 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRIFT: Repurposing Negative Samples via Reward-Informed Fine-Tuning
Jan 14, 2026While Supervised Fine-Tuning (SFT) and Rejection Sampling Fine-Tuning (RFT) are standard for LLM alignment, they either rely on costly expert data or discard valuable negative samples, leading to data inefficiency. To address this, we propose Reward Informed Fine-Tuning (RIFT), a simple yet effective framework that utilizes all self-generated samples. Unlike the hard thresholding of RFT, RIFT repurposes negative trajectories, reweighting the loss with scalar rewards to learn from both the positive and negative trajectories from the model outputs. To overcome the training collapse caused by naive reward integration, where direct multiplication yields an unbounded loss, we introduce a stabilized loss formulation that ensures numerical robustness and optimization efficiency. Extensive experiments on mathematical benchmarks across various base models show that RIFT consistently outperforms RFT. Our results demonstrate that RIFT is a robust and data-efficient alternative for alignment using mixed-quality, self-generated data.
Local-Canonicalization Equivariant Graph Neural Networks for Sample-Efficient and Generalizable Swarm Robot Control
Sep 17, 2025Multi-agent reinforcement learning (MARL) has emerged as a powerful paradigm for coordinating swarms of agents in complex decision-making, yet major challenges remain. In competitive settings such as pursuer-evader tasks, simultaneous adaptation can destabilize training; non-kinetic countermeasures often fail under adverse conditions; and policies trained in one configuration rarely generalize to environments with a different number of agents. To address these issues, we propose the Local-Canonicalization Equivariant Graph Neural Networks (LEGO) framework, which integrates seamlessly with popular MARL algorithms such as MAPPO. LEGO employs graph neural networks to capture permutation equivariance and generalization to different agent numbers, canonicalization to enforce E(n)-equivariance, and heterogeneous representations to encode role-specific inductive biases. Experiments on cooperative and competitive swarm benchmarks show that LEGO outperforms strong baselines and improves generalization. In real-world experiments, LEGO demonstrates robustness to varying team sizes and agent failure.
Constraint Matters: Multi-Modal Representation for Reducing Mixed-Integer Linear programming
Aug 26, 2025Model reduction, which aims to learn a simpler model of the original mixed integer linear programming (MILP), can solve large-scale MILP problems much faster. Most existing model reduction methods are based on variable reduction, which predicts a solution value for a subset of variables. From a dual perspective, constraint reduction that transforms a subset of inequality constraints into equalities can also reduce the complexity of MILP, but has been largely ignored. Therefore, this paper proposes a novel constraint-based model reduction approach for the MILP. Constraint-based MILP reduction has two challenges: 1) which inequality constraints are critical such that reducing them can accelerate MILP solving while preserving feasibility, and 2) how to predict these critical constraints efficiently. To identify critical constraints, we first label these tight-constraints at the optimal solution as potential critical constraints and design a heuristic rule to select a subset of critical tight-constraints. To learn the critical tight-constraints, we propose a multi-modal representation technique that leverages information from both instance-level and abstract-level MILP formulations. The experimental results show that, compared to the state-of-the-art methods, our method improves the quality of the solution by over 50\% and reduces the computation time by 17.47\%.
