 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRAW-Domain Degradation Models for Realistic Smartphone Super-Resolution
Mar 12, 2026Digital zoom on smartphones relies on learning-based super-resolution (SR) models that operate on RAW sensor images, but obtaining sensor-specific training data is challenging due to the lack of ground-truth images. Synthetic data generation via ``unprocessing'' pipelines offers a potential solution by simulating the degradations that transform high-resolution (HR) images into their low-resolution (LR) counterparts. However, these pipelines can introduce domain gaps due to incomplete or unrealistic degradation modeling. In this paper, we demonstrate that principled and carefully designed degradation modeling can enhance SR performance in real-world conditions. Instead of relying on generic priors for camera blur and noise, we model device-specific degradations through calibration and unprocess publicly available rendered images into the RAW domain of different smartphones. Using these image pairs, we train a single-image RAW-to-RGB SR model and evaluate it on real data from a held-out device. Our experiments show that accurate degradation modeling leads to noticeable improvements, with our SR model outperforming baselines trained on large pools of arbitrarily chosen degradations.
Probabilistic Directed Distance Fields for Ray-Based Shape Representations
Apr 13, 2024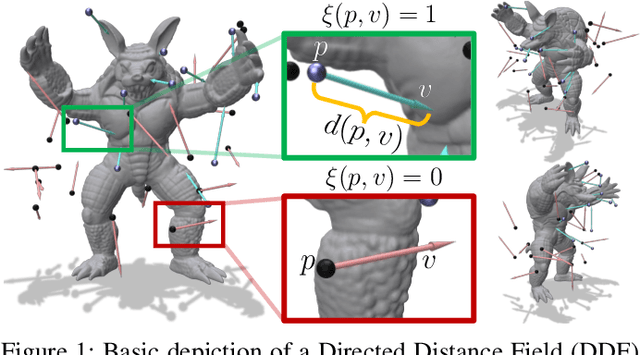

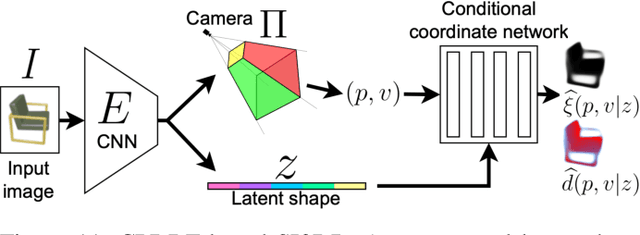

In modern computer vision, the optimal representation of 3D shape continues to be task-dependent. One fundamental operation applied to such representations is differentiable rendering, as it enables inverse graphics approaches in learning frameworks. Standard explicit shape representations (voxels, point clouds, or meshes) are often easily rendered, but can suffer from limited geometric fidelity, among other issues. On the other hand, implicit representations (occupancy, distance, or radiance fields) preserve greater fidelity, but suffer from complex or inefficient rendering processes, limiting scalability. In this work, we devise Directed Distance Fields (DDFs), a novel neural shape representation that builds upon classical distance fields. The fundamental operation in a DDF maps an oriented point (position and direction) to surface visibility and depth. This enables efficient differentiable rendering, obtaining depth with a single forward pass per pixel, as well as differential geometric quantity extraction (e.g., surface normals), with only additional backward passes. Using probabilistic DDFs (PDDFs), we show how to model inherent discontinuities in the underlying field. We then apply DDFs to several applications, including single-shape fitting, generative modelling, and single-image 3D reconstruction, showcasing strong performance with simple architectural components via the versatility of our representation. Finally, since the dimensionality of DDFs permits view-dependent geometric artifacts, we conduct a theoretical investigation of the constraints necessary for view consistency. We find a small set of field properties that are sufficient to guarantee a DDF is consistent, without knowing, for instance, which shape the field is expressing.
