 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen More Experts Hurt: Underfitting in Multi-Expert Learning to Defer
Feb 19, 2026Learning to Defer (L2D) enables a classifier to abstain from predictions and defer to an expert, and has recently been extended to multi-expert settings. In this work, we show that multi-expert L2D is fundamentally more challenging than the single-expert case. With multiple experts, the classifier's underfitting becomes inherent, which seriously degrades prediction performance, whereas in the single-expert setting it arises only under specific conditions. We theoretically reveal that this stems from an intrinsic expert identifiability issue: learning which expert to trust from a diverse pool, a problem absent in the single-expert case and renders existing underfitting remedies failed. To tackle this issue, we propose PiCCE (Pick the Confident and Correct Expert), a surrogate-based method that adaptively identifies a reliable expert based on empirical evidence. PiCCE effectively reduces multi-expert L2D to a single-expert-like learning problem, thereby resolving multi expert underfitting. We further prove its statistical consistency and ability to recover class probabilities and expert accuracies. Extensive experiments across diverse settings, including real-world expert scenarios, validate our theoretical results and demonstrate improved performance.
Merging Beyond: Streaming LLM Updates via Activation-Guided Rotations
Feb 03, 2026The escalating scale of Large Language Models (LLMs) necessitates efficient adaptation techniques. Model merging has gained prominence for its efficiency and controllability. However, existing merging techniques typically serve as post-hoc refinements or focus on mitigating task interference, often failing to capture the dynamic optimization benefits of supervised fine-tuning (SFT). In this work, we propose Streaming Merging, an innovative model updating paradigm that conceptualizes merging as an iterative optimization process. Central to this paradigm is \textbf{ARM} (\textbf{A}ctivation-guided \textbf{R}otation-aware \textbf{M}erging), a strategy designed to approximate gradient descent dynamics. By treating merging coefficients as learning rates and deriving rotation vectors from activation subspaces, ARM effectively steers parameter updates along data-driven trajectories. Unlike conventional linear interpolation, ARM aligns semantic subspaces to preserve the geometric structure of high-dimensional parameter evolution. Remarkably, ARM requires only early SFT checkpoints and, through iterative merging, surpasses the fully converged SFT model. Experimental results across model scales (1.7B to 14B) and diverse domains (e.g., math, code) demonstrate that ARM can transcend converged checkpoints. Extensive experiments show that ARM provides a scalable and lightweight framework for efficient model adaptation.
RIFT: Repurposing Negative Samples via Reward-Informed Fine-Tuning
Jan 14, 2026While Supervised Fine-Tuning (SFT) and Rejection Sampling Fine-Tuning (RFT) are standard for LLM alignment, they either rely on costly expert data or discard valuable negative samples, leading to data inefficiency. To address this, we propose Reward Informed Fine-Tuning (RIFT), a simple yet effective framework that utilizes all self-generated samples. Unlike the hard thresholding of RFT, RIFT repurposes negative trajectories, reweighting the loss with scalar rewards to learn from both the positive and negative trajectories from the model outputs. To overcome the training collapse caused by naive reward integration, where direct multiplication yields an unbounded loss, we introduce a stabilized loss formulation that ensures numerical robustness and optimization efficiency. Extensive experiments on mathematical benchmarks across various base models show that RIFT consistently outperforms RFT. Our results demonstrate that RIFT is a robust and data-efficient alternative for alignment using mixed-quality, self-generated data.
Activation-Guided Consensus Merging for Large Language Models
May 20, 2025Recent research has increasingly focused on reconciling the reasoning capabilities of System 2 with the efficiency of System 1. While existing training-based and prompt-based approaches face significant challenges in terms of efficiency and stability, model merging emerges as a promising strategy to integrate the diverse capabilities of different Large Language Models (LLMs) into a unified model. However, conventional model merging methods often assume uniform importance across layers, overlooking the functional heterogeneity inherent in neural components. To address this limitation, we propose \textbf{A}ctivation-Guided \textbf{C}onsensus \textbf{M}erging (\textbf{ACM}), a plug-and-play merging framework that determines layer-specific merging coefficients based on mutual information between activations of pre-trained and fine-tuned models. ACM effectively preserves task-specific capabilities without requiring gradient computations or additional training. Extensive experiments on Long-to-Short (L2S) and general merging tasks demonstrate that ACM consistently outperforms all baseline methods. For instance, in the case of Qwen-7B models, TIES-Merging equipped with ACM achieves a \textbf{55.3\%} reduction in response length while simultaneously improving reasoning accuracy by \textbf{1.3} points. We submit the code with the paper for reproducibility, and it will be publicly available.
