 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStuffed Mamba: State Collapse and State Capacity of RNN-Based Long-Context Modeling
Oct 09, 2024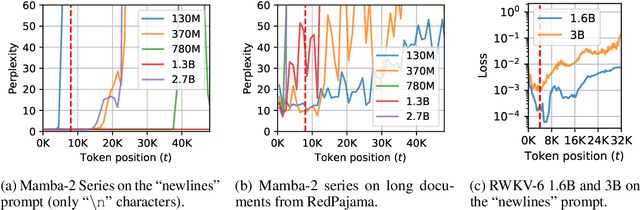
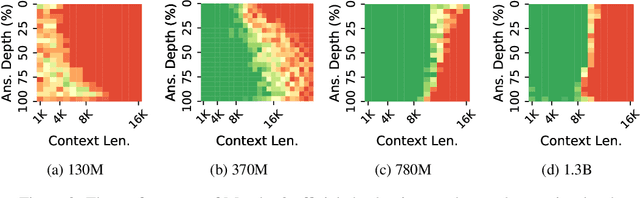
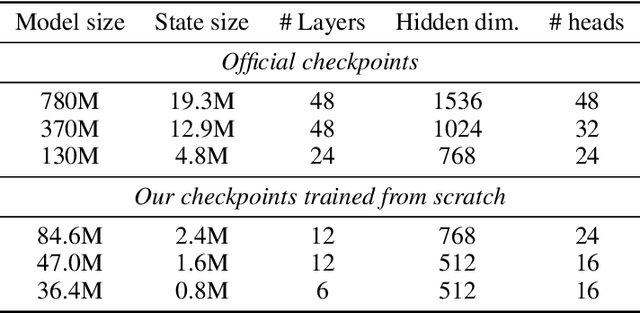
One essential advantage of recurrent neural networks (RNNs) over transformer-based language models is their linear computational complexity concerning the sequence length, which makes them much faster in handling long sequences during inference. However, most publicly available RNNs (e.g., Mamba and RWKV) are trained on sequences with less than 10K tokens, and their effectiveness in longer contexts remains largely unsatisfying so far. In this paper, we study the cause of the inability to process long context for RNNs and suggest critical mitigations. We examine two practical concerns when applying state-of-the-art RNNs to long contexts: (1) the inability to extrapolate to inputs longer than the training length and (2) the upper bound of memory capacity. Addressing the first concern, we first investigate *state collapse* (SC), a phenomenon that causes severe performance degradation on sequence lengths not encountered during training. With controlled experiments, we attribute this to overfitting due to the recurrent state being overparameterized for the training length. For the second concern, we train a series of Mamba-2 models on long documents to empirically estimate the recurrent state capacity in language modeling and passkey retrieval. Then, three SC mitigation methods are proposed to improve Mamba-2's length generalizability, allowing the model to process more than 1M tokens without SC. We also find that the recurrent state capacity in passkey retrieval scales exponentially to the state size, and we empirically train a Mamba-2 370M with near-perfect passkey retrieval accuracy on 256K context length. This suggests a promising future for RNN-based long-context modeling.
Beyond the Turn-Based Game: Enabling Real-Time Conversations with Duplex Models
Jun 22, 2024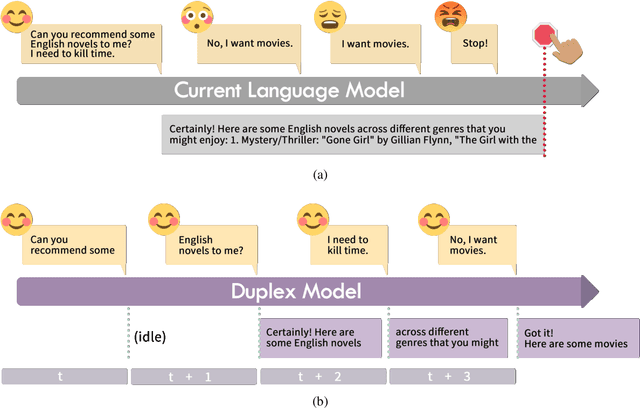
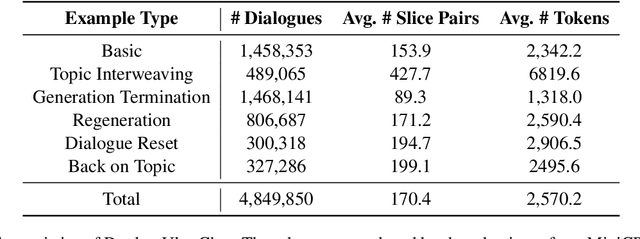

As large language models (LLMs) increasingly permeate daily lives, there is a growing demand for real-time interactions that mirror human conversations. Traditional turn-based chat systems driven by LLMs prevent users from verbally interacting with the system while it is generating responses. To overcome these limitations, we adapt existing LLMs to \textit{duplex models} so that these LLMs can listen for users while generating output and dynamically adjust themselves to provide users with instant feedback. % such as in response to interruptions. Specifically, we divide the queries and responses of conversations into several time slices and then adopt a time-division-multiplexing (TDM) encoding-decoding strategy to pseudo-simultaneously process these slices. Furthermore, to make LLMs proficient enough to handle real-time conversations, we build a fine-tuning dataset consisting of alternating time slices of queries and responses as well as covering typical feedback types in instantaneous interactions. Our experiments show that although the queries and responses of conversations are segmented into incomplete slices for processing, LLMs can preserve their original performance on standard benchmarks with a few fine-tuning steps on our dataset. Automatic and human evaluation indicate that duplex models make user-AI interactions more natural and human-like, and greatly improve user satisfaction compared to vanilla LLMs. Our duplex model and dataset will be released.
