 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMerging Beyond: Streaming LLM Updates via Activation-Guided Rotations
Feb 03, 2026The escalating scale of Large Language Models (LLMs) necessitates efficient adaptation techniques. Model merging has gained prominence for its efficiency and controllability. However, existing merging techniques typically serve as post-hoc refinements or focus on mitigating task interference, often failing to capture the dynamic optimization benefits of supervised fine-tuning (SFT). In this work, we propose Streaming Merging, an innovative model updating paradigm that conceptualizes merging as an iterative optimization process. Central to this paradigm is \textbf{ARM} (\textbf{A}ctivation-guided \textbf{R}otation-aware \textbf{M}erging), a strategy designed to approximate gradient descent dynamics. By treating merging coefficients as learning rates and deriving rotation vectors from activation subspaces, ARM effectively steers parameter updates along data-driven trajectories. Unlike conventional linear interpolation, ARM aligns semantic subspaces to preserve the geometric structure of high-dimensional parameter evolution. Remarkably, ARM requires only early SFT checkpoints and, through iterative merging, surpasses the fully converged SFT model. Experimental results across model scales (1.7B to 14B) and diverse domains (e.g., math, code) demonstrate that ARM can transcend converged checkpoints. Extensive experiments show that ARM provides a scalable and lightweight framework for efficient model adaptation.
TempDiffReg: Temporal Diffusion Model for Non-Rigid 2D-3D Vascular Registration
Jan 26, 2026Transarterial chemoembolization (TACE) is a preferred treatment option for hepatocellular carcinoma and other liver malignancies, yet it remains a highly challenging procedure due to complex intra-operative vascular navigation and anatomical variability. Accurate and robust 2D-3D vessel registration is essential to guide microcatheter and instruments during TACE, enabling precise localization of vascular structures and optimal therapeutic targeting. To tackle this issue, we develop a coarse-to-fine registration strategy. First, we introduce a global alignment module, structure-aware perspective n-point (SA-PnP), to establish correspondence between 2D and 3D vessel structures. Second, we propose TempDiffReg, a temporal diffusion model that performs vessel deformation iteratively by leveraging temporal context to capture complex anatomical variations and local structural changes. We collected data from 23 patients and constructed 626 paired multi-frame samples for comprehensive evaluation. Experimental results demonstrate that the proposed method consistently outperforms state-of-the-art (SOTA) methods in both accuracy and anatomical plausibility. Specifically, our method achieves a mean squared error (MSE) of 0.63 mm and a mean absolute error (MAE) of 0.51 mm in registration accuracy, representing 66.7\% lower MSE and 17.7\% lower MAE compared to the most competitive existing approaches. It has the potential to assist less-experienced clinicians in safely and efficiently performing complex TACE procedures, ultimately enhancing both surgical outcomes and patient care. Code and data are available at: \textcolor{blue}{https://github.com/LZH970328/TempDiffReg.git}
RIFT: Repurposing Negative Samples via Reward-Informed Fine-Tuning
Jan 14, 2026While Supervised Fine-Tuning (SFT) and Rejection Sampling Fine-Tuning (RFT) are standard for LLM alignment, they either rely on costly expert data or discard valuable negative samples, leading to data inefficiency. To address this, we propose Reward Informed Fine-Tuning (RIFT), a simple yet effective framework that utilizes all self-generated samples. Unlike the hard thresholding of RFT, RIFT repurposes negative trajectories, reweighting the loss with scalar rewards to learn from both the positive and negative trajectories from the model outputs. To overcome the training collapse caused by naive reward integration, where direct multiplication yields an unbounded loss, we introduce a stabilized loss formulation that ensures numerical robustness and optimization efficiency. Extensive experiments on mathematical benchmarks across various base models show that RIFT consistently outperforms RFT. Our results demonstrate that RIFT is a robust and data-efficient alternative for alignment using mixed-quality, self-generated data.