Unlocking Efficient Long-to-Short LLM Reasoning with Model Merging
Mar 26, 2025



The transition from System 1 to System 2 reasoning in large language models (LLMs) has marked significant advancements in handling complex tasks through deliberate, iterative thinking. However, this progress often comes at the cost of efficiency, as models tend to overthink, generating redundant reasoning steps without proportional improvements in output quality. Long-to-Short (L2S) reasoning has emerged as a promising solution to this challenge, aiming to balance reasoning depth with practical efficiency. While existing approaches, such as supervised fine-tuning (SFT), reinforcement learning (RL), and prompt engineering, have shown potential, they are either computationally expensive or unstable. Model merging, on the other hand, offers a cost-effective and robust alternative by integrating the quick-thinking capabilities of System 1 models with the methodical reasoning of System 2 models. In this work, we present a comprehensive empirical study on model merging for L2S reasoning, exploring diverse methodologies, including task-vector-based, SVD-based, and activation-informed merging. Our experiments reveal that model merging can reduce average response length by up to 55% while preserving or even improving baseline performance. We also identify a strong correlation between model scale and merging efficacy with extensive evaluations on 1.5B/7B/14B/32B models. Furthermore, we investigate the merged model's ability to self-critique and self-correct, as well as its adaptive response length based on task complexity. Our findings highlight model merging as a highly efficient and effective paradigm for L2S reasoning, offering a practical solution to the overthinking problem while maintaining the robustness of System 2 reasoning. This work can be found on Github https://github.com/hahahawu/Long-to-Short-via-Model-Merging.
Sens-Merging: Sensitivity-Guided Parameter Balancing for Merging Large Language Models
Feb 19, 2025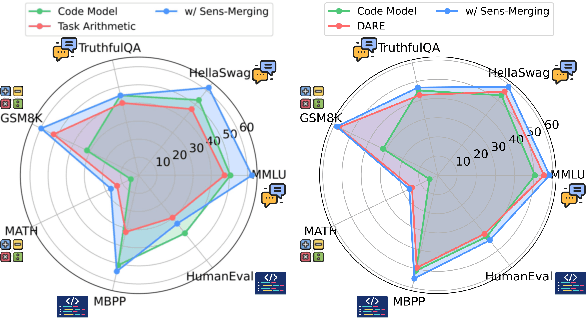
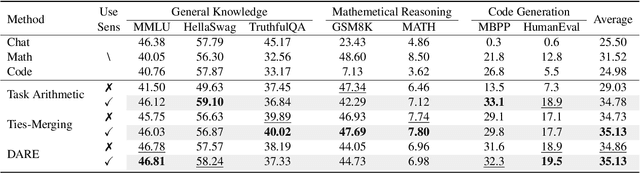
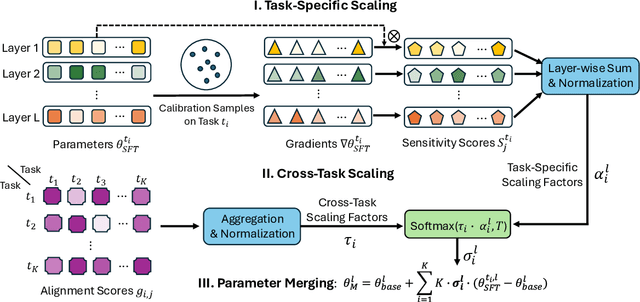
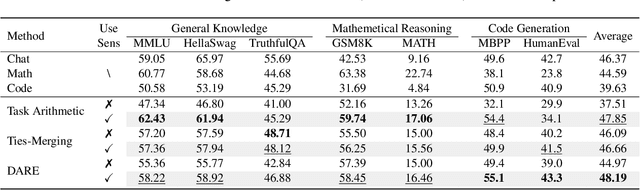
Recent advances in large language models have led to numerous task-specialized fine-tuned variants, creating a need for efficient model merging techniques that preserve specialized capabilities while avoiding costly retraining. While existing task vector-based merging methods show promise, they typically apply uniform coefficients across all parameters, overlooking varying parameter importance both within and across tasks. We present Sens-Merging, a sensitivity-guided coefficient adjustment method that enhances existing model merging techniques by operating at both task-specific and cross-task levels. Our method analyzes parameter sensitivity within individual tasks and evaluates cross-task transferability to determine optimal merging coefficients. Extensive experiments on Mistral 7B and LLaMA2-7B/13B models demonstrate that Sens-Merging significantly improves performance across general knowledge, mathematical reasoning, and code generation tasks. Notably, when combined with existing merging techniques, our method enables merged models to outperform specialized fine-tuned models, particularly in code generation tasks. Our findings reveal important trade-offs between task-specific and cross-task scalings, providing insights for future model merging strategies.