MiniCPM: Unveiling the Potential of Small Language Models with Scalable Training Strategies
Apr 09, 2024


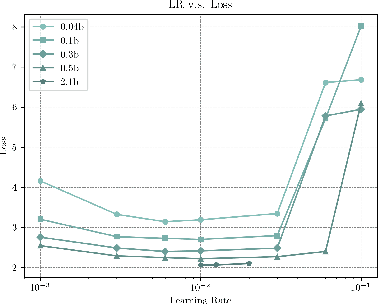
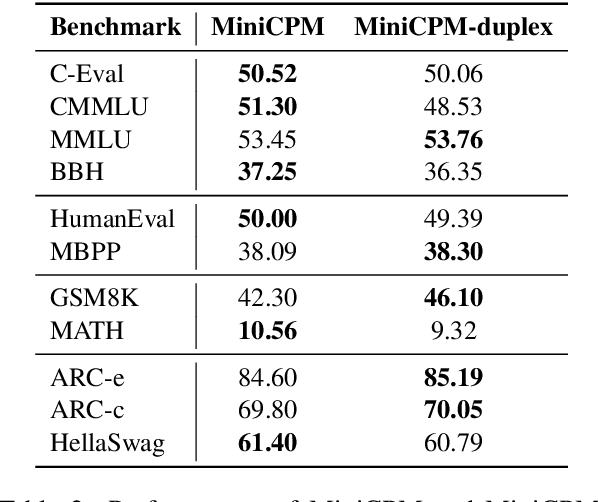
The burgeoning interest in developing Large Language Models (LLMs) with up to trillion parameters has been met with concerns regarding resource efficiency and practical expense, particularly given the immense cost of experimentation. This scenario underscores the importance of exploring the potential of Small Language Models (SLMs) as a resource-efficient alternative. In this context, we introduce MiniCPM, specifically the 1.2B and 2.4B non-embedding parameter variants, not only excel in their respective categories but also demonstrate capabilities on par with 7B-13B LLMs. While focusing on SLMs, our approach exhibits scalability in both model and data dimensions for future LLM research. Regarding model scaling, we employ extensive model wind tunnel experiments for stable and optimal scaling. For data scaling, we introduce a Warmup-Stable-Decay (WSD) learning rate scheduler (LRS), conducive to continuous training and domain adaptation. We present an in-depth analysis of the intriguing training dynamics that occurred in the WSD LRS. With WSD LRS, we are now able to efficiently study data-model scaling law without extensive retraining experiments on both axes of model and data, from which we derive the much higher compute optimal data-model ratio than Chinchilla Optimal. Additionally, we introduce MiniCPM family, including MiniCPM-DPO, MiniCPM-MoE and MiniCPM-128K, whose excellent performance further cementing MiniCPM's foundation in diverse SLM applications. MiniCPM models are available publicly at https://github.com/OpenBMB/MiniCPM .