Long-tailed Species Recognition in the NACTI Wildlife Dataset
Oct 24, 2025



As most ''in the wild'' data collections of the natural world, the North America Camera Trap Images (NACTI) dataset shows severe long-tailed class imbalance, noting that the largest 'Head' class alone covers >50% of the 3.7M images in the corpus. Building on the PyTorch Wildlife model, we present a systematic study of Long-Tail Recognition methodologies for species recognition on the NACTI dataset covering experiments on various LTR loss functions plus LTR-sensitive regularisation. Our best configuration achieves 99.40% Top-1 accuracy on our NACTI test data split, substantially improving over a 95.51% baseline using standard cross-entropy with Adam. This also improves on previously reported top performance in MLWIC2 at 96.8% albeit using partly unpublished (potentially different) partitioning, optimiser, and evaluation protocols. To evaluate domain shifts (e.g. night-time captures, occlusion, motion-blur) towards other datasets we construct a Reduced-Bias Test set from the ENA-Detection dataset where our experimentally optimised long-tail enhanced model achieves leading 52.55% accuracy (up from 51.20% with WCE loss), demonstrating stronger generalisation capabilities under distribution shift. We document the consistent improvements of LTR-enhancing scheduler choices in this NACTI wildlife domain, particularly when in tandem with state-of-the-art LTR losses. We finally discuss qualitative and quantitative shortcomings that LTR methods cannot sufficiently address, including catastrophic breakdown for 'Tail' classes under severe domain shift. For maximum reproducibility we publish all dataset splits, key code, and full network weights.
Activation-Guided Consensus Merging for Large Language Models
May 20, 2025Recent research has increasingly focused on reconciling the reasoning capabilities of System 2 with the efficiency of System 1. While existing training-based and prompt-based approaches face significant challenges in terms of efficiency and stability, model merging emerges as a promising strategy to integrate the diverse capabilities of different Large Language Models (LLMs) into a unified model. However, conventional model merging methods often assume uniform importance across layers, overlooking the functional heterogeneity inherent in neural components. To address this limitation, we propose \textbf{A}ctivation-Guided \textbf{C}onsensus \textbf{M}erging (\textbf{ACM}), a plug-and-play merging framework that determines layer-specific merging coefficients based on mutual information between activations of pre-trained and fine-tuned models. ACM effectively preserves task-specific capabilities without requiring gradient computations or additional training. Extensive experiments on Long-to-Short (L2S) and general merging tasks demonstrate that ACM consistently outperforms all baseline methods. For instance, in the case of Qwen-7B models, TIES-Merging equipped with ACM achieves a \textbf{55.3\%} reduction in response length while simultaneously improving reasoning accuracy by \textbf{1.3} points. We submit the code with the paper for reproducibility, and it will be publicly available.
Beyond Standard MoE: Mixture of Latent Experts for Resource-Efficient Language Models
Mar 29, 2025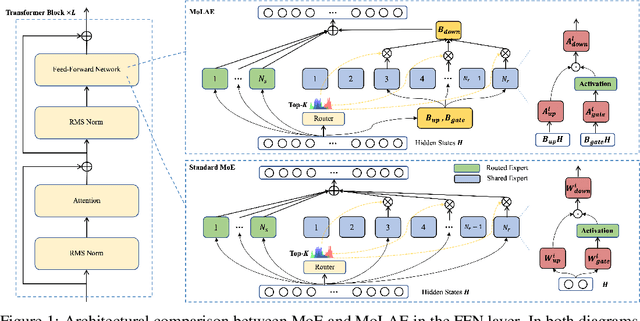


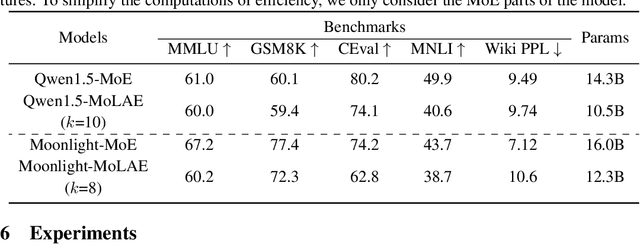
Mixture of Experts (MoE) has emerged as a pivotal architectural paradigm for efficient scaling of Large Language Models (LLMs), operating through selective activation of parameter subsets for each input token. Nevertheless, conventional MoE architectures encounter substantial challenges, including excessive memory utilization and communication overhead during training and inference, primarily attributable to the proliferation of expert modules. In this paper, we introduce Mixture of Latent Experts (MoLE), a novel parameterization methodology that facilitates the mapping of specific experts into a shared latent space. Specifically, all expert operations are systematically decomposed into two principal components: a shared projection into a lower-dimensional latent space, followed by expert-specific transformations with significantly reduced parametric complexity. This factorized approach substantially diminishes parameter count and computational requirements. Beyond the pretraining implementation of the MoLE architecture, we also establish a rigorous mathematical framework for transforming pre-trained MoE models into the MoLE architecture, characterizing the sufficient conditions for optimal factorization and developing a systematic two-phase algorithm for this conversion process. Our comprehensive theoretical analysis demonstrates that MoLE significantly enhances computational efficiency across multiple dimensions while preserving model representational capacity. Empirical evaluations corroborate our theoretical findings, confirming that MoLE achieves performance comparable to standard MoE implementations while substantially reducing resource requirements.