Beyond Standard MoE: Mixture of Latent Experts for Resource-Efficient Language Models
Mar 29, 2025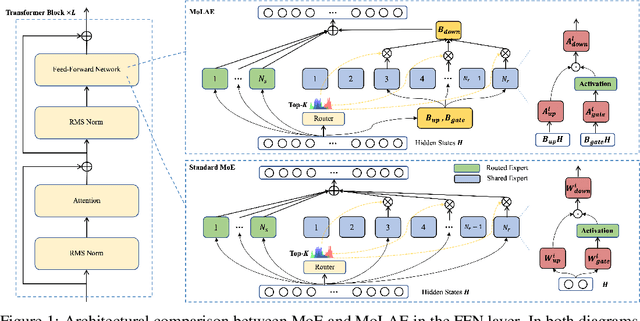


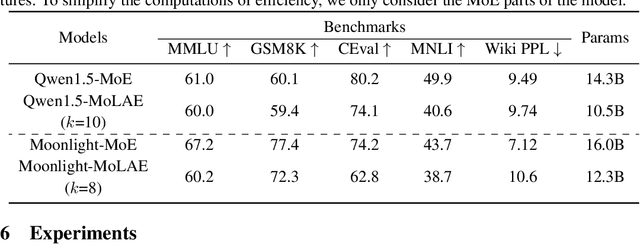
Mixture of Experts (MoE) has emerged as a pivotal architectural paradigm for efficient scaling of Large Language Models (LLMs), operating through selective activation of parameter subsets for each input token. Nevertheless, conventional MoE architectures encounter substantial challenges, including excessive memory utilization and communication overhead during training and inference, primarily attributable to the proliferation of expert modules. In this paper, we introduce Mixture of Latent Experts (MoLE), a novel parameterization methodology that facilitates the mapping of specific experts into a shared latent space. Specifically, all expert operations are systematically decomposed into two principal components: a shared projection into a lower-dimensional latent space, followed by expert-specific transformations with significantly reduced parametric complexity. This factorized approach substantially diminishes parameter count and computational requirements. Beyond the pretraining implementation of the MoLE architecture, we also establish a rigorous mathematical framework for transforming pre-trained MoE models into the MoLE architecture, characterizing the sufficient conditions for optimal factorization and developing a systematic two-phase algorithm for this conversion process. Our comprehensive theoretical analysis demonstrates that MoLE significantly enhances computational efficiency across multiple dimensions while preserving model representational capacity. Empirical evaluations corroborate our theoretical findings, confirming that MoLE achieves performance comparable to standard MoE implementations while substantially reducing resource requirements.
Unlocking Efficient Long-to-Short LLM Reasoning with Model Merging
Mar 26, 2025



The transition from System 1 to System 2 reasoning in large language models (LLMs) has marked significant advancements in handling complex tasks through deliberate, iterative thinking. However, this progress often comes at the cost of efficiency, as models tend to overthink, generating redundant reasoning steps without proportional improvements in output quality. Long-to-Short (L2S) reasoning has emerged as a promising solution to this challenge, aiming to balance reasoning depth with practical efficiency. While existing approaches, such as supervised fine-tuning (SFT), reinforcement learning (RL), and prompt engineering, have shown potential, they are either computationally expensive or unstable. Model merging, on the other hand, offers a cost-effective and robust alternative by integrating the quick-thinking capabilities of System 1 models with the methodical reasoning of System 2 models. In this work, we present a comprehensive empirical study on model merging for L2S reasoning, exploring diverse methodologies, including task-vector-based, SVD-based, and activation-informed merging. Our experiments reveal that model merging can reduce average response length by up to 55% while preserving or even improving baseline performance. We also identify a strong correlation between model scale and merging efficacy with extensive evaluations on 1.5B/7B/14B/32B models. Furthermore, we investigate the merged model's ability to self-critique and self-correct, as well as its adaptive response length based on task complexity. Our findings highlight model merging as a highly efficient and effective paradigm for L2S reasoning, offering a practical solution to the overthinking problem while maintaining the robustness of System 2 reasoning. This work can be found on Github https://github.com/hahahawu/Long-to-Short-via-Model-Merging.