Fast-Grasp'D: Dexterous Multi-finger Grasp Generation Through Differentiable Simulation
Jun 13, 2023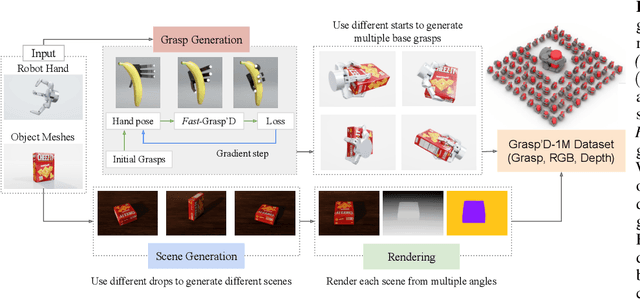
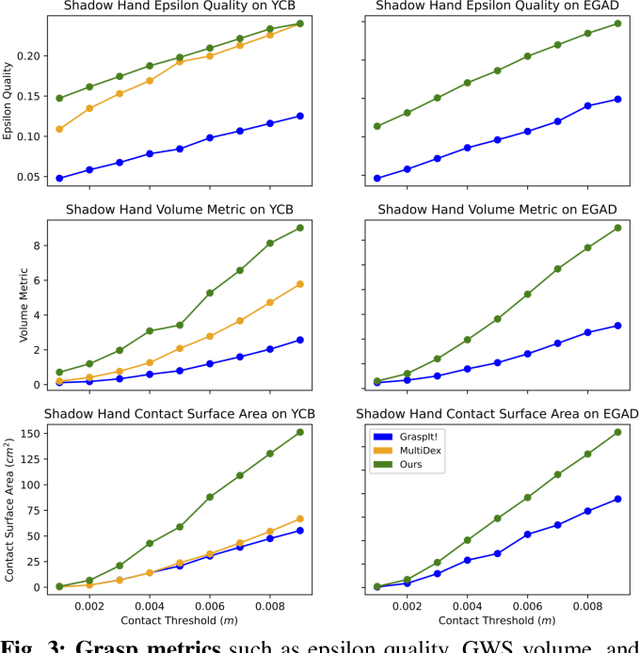
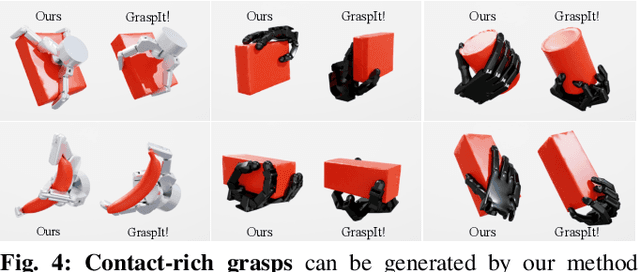

Multi-finger grasping relies on high quality training data, which is hard to obtain: human data is hard to transfer and synthetic data relies on simplifying assumptions that reduce grasp quality. By making grasp simulation differentiable, and contact dynamics amenable to gradient-based optimization, we accelerate the search for high-quality grasps with fewer limiting assumptions. We present Grasp'D-1M: a large-scale dataset for multi-finger robotic grasping, synthesized with Fast- Grasp'D, a novel differentiable grasping simulator. Grasp'D- 1M contains one million training examples for three robotic hands (three, four and five-fingered), each with multimodal visual inputs (RGB+depth+segmentation, available in mono and stereo). Grasp synthesis with Fast-Grasp'D is 10x faster than GraspIt! and 20x faster than the prior Grasp'D differentiable simulator. Generated grasps are more stable and contact-rich than GraspIt! grasps, regardless of the distance threshold used for contact generation. We validate the usefulness of our dataset by retraining an existing vision-based grasping pipeline on Grasp'D-1M, and showing a dramatic increase in model performance, predicting grasps with 30% more contact, a 33% higher epsilon metric, and 35% lower simulated displacement. Additional details at https://dexgrasp.github.io.