Unlocking Efficient Long-to-Short LLM Reasoning with Model Merging
Mar 26, 2025



The transition from System 1 to System 2 reasoning in large language models (LLMs) has marked significant advancements in handling complex tasks through deliberate, iterative thinking. However, this progress often comes at the cost of efficiency, as models tend to overthink, generating redundant reasoning steps without proportional improvements in output quality. Long-to-Short (L2S) reasoning has emerged as a promising solution to this challenge, aiming to balance reasoning depth with practical efficiency. While existing approaches, such as supervised fine-tuning (SFT), reinforcement learning (RL), and prompt engineering, have shown potential, they are either computationally expensive or unstable. Model merging, on the other hand, offers a cost-effective and robust alternative by integrating the quick-thinking capabilities of System 1 models with the methodical reasoning of System 2 models. In this work, we present a comprehensive empirical study on model merging for L2S reasoning, exploring diverse methodologies, including task-vector-based, SVD-based, and activation-informed merging. Our experiments reveal that model merging can reduce average response length by up to 55% while preserving or even improving baseline performance. We also identify a strong correlation between model scale and merging efficacy with extensive evaluations on 1.5B/7B/14B/32B models. Furthermore, we investigate the merged model's ability to self-critique and self-correct, as well as its adaptive response length based on task complexity. Our findings highlight model merging as a highly efficient and effective paradigm for L2S reasoning, offering a practical solution to the overthinking problem while maintaining the robustness of System 2 reasoning. This work can be found on Github https://github.com/hahahawu/Long-to-Short-via-Model-Merging.