Automatic Operator-level Parallelism Planning for Distributed Deep Learning -- A Mixed-Integer Programming Approach
Mar 12, 2025
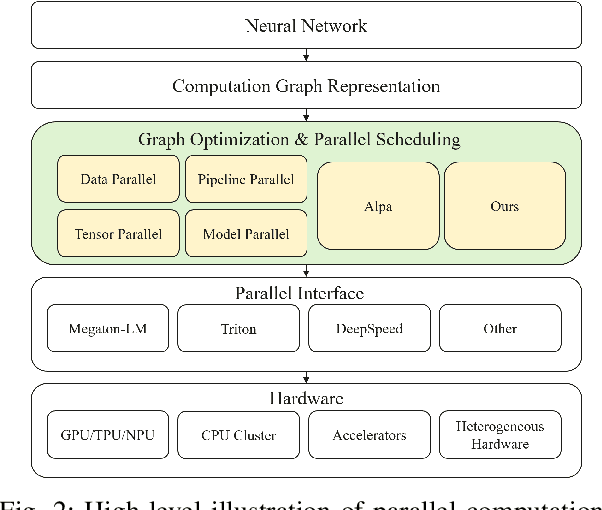
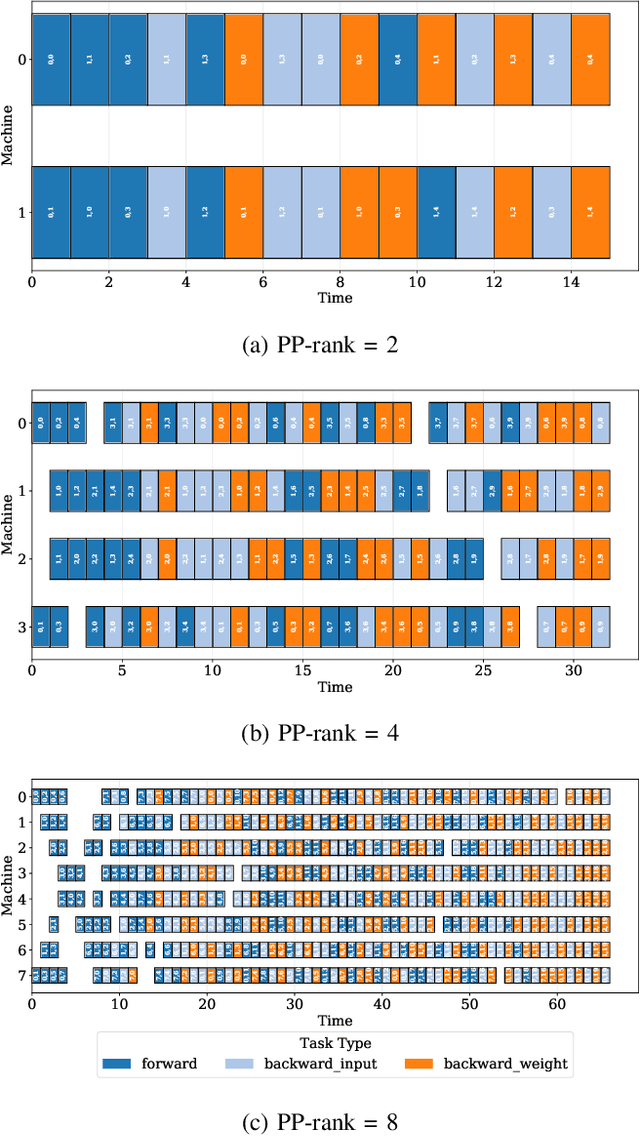
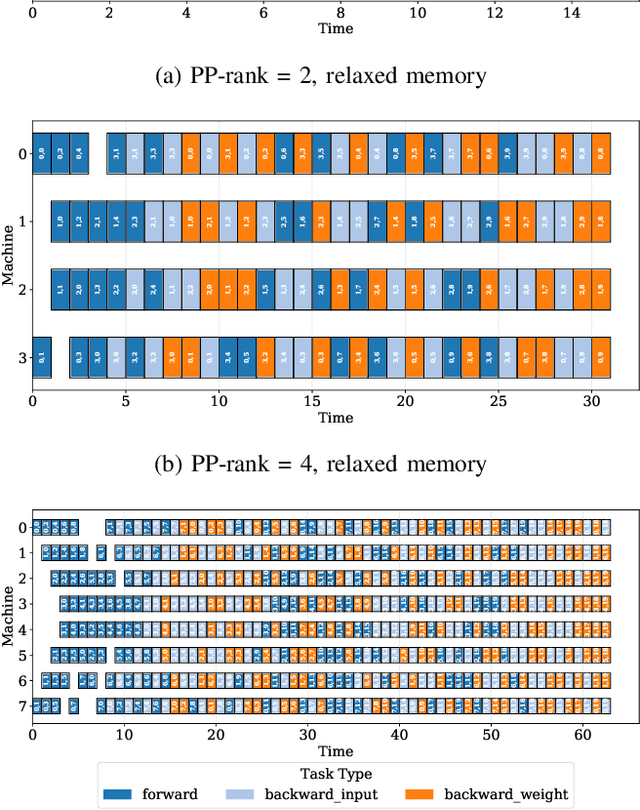
As the artificial intelligence community advances into the era of large models with billions of parameters, distributed training and inference have become essential. While various parallelism strategies-data, model, sequence, and pipeline-have been successfully implemented for popular neural networks on main-stream hardware, optimizing the distributed deployment schedule requires extensive expertise and manual effort. Further more, while existing frameworks with most simple chain-like structures, they struggle with complex non-linear architectures. Mixture-of-experts and multi-modal models feature intricate MIMO and branch-rich topologies that require fine-grained operator-level parallelization beyond the capabilities of existing frameworks. We propose formulating parallelism planning as a scheduling optimization problem using mixed-integer programming. We propose a bi-level solution framework balancing optimality with computational efficiency, automatically generating effective distributed plans that capture both the heterogeneous structure of modern neural networks and the underlying hardware constraints. In experiments comparing against expert-designed strategies like DeepSeek's DualPipe, our framework achieves comparable or superior performance, reducing computational bubbles by half under the same memory constraints. The framework's versatility extends beyond throughput optimization to incorporate hardware utilization maximization, memory capacity constraints, and other considerations or potential strategies. Such capabilities position our solution as both a valuable research tool for exploring optimal parallelization strategies and a practical industrial solution for large-scale AI deployment.
