 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSun Off, Lights On: Photorealistic Monocular Nighttime Simulation for Robust Semantic Perception
Jul 29, 2024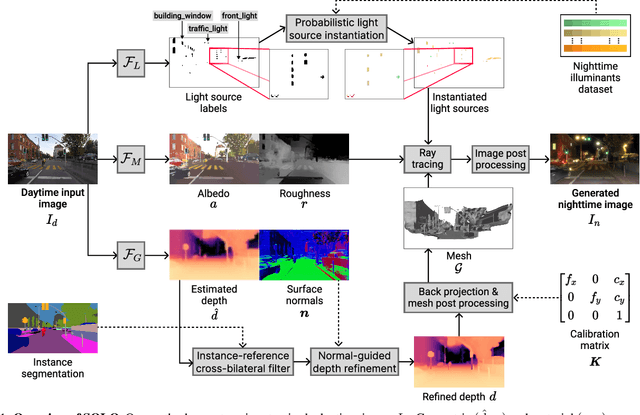



Nighttime scenes are hard to semantically perceive with learned models and annotate for humans. Thus, realistic synthetic nighttime data become all the more important for learning robust semantic perception at night, thanks to their accurate and cheap semantic annotations. However, existing data-driven or hand-crafted techniques for generating nighttime images from daytime counterparts suffer from poor realism. The reason is the complex interaction of highly spatially varying nighttime illumination, which differs drastically from its daytime counterpart, with objects of spatially varying materials in the scene, happening in 3D and being very hard to capture with such 2D approaches. The above 3D interaction and illumination shift have proven equally hard to model in the literature, as opposed to other conditions such as fog or rain. Our method, named Sun Off, Lights On (SOLO), is the first to perform nighttime simulation on single images in a photorealistic fashion by operating in 3D. It first explicitly estimates the 3D geometry, the materials and the locations of light sources of the scene from the input daytime image and relights the scene by probabilistically instantiating light sources in a way that accounts for their semantics and then running standard ray tracing. Not only is the visual quality and photorealism of our nighttime images superior to competing approaches including diffusion models, but the former images are also proven more beneficial for semantic nighttime segmentation in day-to-night adaptation. Code and data will be made publicly available.
HandyPriors: Physically Consistent Perception of Hand-Object Interactions with Differentiable Priors
Dec 03, 2023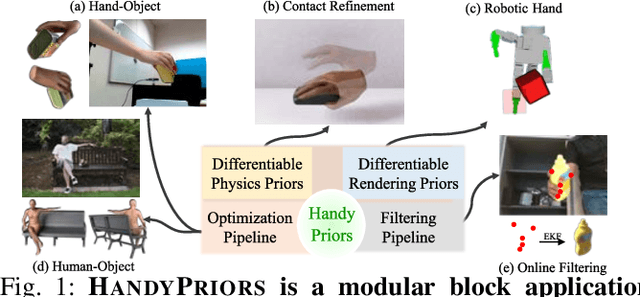
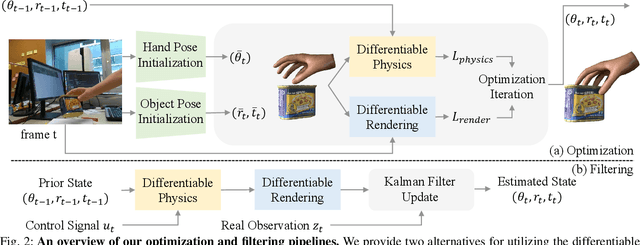
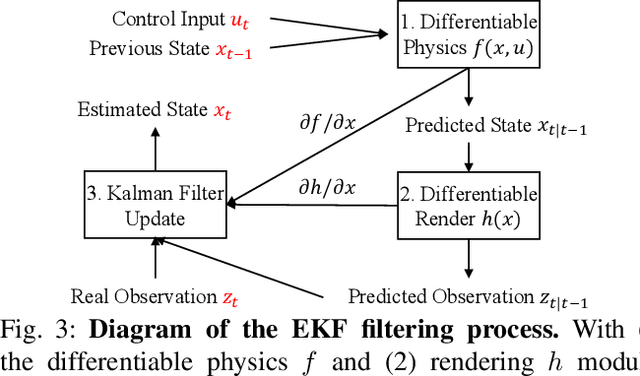

