 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomatic Operator-level Parallelism Planning for Distributed Deep Learning -- A Mixed-Integer Programming Approach
Paper and Code
Mar 12, 2025
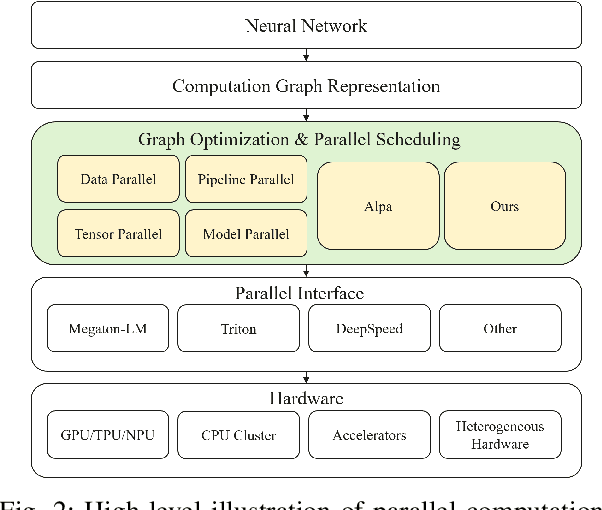
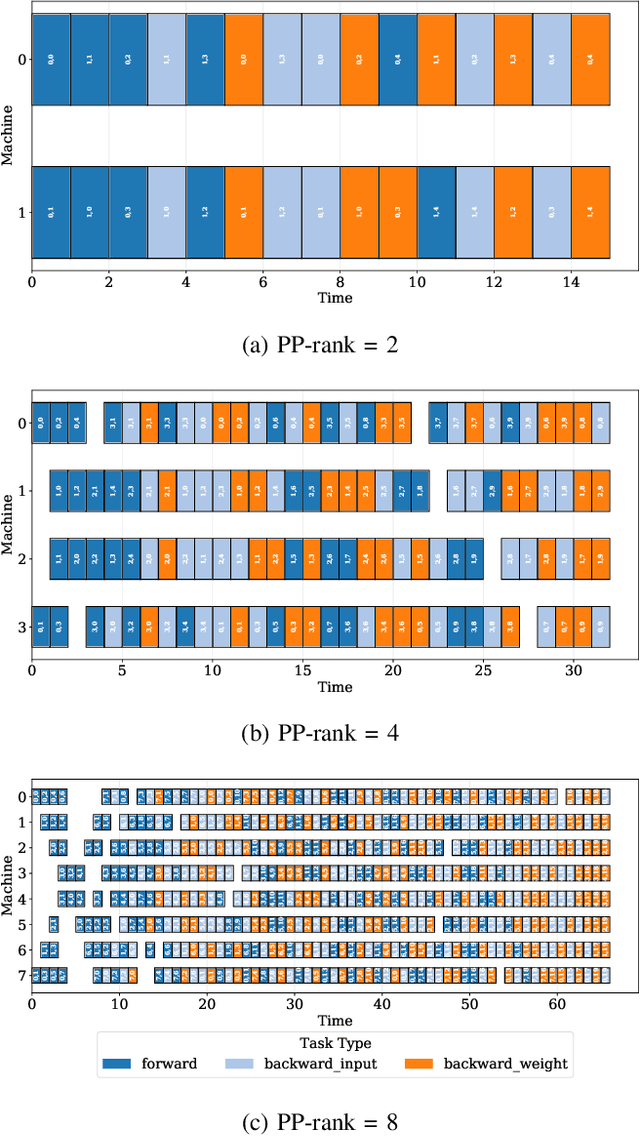
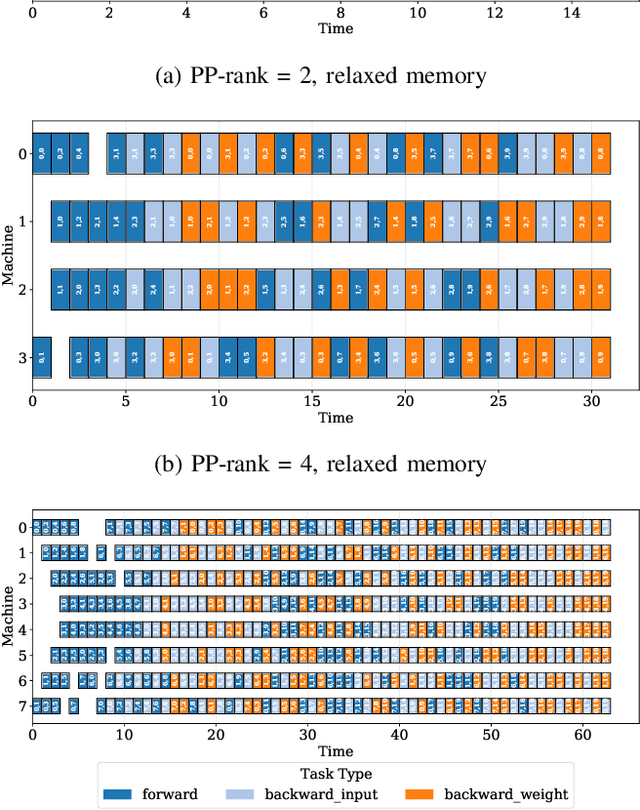
As the artificial intelligence community advances into the era of large models with billions of parameters, distributed training and inference have become essential. While various parallelism strategies-data, model, sequence, and pipeline-have been successfully implemented for popular neural networks on main-stream hardware, optimizing the distributed deployment schedule requires extensive expertise and manual effort. Further more, while existing frameworks with most simple chain-like structures, they struggle with complex non-linear architectures. Mixture-of-experts and multi-modal models feature intricate MIMO and branch-rich topologies that require fine-grained operator-level parallelization beyond the capabilities of existing frameworks. We propose formulating parallelism planning as a scheduling optimization problem using mixed-integer programming. We propose a bi-level solution framework balancing optimality with computational efficiency, automatically generating effective distributed plans that capture both the heterogeneous structure of modern neural networks and the underlying hardware constraints. In experiments comparing against expert-designed strategies like DeepSeek's DualPipe, our framework achieves comparable or superior performance, reducing computational bubbles by half under the same memory constraints. The framework's versatility extends beyond throughput optimization to incorporate hardware utilization maximization, memory capacity constraints, and other considerations or potential strategies. Such capabilities position our solution as both a valuable research tool for exploring optimal parallelization strategies and a practical industrial solution for large-scale AI deployment.