$\infty$Bench: Extending Long Context Evaluation Beyond 100K Tokens
Feb 24, 2024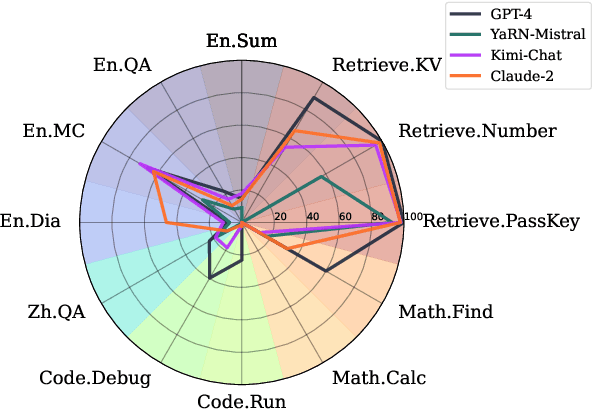
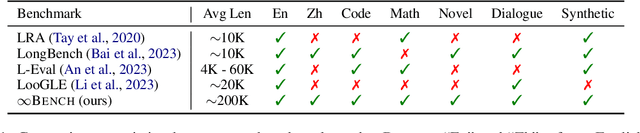
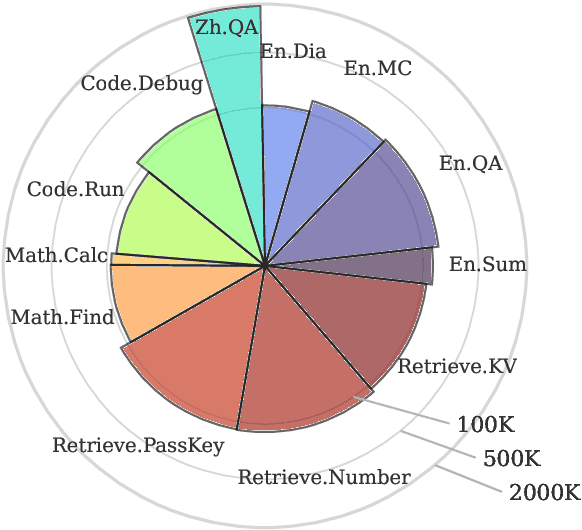
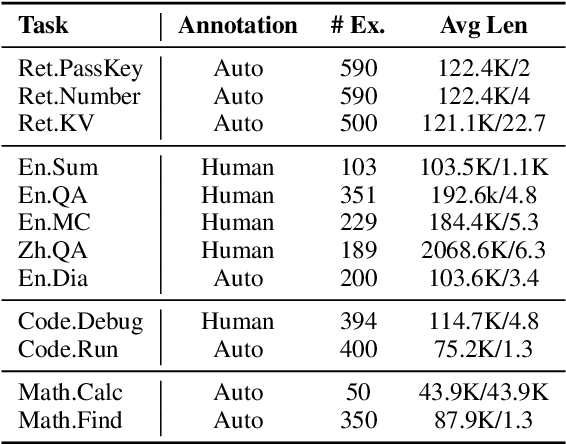
Processing and reasoning over long contexts is crucial for many practical applications of Large Language Models (LLMs), such as document comprehension and agent construction. Despite recent strides in making LLMs process contexts with more than 100K tokens, there is currently a lack of a standardized benchmark to evaluate this long-context capability. Existing public benchmarks typically focus on contexts around 10K tokens, limiting the assessment and comparison of LLMs in processing longer contexts. In this paper, we propose $\infty$Bench, the first LLM benchmark featuring an average data length surpassing 100K tokens. $\infty$Bench comprises synthetic and realistic tasks spanning diverse domains, presented in both English and Chinese. The tasks in $\infty$Bench are designed to require well understanding of long dependencies in contexts, and make simply retrieving a limited number of passages from contexts not sufficient for these tasks. In our experiments, based on $\infty$Bench, we evaluate the state-of-the-art proprietary and open-source LLMs tailored for processing long contexts. The results indicate that existing long context LLMs still require significant advancements to effectively process 100K+ context. We further present three intriguing analyses regarding the behavior of LLMs processing long context.