Various heuristic objectives for modeling hand-object interaction have been proposed in past work. However, due to the lack of a cohesive framework, these objectives often possess a narrow scope of applicability and are limited by their efficiency or accuracy. In this paper, we propose HandyPriors, a unified and general pipeline for pose estimation in human-object interaction scenes by leveraging recent advances in differentiable physics and rendering. Our approach employs rendering priors to align with input images and segmentation masks along with physics priors to mitigate penetration and relative-sliding across frames. Furthermore, we present two alternatives for hand and object pose estimation. The optimization-based pose estimation achieves higher accuracy, while the filtering-based tracking, which utilizes the differentiable priors as dynamics and observation models, executes faster. We demonstrate that HandyPriors attains comparable or superior results in the pose estimation task, and that the differentiable physics module can predict contact information for pose refinement. We also show that our approach generalizes to perception tasks, including robotic hand manipulation and human-object pose estimation in the wild.
Fast-Grasp'D: Dexterous Multi-finger Grasp Generation Through Differentiable Simulation
Jun 13, 2023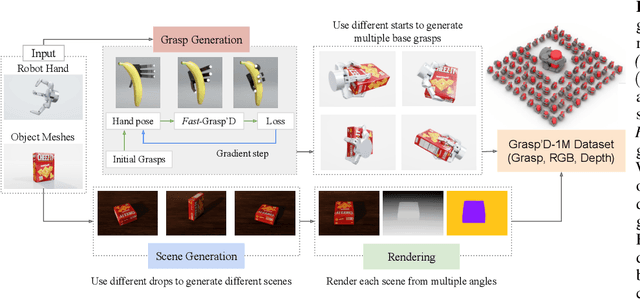
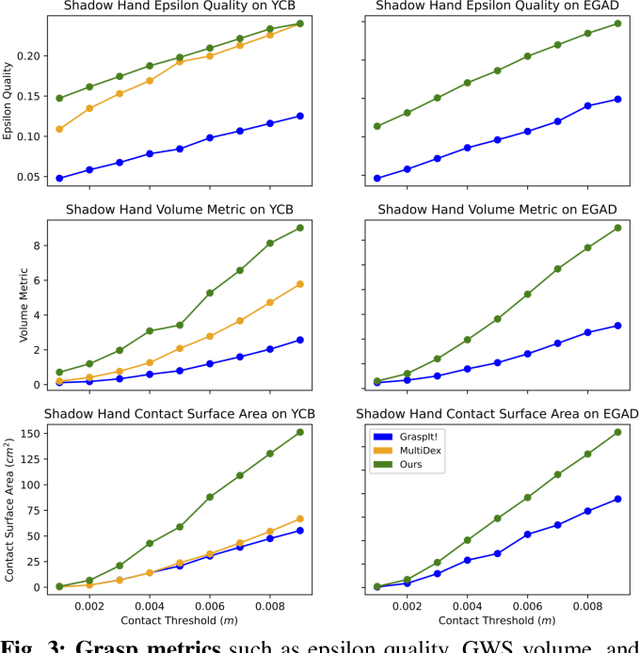
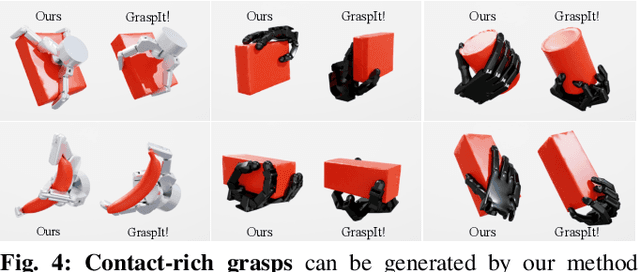

Multi-finger grasping relies on high quality training data, which is hard to obtain: human data is hard to transfer and synthetic data relies on simplifying assumptions that reduce grasp quality. By making grasp simulation differentiable, and contact dynamics amenable to gradient-based optimization, we accelerate the search for high-quality grasps with fewer limiting assumptions. We present Grasp'D-1M: a large-scale dataset for multi-finger robotic grasping, synthesized with Fast- Grasp'D, a novel differentiable grasping simulator. Grasp'D- 1M contains one million training examples for three robotic hands (three, four and five-fingered), each with multimodal visual inputs (RGB+depth+segmentation, available in mono and stereo). Grasp synthesis with Fast-Grasp'D is 10x faster than GraspIt! and 20x faster than the prior Grasp'D differentiable simulator. Generated grasps are more stable and contact-rich than GraspIt! grasps, regardless of the distance threshold used for contact generation. We validate the usefulness of our dataset by retraining an existing vision-based grasping pipeline on Grasp'D-1M, and showing a dramatic increase in model performance, predicting grasps with 30% more contact, a 33% higher epsilon metric, and 35% lower simulated displacement. Additional details at https://dexgrasp.github.io.