Bi-Chainer: Automated Large Language Models Reasoning with Bidirectional Chaining
Jun 05, 2024Large Language Models (LLMs) have shown human-like reasoning abilities but still face challenges in solving complex logical problems. Existing unidirectional chaining methods, such as forward chaining and backward chaining, suffer from issues like low prediction accuracy and efficiency. To address these, we propose a bidirectional chaining method, Bi-Chainer, which dynamically switches to depth-first reasoning in the opposite reasoning direction when it encounters multiple branching options within the current direction. Thus, the intermediate reasoning results can be utilized as guidance to facilitate the reasoning process. We show that Bi-Chainer achieves sizable accuracy boots over unidirectional chaining frameworks on four challenging logical reasoning datasets. Moreover, Bi-Chainer enhances the accuracy of intermediate proof steps and reduces the average number of inference calls, resulting in more efficient and accurate reasoning.
Towards Better Understanding with Uniformity and Explicit Regularization of Embeddings in Embedding-based Neural Topic Models
Jun 16, 2022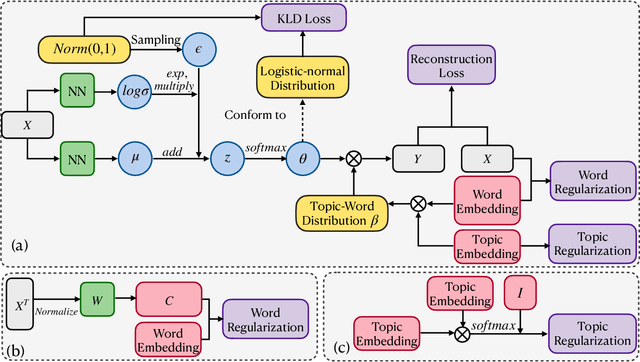
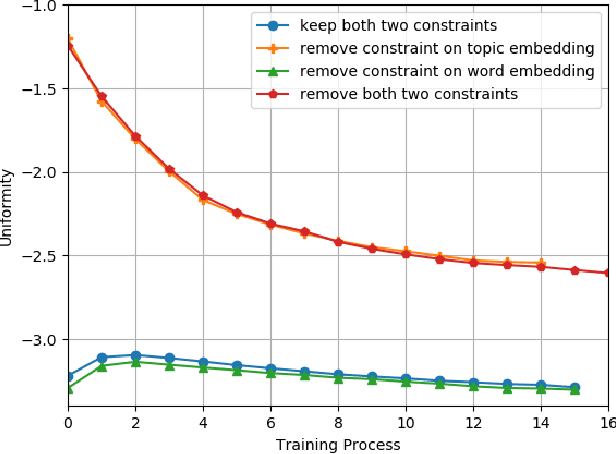
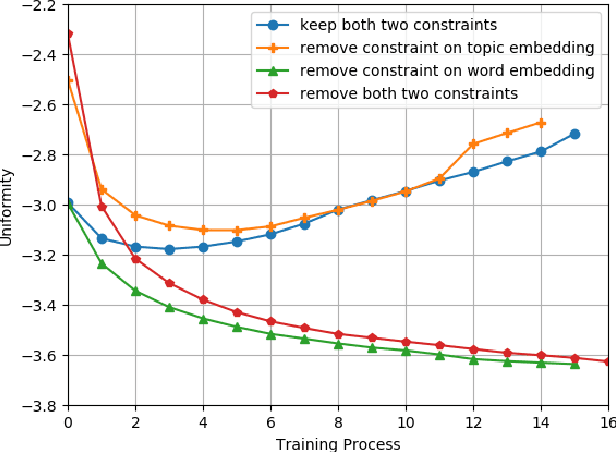
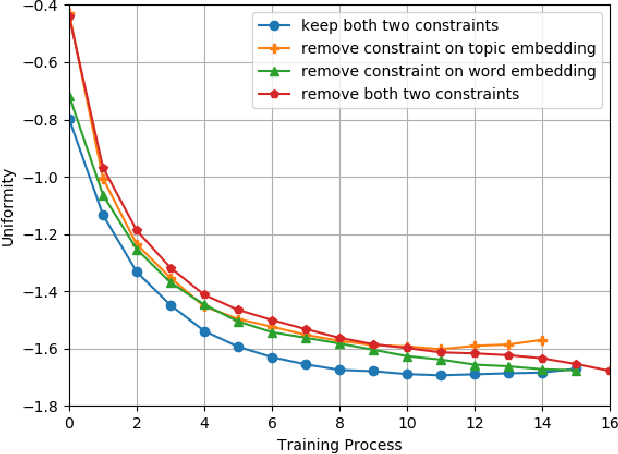
Embedding-based neural topic models could explicitly represent words and topics by embedding them to a homogeneous feature space, which shows higher interpretability. However, there are no explicit constraints for the training of embeddings, leading to a larger optimization space. Also, a clear description of the changes in embeddings and the impact on model performance is still lacking. In this paper, we propose an embedding regularized neural topic model, which applies the specially designed training constraints on word embedding and topic embedding to reduce the optimization space of parameters. To reveal the changes and roles of embeddings, we introduce \textbf{uniformity} into the embedding-based neural topic model as