Automatic Operator-level Parallelism Planning for Distributed Deep Learning -- A Mixed-Integer Programming Approach
Mar 12, 2025
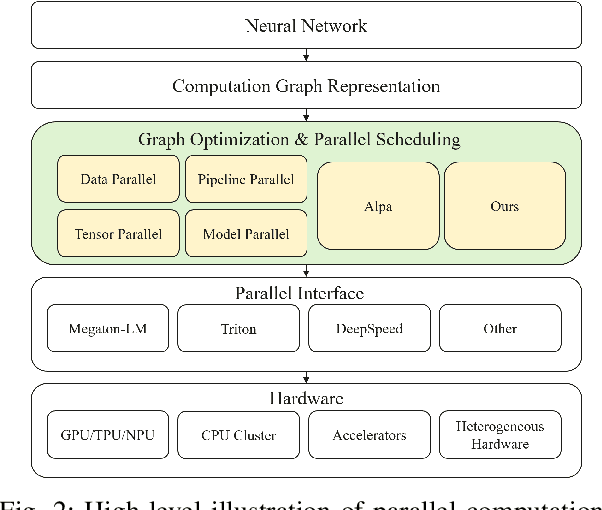
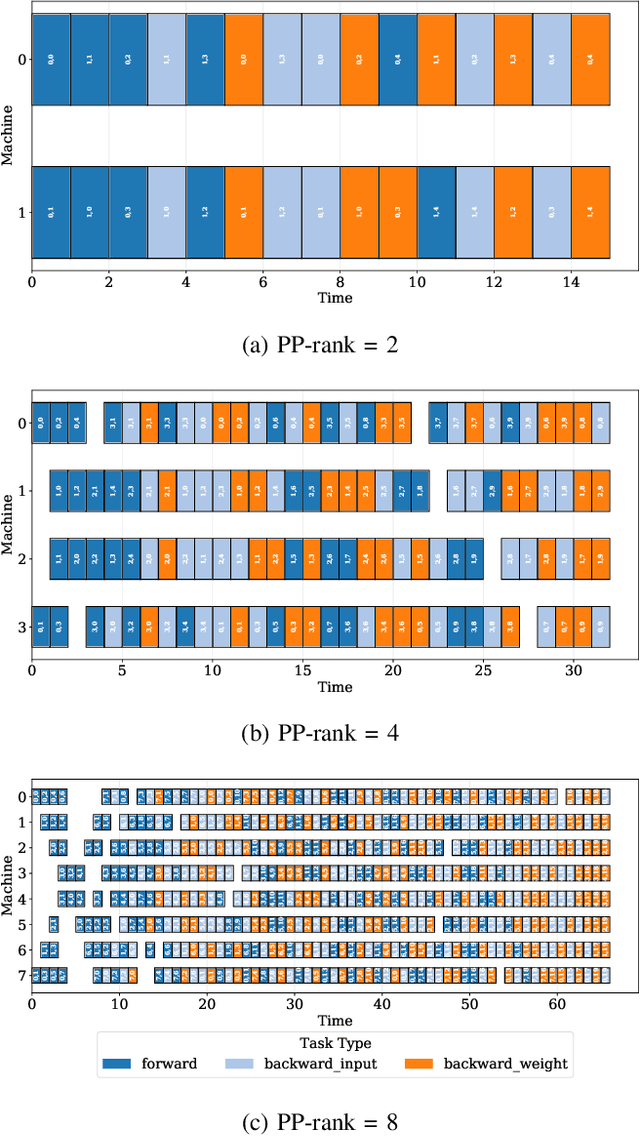
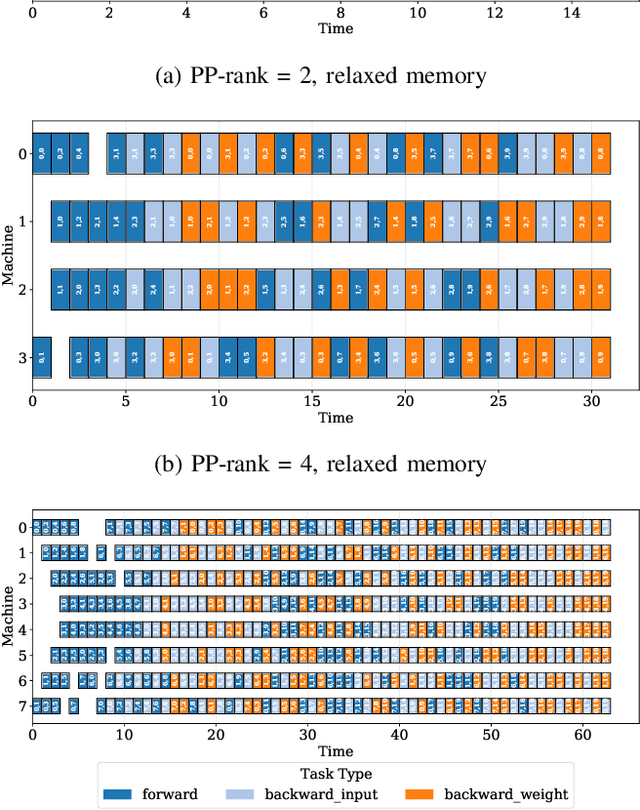
As the artificial intelligence community advances into the era of large models with billions of parameters, distributed training and inference have become essential. While various parallelism strategies-data, model, sequence, and pipeline-have been successfully implemented for popular neural networks on main-stream hardware, optimizing the distributed deployment schedule requires extensive expertise and manual effort. Further more, while existing frameworks with most simple chain-like structures, they struggle with complex non-linear architectures. Mixture-of-experts and multi-modal models feature intricate MIMO and branch-rich topologies that require fine-grained operator-level parallelization beyond the capabilities of existing frameworks. We propose formulating parallelism planning as a scheduling optimization problem using mixed-integer programming. We propose a bi-level solution framework balancing optimality with computational efficiency, automatically generating effective distributed plans that capture both the heterogeneous structure of modern neural networks and the underlying hardware constraints. In experiments comparing against expert-designed strategies like DeepSeek's DualPipe, our framework achieves comparable or superior performance, reducing computational bubbles by half under the same memory constraints. The framework's versatility extends beyond throughput optimization to incorporate hardware utilization maximization, memory capacity constraints, and other considerations or potential strategies. Such capabilities position our solution as both a valuable research tool for exploring optimal parallelization strategies and a practical industrial solution for large-scale AI deployment.