CMMCoT: Enhancing Complex Multi-Image Comprehension via Multi-Modal Chain-of-Thought and Memory Augmentation
Mar 07, 2025



While previous multimodal slow-thinking methods have demonstrated remarkable success in single-image understanding scenarios, their effectiveness becomes fundamentally constrained when extended to more complex multi-image comprehension tasks. This limitation stems from their predominant reliance on text-based intermediate reasoning processes. While for human, when engaging in sophisticated multi-image analysis, they typically perform two complementary cognitive operations: (1) continuous cross-image visual comparison through region-of-interest matching, and (2) dynamic memorization of critical visual concepts throughout the reasoning chain. Motivated by these observations, we propose the Complex Multi-Modal Chain-of-Thought (CMMCoT) framework, a multi-step reasoning framework that mimics human-like "slow thinking" for multi-image understanding. Our approach incorporates two key innovations: 1. The construction of interleaved multimodal multi-step reasoning chains, which utilize critical visual region tokens, extracted from intermediate reasoning steps, as supervisory signals. This mechanism not only facilitates comprehensive cross-modal understanding but also enhances model interpretability. 2. The introduction of a test-time memory augmentation module that expands the model reasoning capacity during inference while preserving parameter efficiency. Furthermore, to facilitate research in this direction, we have curated a novel multi-image slow-thinking dataset. Extensive experiments demonstrate the effectiveness of our model.
GAGrasp: Geometric Algebra Diffusion for Dexterous Grasping
Mar 06, 2025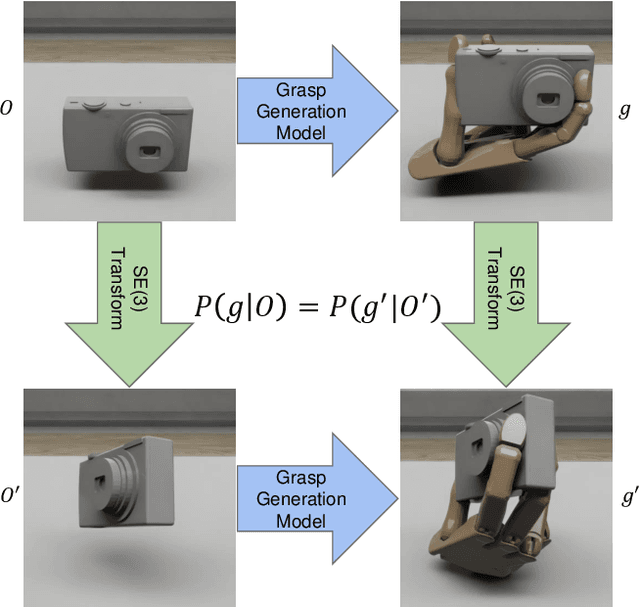
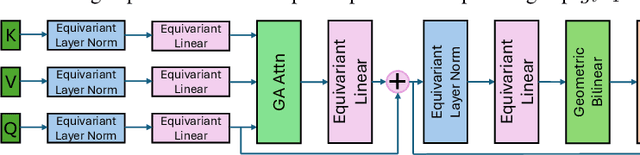

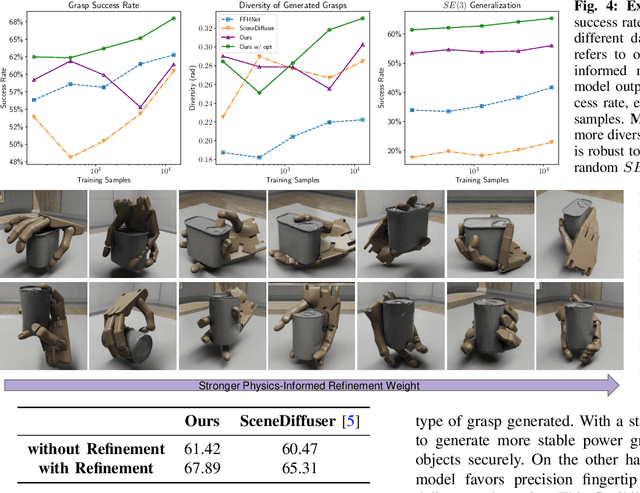
We propose GAGrasp, a novel framework for dexterous grasp generation that leverages geometric algebra representations to enforce equivariance to SE(3) transformations. By encoding the SE(3) symmetry constraint directly into the architecture, our method improves data and parameter efficiency while enabling robust grasp generation across diverse object poses. Additionally, we incorporate a differentiable physics-informed refinement layer, which ensures that generated grasps are physically plausible and stable. Extensive experiments demonstrate the model's superior performance in generalization, stability, and adaptability compared to existing methods. Additional details at https://gagrasp.github.io/
Fast and Interpretable Mixed-Integer Linear Program Solving by Learning Model Reduction
Dec 31, 2024