Efficient Flow-Guided Multi-frame De-fencing
Jan 25, 2023


Taking photographs ''in-the-wild'' is often hindered by fence obstructions that stand between the camera user and the scene of interest, and which are hard or impossible to avoid. De-fencing is the algorithmic process of automatically removing such obstructions from images, revealing the invisible parts of the scene. While this problem can be formulated as a combination of fence segmentation and image inpainting, this often leads to implausible hallucinations of the occluded regions. Existing multi-frame approaches rely on propagating information to a selected keyframe from its temporal neighbors, but they are often inefficient and struggle with alignment of severely obstructed images. In this work we draw inspiration from the video completion literature and develop a simplified framework for multi-frame de-fencing that computes high quality flow maps directly from obstructed frames and uses them to accurately align frames. Our primary focus is efficiency and practicality in a real-world setting: the input to our algorithm is a short image burst (5 frames) - a data modality commonly available in modern smartphones - and the output is a single reconstructed keyframe, with the fence removed. Our approach leverages simple yet effective CNN modules, trained on carefully generated synthetic data, and outperforms more complicated alternatives real bursts, both quantitatively and qualitatively, while running real-time.
* 16 pages, 12 figures. Published at the Winter Conference on Application of Computer Vision (WACV) 2023
Grasp'D: Differentiable Contact-rich Grasp Synthesis for Multi-fingered Hands
Aug 26, 2022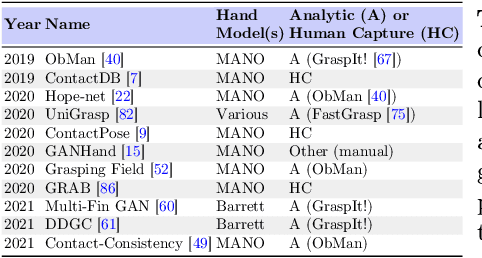


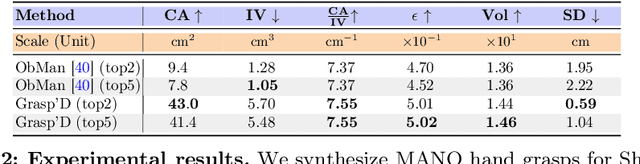
The study of hand-object interaction requires generating viable grasp poses for high-dimensional multi-finger models, often relying on analytic grasp synthesis which tends to produce brittle and unnatural results. This paper presents Grasp'D, an approach for grasp synthesis with a differentiable contact simulation from both known models as well as visual inputs. We use gradient-based methods as an alternative to sampling-based grasp synthesis, which fails without simplifying assumptions, such as pre-specified contact locations and eigengrasps. Such assumptions limit grasp discovery and, in particular, exclude high-contact power grasps. In contrast, our simulation-based approach allows for stable, efficient, physically realistic, high-contact grasp synthesis, even for gripper morphologies with high-degrees of freedom. We identify and address challenges in making grasp simulation amenable to gradient-based optimization, such as non-smooth object surface geometry, contact sparsity, and a rugged optimization landscape. Grasp'D compares favorably to analytic grasp synthesis on human and robotic hand models, and resultant grasps achieve over 4x denser contact, leading to significantly higher grasp stability. Video and code available at https://graspd-eccv22.github.io/.