BPP-Search: Enhancing Tree of Thought Reasoning for Mathematical Modeling Problem Solving
Nov 26, 2024



LLMs exhibit advanced reasoning capabilities, offering the potential to transform natural language questions into mathematical models. However, existing open-source operations research datasets lack detailed annotations of the modeling process, such as variable definitions, focusing solely on objective values, which hinders reinforcement learning applications. To address this, we release the StructuredOR dataset, annotated with comprehensive labels that capture the complete mathematical modeling process. We further propose BPP-Search, a algorithm that integrates reinforcement learning into a tree-of-thought structure using Beam search, a Process reward model, and a pairwise Preference algorithm. This approach enables efficient exploration of tree structures, avoiding exhaustive search while improving accuracy. Extensive experiments on StructuredOR, NL4OPT, and MAMO-ComplexLP datasets show that BPP-Search significantly outperforms state-of-the-art methods, including Chain-of-Thought, Self-Consistency, and Tree-of-Thought. In tree-based reasoning, BPP-Search also surpasses Process Reward Model combined with Greedy or Beam Search, demonstrating superior accuracy and efficiency, and enabling faster retrieval of correct solutions.
Decoupling Training-Free Guided Diffusion by ADMM
Nov 18, 2024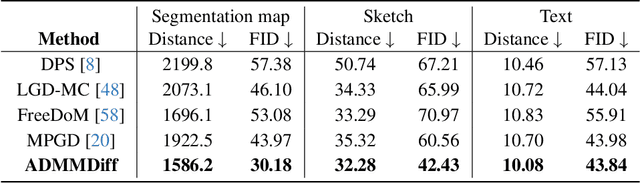
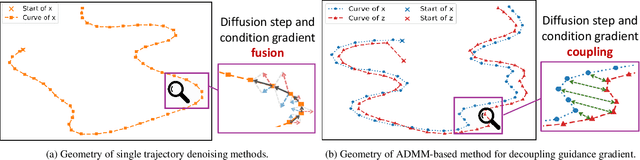


In this paper, we consider the conditional generation problem by guiding off-the-shelf unconditional diffusion models with differentiable loss functions in a plug-and-play fashion. While previous research has primarily focused on balancing the unconditional diffusion model and the guided loss through a tuned weight hyperparameter, we propose a novel framework that distinctly decouples these two components. Specifically, we introduce two variables ${x}$ and ${z}$, to represent the generated samples governed by the unconditional generation model and the guidance function, respectively. This decoupling reformulates conditional generation into two manageable subproblems, unified by the constraint ${x} = {z}$. Leveraging this setup, we develop a new algorithm based on the Alternating Direction Method of Multipliers (ADMM) to adaptively balance these components. Additionally, we establish the equivalence between the diffusion reverse step and the proximal operator of ADMM and provide a detailed convergence analysis of our algorithm under certain mild assumptions. Our experiments demonstrate that our proposed method ADMMDiff consistently generates high-quality samples while ensuring strong adherence to the conditioning criteria. It outperforms existing methods across a range of conditional generation tasks, including image generation with various guidance and controllable motion synthesis.