By exploiting the correlation between the structure and the solution of Mixed-Integer Linear Programming (MILP), Machine Learning (ML) has become a promising method for solving large-scale MILP problems. Existing ML-based MILP solvers mainly focus on end-to-end solution learning, which suffers from the scalability issue due to the high dimensionality of the solution space. Instead of directly learning the optimal solution, this paper aims to learn a reduced and equivalent model of the original MILP as an intermediate step. The reduced model often corresponds to interpretable operations and is much simpler, enabling us to solve large-scale MILP problems much faster than existing commercial solvers. However, current approaches rely only on the optimal reduced model, overlooking the significant preference information of all reduced models. To address this issue, this paper proposes a preference-based model reduction learning method, which considers the relative performance (i.e., objective cost and constraint feasibility) of all reduced models on each MILP instance as preferences. We also introduce an attention mechanism to capture and represent preference information, which helps improve the performance of model reduction learning tasks. Moreover, we propose a SetCover based pruning method to control the number of reduced models (i.e., labels), thereby simplifying the learning process. Evaluation on real-world MILP problems shows that 1) compared to the state-of-the-art model reduction ML methods, our method obtains nearly 20% improvement on solution accuracy, and 2) compared to the commercial solver Gurobi, two to four orders of magnitude speedups are achieved.
Boosting Private Domain Understanding of Efficient MLLMs: A Tuning-free, Adaptive, Universal Prompt Optimization Framework
Dec 27, 2024Efficient multimodal large language models (EMLLMs), in contrast to multimodal large language models (MLLMs), reduce model size and computational costs and are often deployed on resource-constrained devices. However, due to data privacy concerns, existing open-source EMLLMs rarely have access to private domain-specific data during the pre-training process, making them difficult to directly apply in device-specific domains, such as certain business scenarios. To address this weakness, this paper focuses on the efficient adaptation of EMLLMs to private domains, specifically in two areas: 1) how to reduce data requirements, and 2) how to avoid parameter fine-tuning. Specifically, we propose a tun\textbf{\underline{I}}ng-free, a\textbf{\underline{D}}aptiv\textbf{\underline{E}}, univers\textbf{\underline{AL}} \textbf{\underline{Prompt}} Optimization Framework, abbreviated as \textit{\textbf{\ourmethod{}}} which consists of two stages: 1) Predefined Prompt, based on the reinforcement searching strategy, generate a prompt optimization strategy tree to acquire optimization priors; 2) Prompt Reflection initializes the prompt based on optimization priors, followed by self-reflection to further search and refine the prompt. By doing so, \ourmethod{} elegantly generates the ``ideal prompts'' for processing private domain-specific data. Note that our method requires no parameter fine-tuning and only a small amount of data to quickly adapt to the data distribution of private data. Extensive experiments across multiple tasks demonstrate that our proposed \ourmethod{} significantly improves both efficiency and performance compared to baselines.