Representing 3D Shapes with Probabilistic Directed Distance Fields
Dec 10, 2021
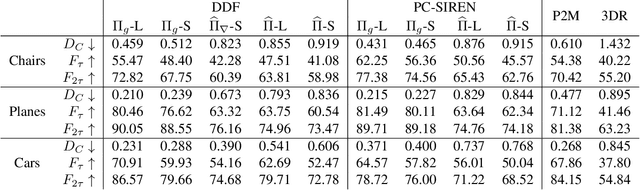
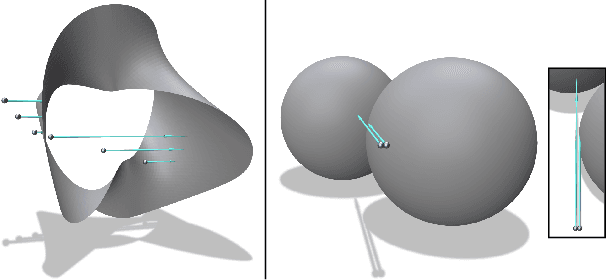
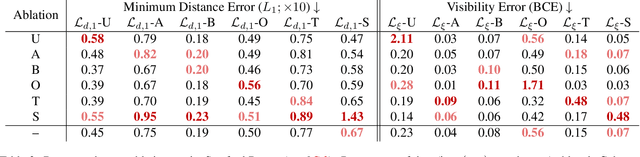
Differentiable rendering is an essential operation in modern vision, allowing inverse graphics approaches to 3D understanding to be utilized in modern machine learning frameworks. Explicit shape representations (voxels, point clouds, or meshes), while relatively easily rendered, often suffer from limited geometric fidelity or topological constraints. On the other hand, implicit representations (occupancy, distance, or radiance fields) preserve greater fidelity, but suffer from complex or inefficient rendering processes, limiting scalability. In this work, we endeavour to address both shortcomings with a novel shape representation that allows fast differentiable rendering within an implicit architecture. Building on implicit distance representations, we define Directed Distance Fields (DDFs), which map an oriented point (position and direction) to surface visibility and depth. Such a field can render a depth map with a single forward pass per pixel, enable differential surface geometry extraction (e.g., surface normals and curvatures) via network derivatives, be easily composed, and permit extraction of classical unsigned distance fields. Using probabilistic DDFs (PDDFs), we show how to model inherent discontinuities in the underlying field. Finally, we apply our method to fitting single shapes, unpaired 3D-aware generative image modelling, and single-image 3D reconstruction tasks, showcasing strong performance with simple architectural components via the versatility of our representation.
GIFT: Generalizable Interaction-aware Functional Tool Affordances without Labels
Jun 28, 2021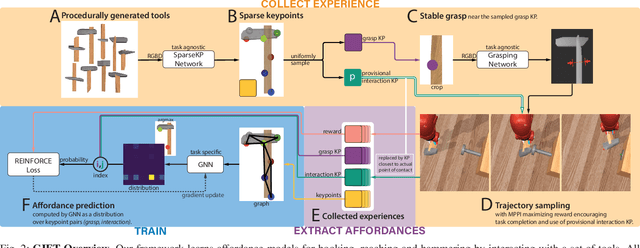
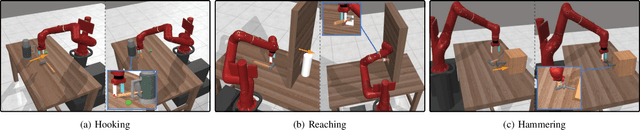

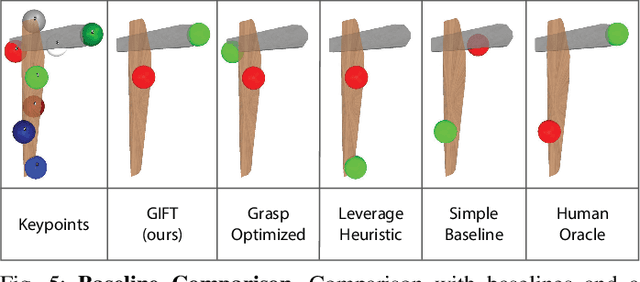
Tool use requires reasoning about the fit between an object's affordances and the demands of a task. Visual affordance learning can benefit from goal-directed interaction experience, but current techniques rely on human labels or expert demonstrations to generate this data. In this paper, we describe a method that grounds affordances in physical interactions instead, thus removing the need for human labels or expert policies. We use an efficient sampling-based method to generate successful trajectories that provide contact data, which are then used to reveal affordance representations. Our framework, GIFT, operates in two phases: first, we discover visual affordances from goal-directed interaction with a set of procedurally generated tools; second, we train a model to predict new instances of the discovered affordances on novel tools in a self-supervised fashion. In our experiments, we show that GIFT can leverage a sparse keypoint representation to predict grasp and interaction points to accommodate multiple tasks, such as hooking, reaching, and hammering. GIFT outperforms baselines on all tasks and matches a human oracle on two of three tasks using novel tools.
