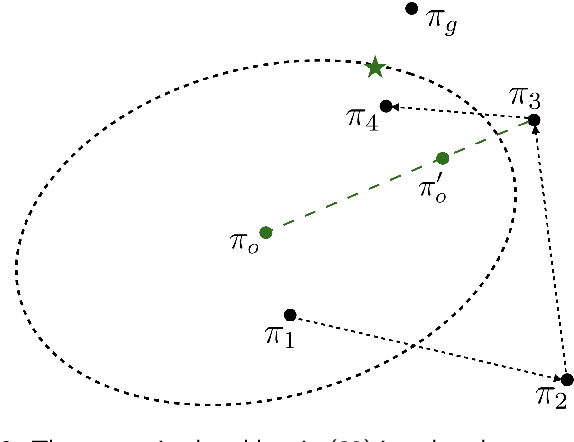
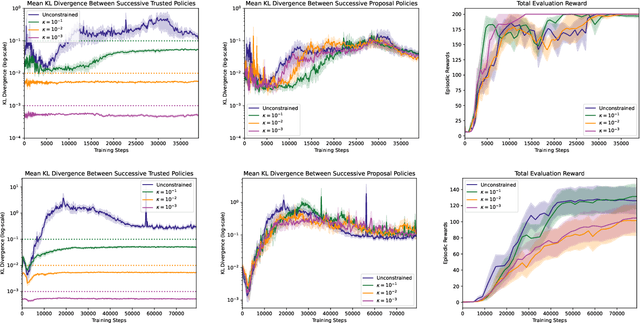
Bisimulation metrics define a distance measure between states of a Markov decision process (MDP) based on a comparison of reward sequences. Due to this property they provide theoretical guarantees in value function approximation. In this work we first prove that bisimulation metrics can be defined via any $p$-Wasserstein metric for $p\geq 1$. Then we describe an approximate policy iteration (API) procedure that uses $\epsilon$-aggregation with $\pi$-bisimulation and prove performance bounds for continuous state spaces. We bound the difference between $\pi$-bisimulation metrics in terms of the change in the policies themselves. Based on these theoretical results, we design an API($\alpha$) procedure that employs conservative policy updates and enjoys better performance bounds than the naive API approach. In addition, we propose a novel trust region approach which circumvents the requirement to explicitly solve a constrained optimization problem. Finally, we provide experimental evidence of improved stability compared to non-conservative alternatives in simulated continuous control.
Representing 3D Shapes with Probabilistic Directed Distance Fields
Dec 10, 2021
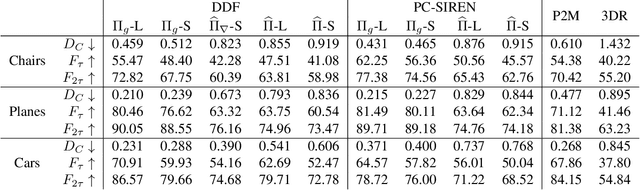
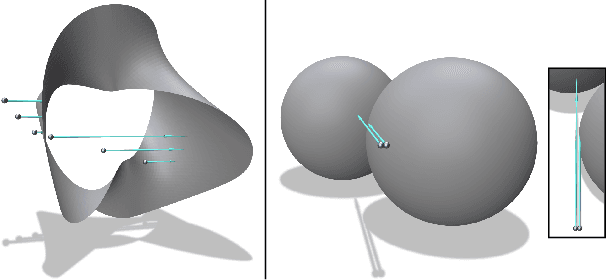
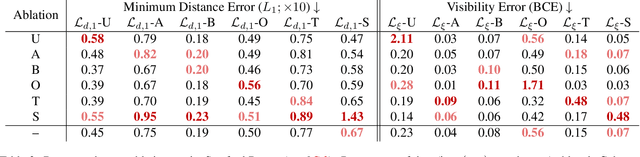
Differentiable rendering is an essential operation in modern vision, allowing inverse graphics approaches to 3D understanding to be utilized in modern machine learning frameworks. Explicit shape representations (voxels, point clouds, or meshes), while relatively easily rendered, often suffer from limited geometric fidelity or topological constraints. On the other hand, implicit representations (occupancy, distance, or radiance fields) preserve greater fidelity, but suffer from complex or inefficient rendering processes, limiting scalability. In this work, we endeavour to address both shortcomings with a novel shape representation that allows fast differentiable rendering within an implicit architecture. Building on implicit distance representations, we define Directed Distance Fields (DDFs), which map an oriented point (position and direction) to surface visibility and depth. Such a field can render a depth map with a single forward pass per pixel, enable differential surface geometry extraction (e.g., surface normals and curvatures) via network derivatives, be easily composed, and permit extraction of classical unsigned distance fields. Using probabilistic DDFs (PDDFs), we show how to model inherent discontinuities in the underlying field. Finally, we apply our method to fitting single shapes, unpaired 3D-aware generative image modelling, and single-image 3D reconstruction tasks, showcasing strong performance with simple architectural components via the versatility of our representation.