the evaluation metric of embedding space. On this basis, we describe how embeddings tend to change during training via the changes in the uniformity of embeddings. Furthermore, we demonstrate the impact of changes in embeddings in embedding-based neural topic models through ablation studies. The results of experiments on two mainstream datasets indicate that our model significantly outperforms baseline models in terms of the harmony between topic quality and document modeling. This work is the first attempt to exploit uniformity to explore changes in embeddings of embedding-based neural topic models and their impact on model performance to the best of our knowledge.
Zero-shot Cross-lingual Conversational Semantic Role Labeling
Apr 11, 2022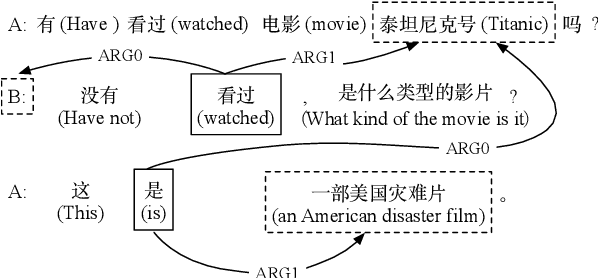

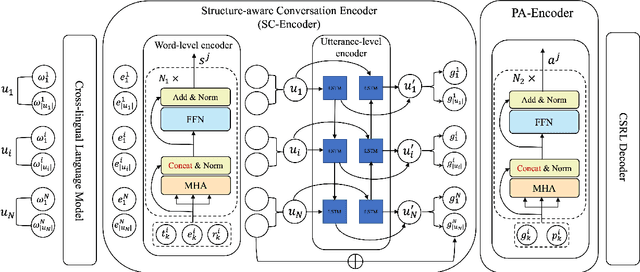
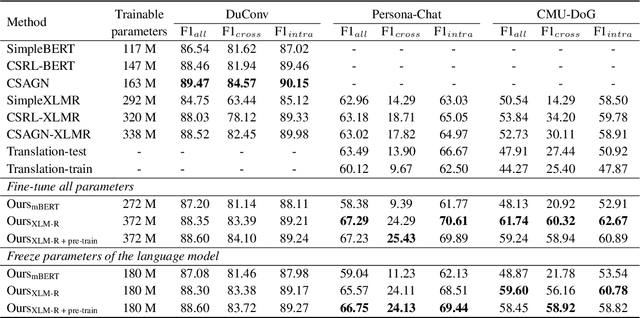
While conversational semantic role labeling (CSRL) has shown its usefulness on Chinese conversational tasks, it is still under-explored in non-Chinese languages due to the lack of multilingual CSRL annotations for the parser training. To avoid expensive data collection and error-propagation of translation-based methods, we present a simple but effective approach to perform zero-shot cross-lingual CSRL. Our model implicitly learns language-agnostic, conversational structure-aware and semantically rich representations with the hierarchical encoders and elaborately designed pre-training objectives. Experimental results show that our model outperforms all baselines by large margins on two newly collected English CSRL test sets. More importantly, we confirm the usefulness of CSRL to non-Chinese conversational tasks such as the question-in-context rewriting task in English and the multi-turn dialogue response generation tasks in English, German and Japanese by incorporating the CSRL information into the downstream conversation-based models. We believe this finding is significant and will facilitate the research of non-Chinese dialogue tasks which suffer the problems of ellipsis and anaphora.
