 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnlock Predictable Scaling from Emergent Abilities
Oct 05, 2023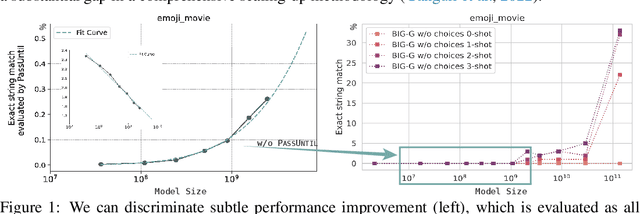

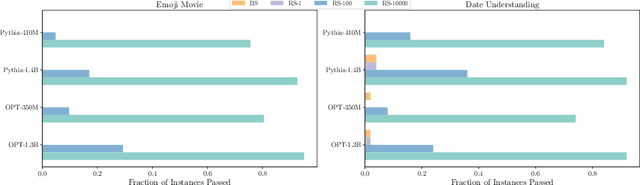

The scientific scale-up of large language models (LLMs) necessitates a comprehensive understanding of their scaling properties. However, the existing literature on the scaling properties only yields an incomplete answer: optimization loss decreases predictably as the model size increases, in line with established scaling law; yet no scaling law for task has been established and the task performances are far from predictable during scaling. Task performances typically show minor gains on small models until they improve dramatically once models exceed a size threshold, exemplifying the ``emergent abilities''. In this study, we discover that small models, although they exhibit minor performance, demonstrate critical and consistent task performance improvements that are not captured by conventional evaluation strategies due to insufficient measurement resolution. To measure such improvements, we introduce PassUntil, an evaluation strategy through massive sampling in the decoding phase. We conduct quantitative investigations into the scaling law of task performance. Firstly, a strict task scaling law is identified, enhancing the predictability of task performances. Remarkably, we are able to predict the performance of the 2.4B model on code generation with merely 0.05\% deviation before training starts. Secondly, underpinned by PassUntil, we observe concrete evidence of emergent abilities and ascertain that they are not in conflict with the continuity of performance improvement. Their semblance to break-through is that their scaling curve cannot be fitted by standard scaling law function. We then introduce a mathematical definition for the emergent abilities. Through the definition, we refute a prevalent ``multi-step reasoning hypothesis'' regarding the genesis of emergent abilities and propose a new hypothesis with a satisfying fit to the observed scaling curve.
A Curriculum View of Robust Loss Functions
May 03, 2023Robust loss functions are designed to combat the adverse impacts of label noise, whose robustness is typically supported by theoretical bounds agnostic to the training dynamics. However, these bounds may fail to characterize the empirical performance as it remains unclear why robust loss functions can underfit. We show that most loss functions can be rewritten into a form with the same class-score margin and different sample-weighting functions. The resulting curriculum view provides a straightforward analysis of the training dynamics, which helps attribute underfitting to diminished average sample weights and noise robustness to larger weights for clean samples. We show that simple fixes to the curriculums can make underfitting robust loss functions competitive with the state-of-the-art, and training schedules can substantially affect the noise robustness even with robust loss functions. Code is available at \url{github}.
GEMINI: Controlling the Sentence-level Writing Style for Abstractive Text Summarization
Apr 07, 2023Human experts write summaries using different techniques, including rewriting a sentence in the document or fusing multiple sentences to generate a summary sentence. These techniques are flexible and thus difficult to be imitated by any single method. To address this issue, we propose an adaptive model, GEMINI, that integrates a rewriter and a fuser to mimic the sentence rewriting and fusion techniques, respectively. GEMINI adaptively chooses to rewrite a specific document sentence or generate a summary sentence from scratch. Experiments demonstrate that our adaptive approach outperforms the pure abstractive and rewriting baselines on various benchmark datasets, especially when the dataset has a balanced distribution of styles. Interestingly, empirical results show that the human writing style of each summary sentence is consistently predictable given its context.
On the Role of Pre-trained Language Models in Word Ordering: A Case Study with BART
Apr 15, 2022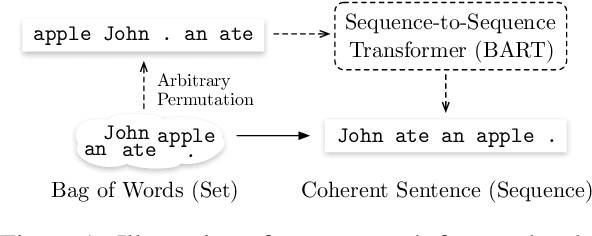
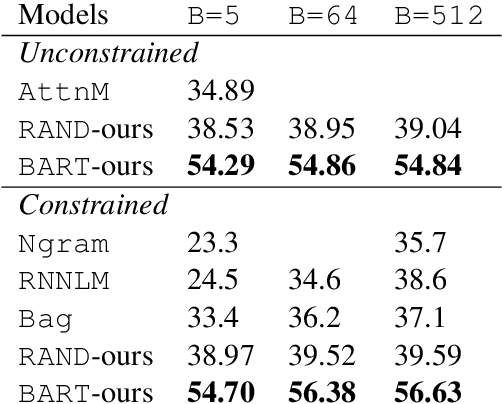
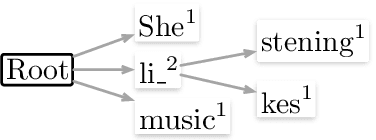
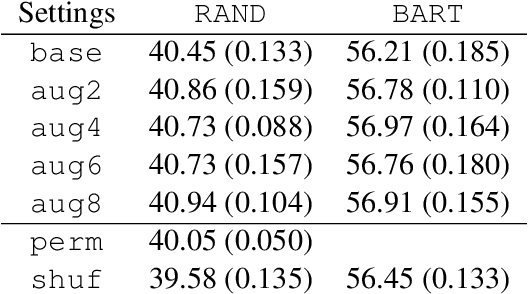
Word ordering is a constrained language generation task taking unordered words as input. Existing work uses linear models and neural networks for the task, yet pre-trained language models have not been studied in word ordering, let alone why they help. We use BART as an instance and show its effectiveness in the task. To explain why BART helps word ordering, we extend analysis with probing and empirically identify that syntactic dependency knowledge in BART is a reliable explanation. We also report performance gains with BART in the related partial tree linearization task, which readily extends our analysis.