GraN-GAN: Piecewise Gradient Normalization for Generative Adversarial Networks
Nov 04, 2021



Modern generative adversarial networks (GANs) predominantly use piecewise linear activation functions in discriminators (or critics), including ReLU and LeakyReLU. Such models learn piecewise linear mappings, where each piece handles a subset of the input space, and the gradients per subset are piecewise constant. Under such a class of discriminator (or critic) functions, we present Gradient Normalization (GraN), a novel input-dependent normalization method, which guarantees a piecewise K-Lipschitz constraint in the input space. In contrast to spectral normalization, GraN does not constrain processing at the individual network layers, and, unlike gradient penalties, strictly enforces a piecewise Lipschitz constraint almost everywhere. Empirically, we demonstrate improved image generation performance across multiple datasets (incl. CIFAR-10/100, STL-10, LSUN bedrooms, and CelebA), GAN loss functions, and metrics. Further, we analyze altering the often untuned Lipschitz constant K in several standard GANs, not only attaining significant performance gains, but also finding connections between K and training dynamics, particularly in low-gradient loss plateaus, with the common Adam optimizer.
AppBuddy: Learning to Accomplish Tasks in Mobile Apps via Reinforcement Learning
Jun 06, 2021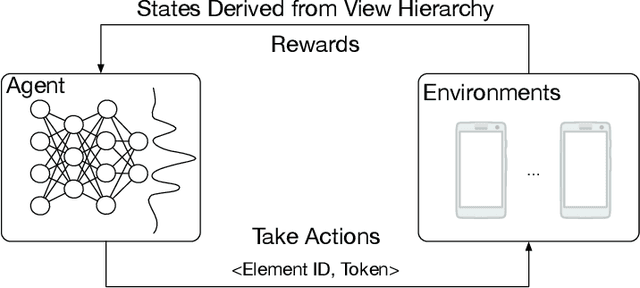
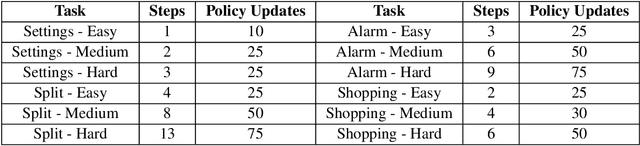
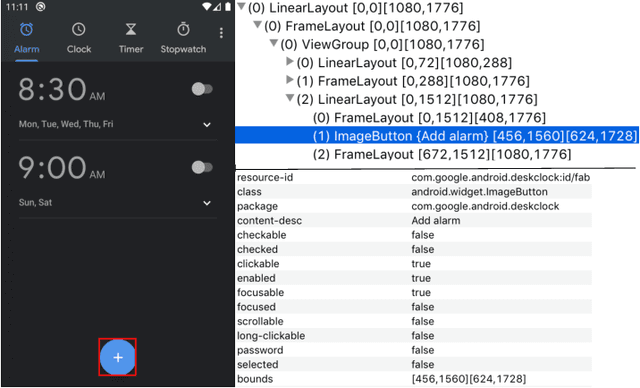

Human beings, even small children, quickly become adept at figuring out how to use applications on their mobile devices. Learning to use a new app is often achieved via trial-and-error, accelerated by transfer of knowledge from past experiences with like apps. The prospect of building a smarter smartphone - one that can learn how to achieve tasks using mobile apps - is tantalizing. In this paper we explore the use of Reinforcement Learning (RL) with the goal of advancing this aspiration. We introduce an RL-based framework for learning to accomplish tasks in mobile apps. RL agents are provided with states derived from the underlying representation of on-screen elements, and rewards that are based on progress made in the task. Agents can interact with screen elements by tapping or typing. Our experimental results, over a number of mobile apps, show that RL agents can learn to accomplish multi-step tasks, as well as achieve modest generalization across different apps. More generally, we develop a platform which addresses several engineering challenges to enable an effective RL training environment. Our AppBuddy platform is compatible with OpenAI Gym and includes a suite of mobile apps and benchmark tasks that supports a diversity of RL research in the mobile app setting.