Phocus: Picking Valuable Research from a Sea of Citations
Jan 14, 2022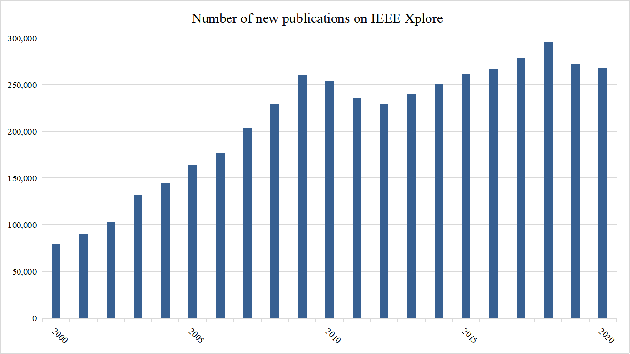
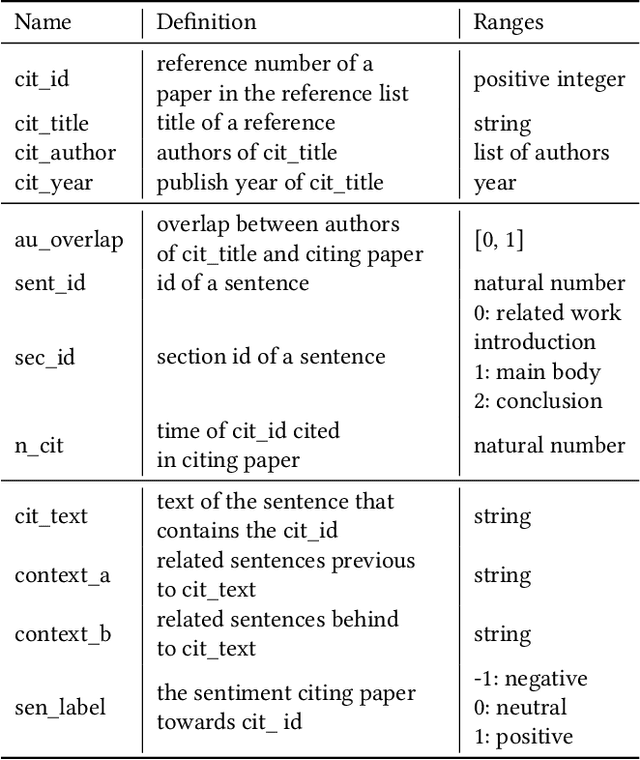
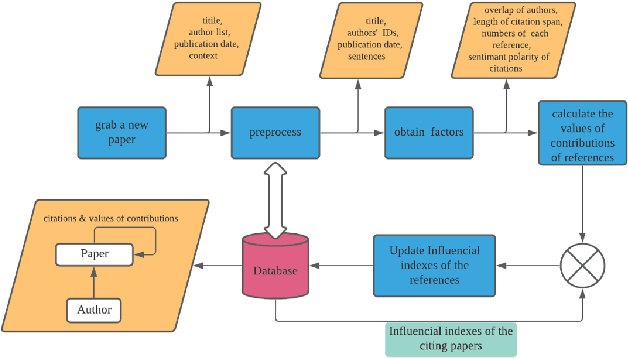

The deluge of new papers has significantly blocked the development of academics, which is mainly caused by author-level and publication-level evaluation metrics that only focus on quantity. Those metrics have resulted in several severe problems that trouble scholars focusing on the important research direction for a long time and even promote an impetuous academic atmosphere. To solve those problems, we propose Phocus, a novel academic evaluation mechanism for authors and papers. Phocus analyzes the sentence containing a citation and its contexts to predict the sentiment towards the corresponding reference. Combining others factors, Phocus classifies citations coarsely, ranks all references within a paper, and utilizes the results of the classifier and the ranking model to get the local influential factor of a reference to the citing paper. The global influential factor of the reference to the citing paper is the product of the local influential factor and the total influential factor of the citing paper. Consequently, an author's academic influential factor is the sum of his contributions to each paper he co-authors.