 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTrusted Approximate Policy Iteration with Bisimulation Metrics
Paper and Code
Feb 06, 2022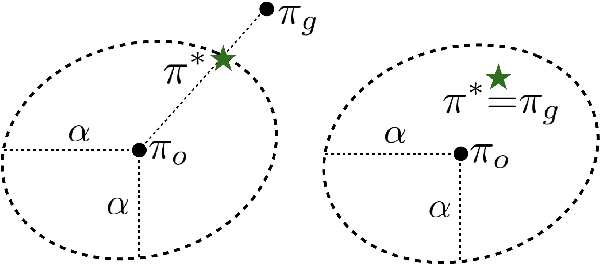
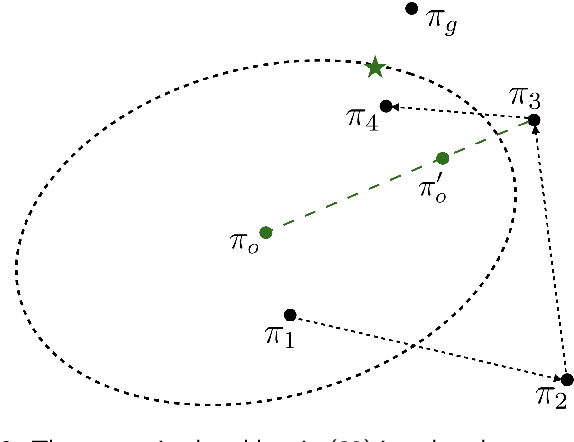
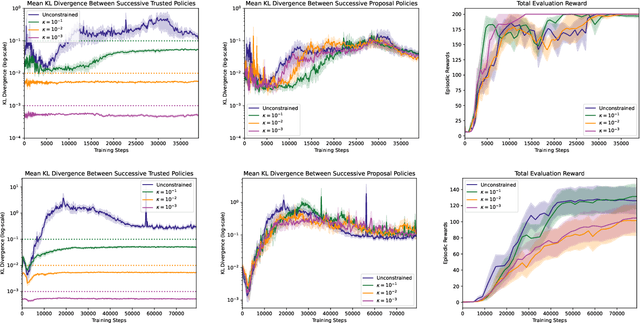
Bisimulation metrics define a distance measure between states of a Markov decision process (MDP) based on a comparison of reward sequences. Due to this property they provide theoretical guarantees in value function approximation. In this work we first prove that bisimulation metrics can be defined via any $p$-Wasserstein metric for $p\geq 1$. Then we describe an approximate policy iteration (API) procedure that uses $\epsilon$-aggregation with $\pi$-bisimulation and prove performance bounds for continuous state spaces. We bound the difference between $\pi$-bisimulation metrics in terms of the change in the policies themselves. Based on these theoretical results, we design an API($\alpha$) procedure that employs conservative policy updates and enjoys better performance bounds than the naive API approach. In addition, we propose a novel trust region approach which circumvents the requirement to explicitly solve a constrained optimization problem. Finally, we provide experimental evidence of improved stability compared to non-conservative alternatives in simulated continuous control.