Disentangling Geometric Deformation Spaces in Generative Latent Shape Models
Feb 27, 2021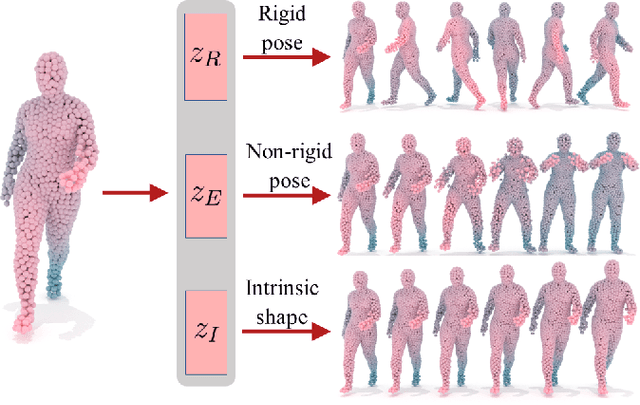

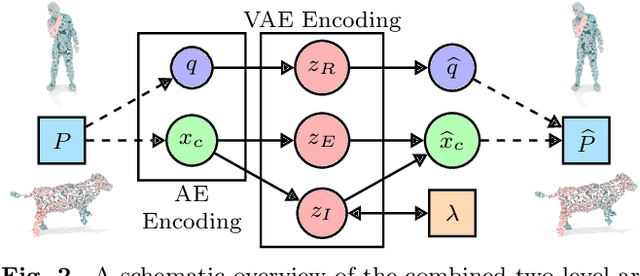

A complete representation of 3D objects requires characterizing the space of deformations in an interpretable manner, from articulations of a single instance to changes in shape across categories. In this work, we improve on a prior generative model of geometric disentanglement for 3D shapes, wherein the space of object geometry is factorized into rigid orientation, non-rigid pose, and intrinsic shape. The resulting model can be trained from raw 3D shapes, without correspondences, labels, or even rigid alignment, using a combination of classical spectral geometry and probabilistic disentanglement of a structured latent representation space. Our improvements include more sophisticated handling of rotational invariance and the use of a diffeomorphic flow network to bridge latent and spectral space. The geometric structuring of the latent space imparts an interpretable characterization of the deformation space of an object. Furthermore, it enables tasks like pose transfer and pose-aware retrieval without requiring supervision. We evaluate our model on its generative modelling, representation learning, and disentanglement performance, showing improved rotation invariance and intrinsic-extrinsic factorization quality over the prior model.