Unlock Predictable Scaling from Emergent Abilities
Oct 05, 2023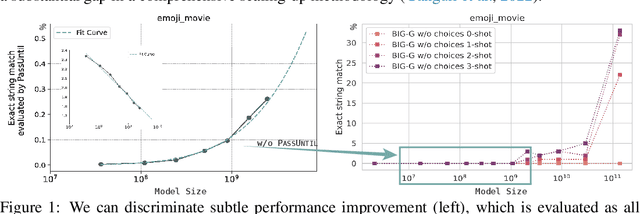

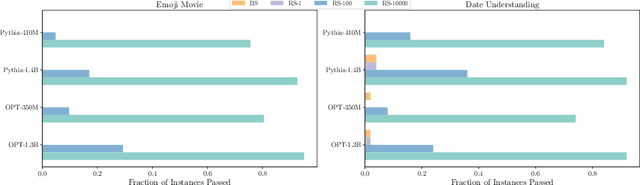

The scientific scale-up of large language models (LLMs) necessitates a comprehensive understanding of their scaling properties. However, the existing literature on the scaling properties only yields an incomplete answer: optimization loss decreases predictably as the model size increases, in line with established scaling law; yet no scaling law for task has been established and the task performances are far from predictable during scaling. Task performances typically show minor gains on small models until they improve dramatically once models exceed a size threshold, exemplifying the ``emergent abilities''. In this study, we discover that small models, although they exhibit minor performance, demonstrate critical and consistent task performance improvements that are not captured by conventional evaluation strategies due to insufficient measurement resolution. To measure such improvements, we introduce PassUntil, an evaluation strategy through massive sampling in the decoding phase. We conduct quantitative investigations into the scaling law of task performance. Firstly, a strict task scaling law is identified, enhancing the predictability of task performances. Remarkably, we are able to predict the performance of the 2.4B model on code generation with merely 0.05\% deviation before training starts. Secondly, underpinned by PassUntil, we observe concrete evidence of emergent abilities and ascertain that they are not in conflict with the continuity of performance improvement. Their semblance to break-through is that their scaling curve cannot be fitted by standard scaling law function. We then introduce a mathematical definition for the emergent abilities. Through the definition, we refute a prevalent ``multi-step reasoning hypothesis'' regarding the genesis of emergent abilities and propose a new hypothesis with a satisfying fit to the observed scaling curve.
Phocus: Picking Valuable Research from a Sea of Citations
Jan 14, 2022
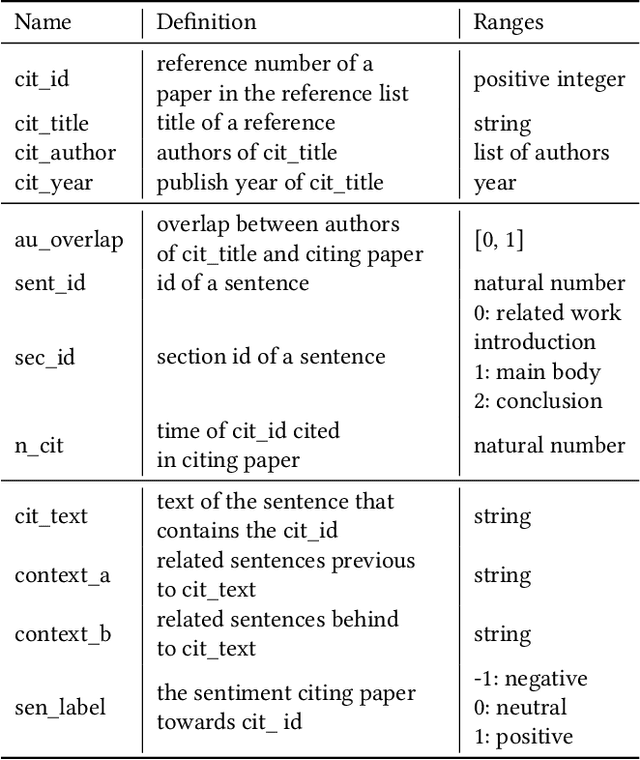
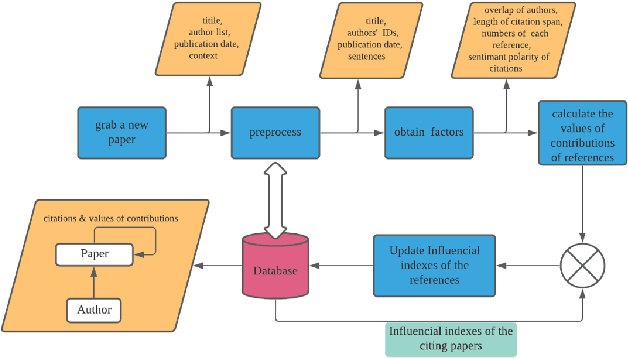

The deluge of new papers has significantly blocked the development of academics, which is mainly caused by author-level and publication-level evaluation metrics that only focus on quantity. Those metrics have resulted in several severe problems that trouble scholars focusing on the important research direction for a long time and even promote an impetuous academic atmosphere. To solve those problems, we propose Phocus, a novel academic evaluation mechanism for authors and papers. Phocus analyzes the sentence containing a citation and its contexts to predict the sentiment towards the corresponding reference. Combining others factors, Phocus classifies citations coarsely, ranks all references within a paper, and utilizes the results of the classifier and the ranking model to get the local influential factor of a reference to the citing paper. The global influential factor of the reference to the citing paper is the product of the local influential factor and the total influential factor of the citing paper. Consequently, an author's academic influential factor is the sum of his contributions to each paper he co-authors.