Learning Compositional Shape Priors for Few-Shot 3D Reconstruction
Jun 16, 2021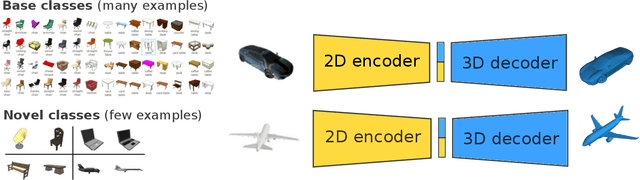
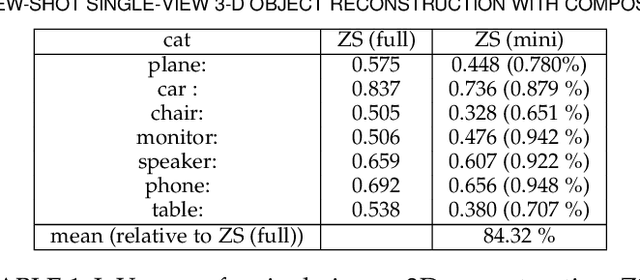
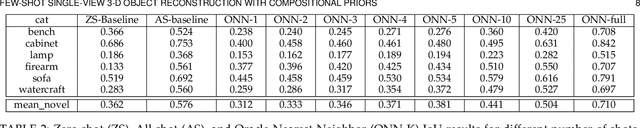
The impressive performance of deep convolutional neural networks in single-view 3D reconstruction suggests that these models perform non-trivial reasoning about the 3D structure of the output space. Recent work has challenged this belief, showing that, on standard benchmarks, complex encoder-decoder architectures perform similarly to nearest-neighbor baselines or simple linear decoder models that exploit large amounts of per-category data. However, building large collections of 3D shapes for supervised training is a laborious process; a more realistic and less constraining task is inferring 3D shapes for categories with few available training examples, calling for a model that can successfully generalize to novel object classes. In this work we experimentally demonstrate that naive baselines fail in this few-shot learning setting, in which the network must learn informative shape priors for inference of new categories. We propose three ways to learn a class-specific global shape prior, directly from data. Using these techniques, we are able to capture multi-scale information about the 3D shape, and account for intra-class variability by virtue of an implicit compositional structure. Experiments on the popular ShapeNet dataset show that our method outperforms a zero-shot baseline by over 40%, and the current state-of-the-art by over 10%, in terms of relative performance, in the few-shot setting.
Disentangling Geometric Deformation Spaces in Generative Latent Shape Models
Feb 27, 2021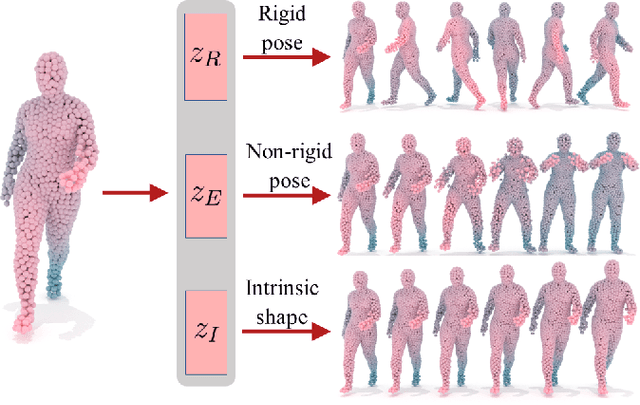

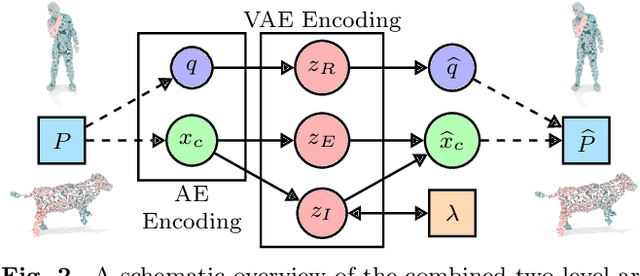

A complete representation of 3D objects requires characterizing the space of deformations in an interpretable manner, from articulations of a single instance to changes in shape across categories. In this work, we improve on a prior generative model of geometric disentanglement for 3D shapes, wherein the space of object geometry is factorized into rigid orientation, non-rigid pose, and intrinsic shape. The resulting model can be trained from raw 3D shapes, without correspondences, labels, or even rigid alignment, using a combination of classical spectral geometry and probabilistic disentanglement of a structured latent representation space. Our improvements include more sophisticated handling of rotational invariance and the use of a diffeomorphic flow network to bridge latent and spectral space. The geometric structuring of the latent space imparts an interpretable characterization of the deformation space of an object. Furthermore, it enables tasks like pose transfer and pose-aware retrieval without requiring supervision. We evaluate our model on its generative modelling, representation learning, and disentanglement performance, showing improved rotation invariance and intrinsic-extrinsic factorization quality over the prior model.