AIM 2020 Challenge on Efficient Super-Resolution: Methods and Results
Sep 15, 2020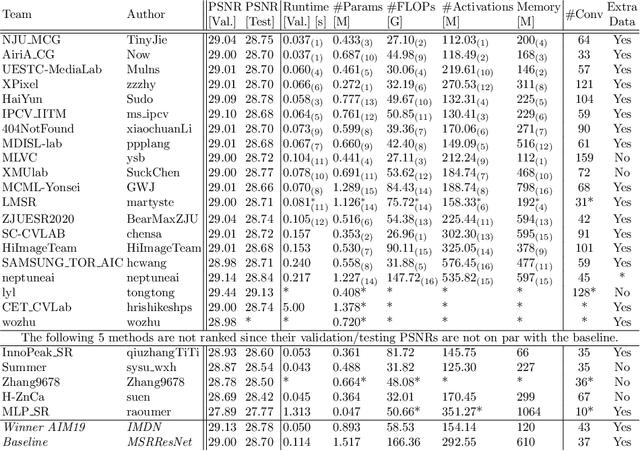
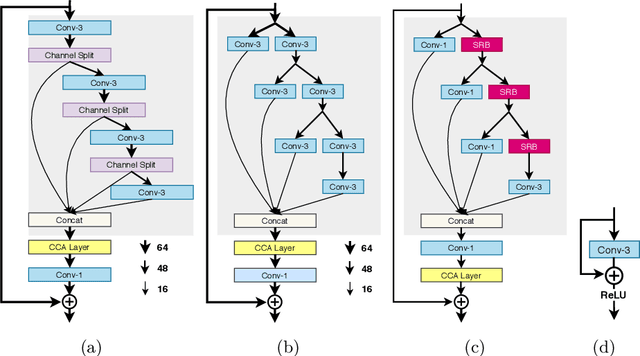
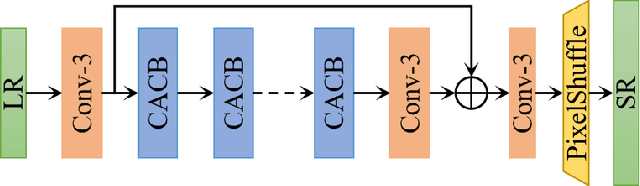
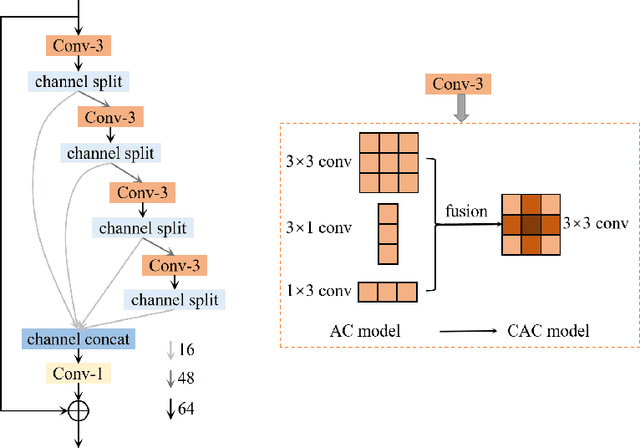
This paper reviews the AIM 2020 challenge on efficient single image super-resolution with focus on the proposed solutions and results. The challenge task was to super-resolve an input image with a magnification factor x4 based on a set of prior examples of low and corresponding high resolution images. The goal is to devise a network that reduces one or several aspects such as runtime, parameter count, FLOPs, activations, and memory consumption while at least maintaining PSNR of MSRResNet. The track had 150 registered participants, and 25 teams submitted the final results. They gauge the state-of-the-art in efficient single image super-resolution.
Geometric Disentanglement for Generative Latent Shape Models
Aug 18, 2019
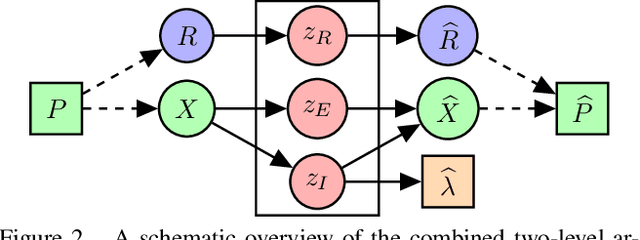


Representing 3D shape is a fundamental problem in artificial intelligence, which has numerous applications within computer vision and graphics. One avenue that has recently begun to be explored is the use of latent representations of generative models. However, it remains an open problem to learn a generative model of shape that is interpretable and easily manipulated, particularly in the absence of supervised labels. In this paper, we propose an unsupervised approach to partitioning the latent space of a variational autoencoder for 3D point clouds in a natural way, using only geometric information. Our method makes use of tools from spectral differential geometry to separate intrinsic and extrinsic shape information, and then considers several hierarchical disentanglement penalties for dividing the latent space in this manner, including a novel one that penalizes the Jacobian of the latent representation of the decoded output with respect to the latent encoding. We show that the resulting representation exhibits intuitive and interpretable behavior, enabling tasks such as pose transfer and pose-aware shape retrieval that cannot easily be performed by models with an entangled representation.