Cycle-Consistent Generative Rendering for 2D-3D Modality Translation
Nov 16, 2020
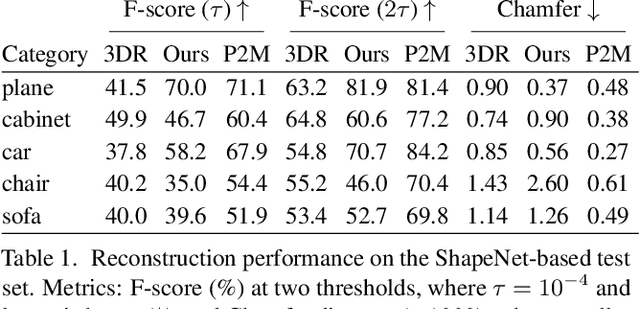
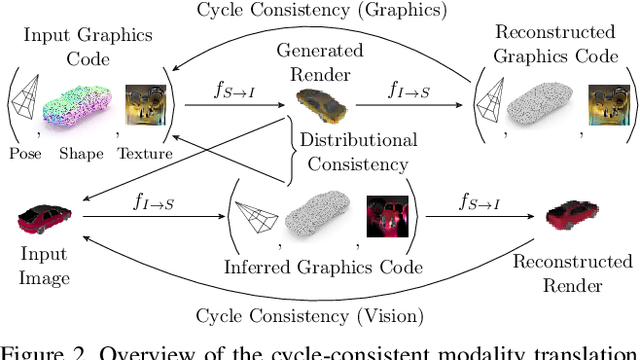
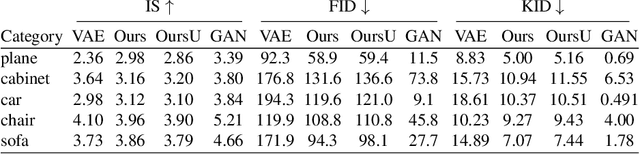
For humans, visual understanding is inherently generative: given a 3D shape, we can postulate how it would look in the world; given a 2D image, we can infer the 3D structure that likely gave rise to it. We can thus translate between the 2D visual and 3D structural modalities of a given object. In the context of computer vision, this corresponds to a learnable module that serves two purposes: (i) generate a realistic rendering of a 3D object (shape-to-image translation) and (ii) infer a realistic 3D shape from an image (image-to-shape translation). In this paper, we learn such a module while being conscious of the difficulties in obtaining large paired 2D-3D datasets. By leveraging generative domain translation methods, we are able to define a learning algorithm that requires only weak supervision, with unpaired data. The resulting model is not only able to perform 3D shape, pose, and texture inference from 2D images, but can also generate novel textured 3D shapes and renders, similar to a graphics pipeline. More specifically, our method (i) infers an explicit 3D mesh representation, (ii) utilizes example shapes to regularize inference, (iii) requires only an image mask (no keypoints or camera extrinsics), and (iv) has generative capabilities. While prior work explores subsets of these properties, their combination is novel. We demonstrate the utility of our learned representation, as well as its performance on image generation and unpaired 3D shape inference tasks.