 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniSRCodec: Unified and Low-Bitrate Single Codebook Codec with Sub-Band Reconstruction
Jan 06, 2026Neural Audio Codecs (NACs) can reduce transmission overhead by performing compact compression and reconstruction, which also aim to bridge the gap between continuous and discrete signals. Existing NACs can be divided into two categories: multi-codebook and single-codebook codecs. Multi-codebook codecs face challenges such as structural complexity and difficulty in adapting to downstream tasks, while single-codebook codecs, though structurally simpler, suffer from low-fidelity, ineffective modeling of unified audio, and an inability to support modeling of high-frequency audio. We propose the UniSRCodec, a single-codebook codec capable of supporting high sampling rate, low-bandwidth, high fidelity, and unified. We analyze the inefficiency of waveform-based compression and introduce the time and frequency compression method using the Mel-spectrogram, and cooperate with a Vocoder to recover the phase information of the original audio. Moreover, we propose a sub-band reconstruction technique to achieve high-quality compression across both low and high frequency bands. Subjective and objective experimental results demonstrate that UniSRCodec achieves state-of-the-art (SOTA) performance among cross-domain single-codebook codecs with only a token rate of 40, and its reconstruction quality is comparable to that of certain multi-codebook methods. Our demo page is available at https://wxzyd123.github.io/unisrcodec.
UltraEval-Audio: A Unified Framework for Comprehensive Evaluation of Audio Foundation Models
Jan 04, 2026The development of audio foundation models has accelerated rapidly since the emergence of GPT-4o. However, the lack of comprehensive evaluation has become a critical bottleneck for further progress in the field, particularly in audio generation. Current audio evaluation faces three major challenges: (1) audio evaluation lacks a unified framework, with datasets and code scattered across various sources, hindering fair and efficient cross-model comparison;(2) audio codecs, as a key component of audio foundation models, lack a widely accepted and holistic evaluation methodology; (3) existing speech benchmarks are heavily reliant on English, making it challenging to objectively assess models' performance on Chinese. To address the first issue, we introduce UltraEval-Audio, a unified evaluation framework for audio foundation models, specifically designed for both audio understanding and generation tasks. UltraEval-Audio features a modular architecture, supporting 10 languages and 14 core task categories, while seamlessly integrating 24 mainstream models and 36 authoritative benchmarks. To enhance research efficiency, the framework provides a one-command evaluation feature, accompanied by real-time public leaderboards. For the second challenge, UltraEval-Audio adopts a novel comprehensive evaluation scheme for audio codecs, evaluating performance across three key dimensions: semantic accuracy, timbre fidelity, and acoustic quality. To address the third issue, we propose two new Chinese benchmarks, SpeechCMMLU and SpeechHSK, designed to assess Chinese knowledge proficiency and language fluency. We wish that UltraEval-Audio will provide both academia and industry with a transparent, efficient, and fair platform for comparison of audio models. Our code, benchmarks, and leaderboards are available at https://github.com/OpenBMB/UltraEval-Audio.
A Scalable Pipeline for Enabling Non-Verbal Speech Generation and Understanding
Aug 07, 2025Human spoken communication involves not only lexical content but also non-verbal vocalizations (NVs) such as laughter, sighs, and coughs, which convey emotions, intentions, and social signals. However, most existing speech systems focus solely on verbal content and lack the ability to understand and generate such non-verbal cues, reducing the emotional intelligence and communicative richness of spoken interfaces. In this work, we introduce $\textbf{NonVerbalSpeech-38K}$, a large and diverse dataset for non-verbal speech generation and understanding, collected from real-world media and annotated using an automatic pipeline. The dataset contains 38,718 samples (about 131 hours) with 10 categories of non-verbal cues, such as laughter, sniff, and throat clearing. We further validate the dataset by fine-tuning state-of-the-art models, including F5-TTS and Qwen2-Audio, demonstrating its effectiveness in non-verbal speech generation and understanding tasks. Our contributions are threefold: (1) We propose a practical pipeline for building natural and diverse non-verbal speech datasets; (2) We release a large-scale dataset to advance research on non-verbal speech generation and understanding; (3) We validate the dataset's effectiveness by demonstrating improvements in both non-verbal speech synthesis and captioning, thereby facilitating richer human-computer interaction.
MiniCPM4: Ultra-Efficient LLMs on End Devices
Jun 09, 2025



This paper introduces MiniCPM4, a highly efficient large language model (LLM) designed explicitly for end-side devices. We achieve this efficiency through systematic innovation in four key dimensions: model architecture, training data, training algorithms, and inference systems. Specifically, in terms of model architecture, we propose InfLLM v2, a trainable sparse attention mechanism that accelerates both prefilling and decoding phases for long-context processing. Regarding training data, we propose UltraClean, an efficient and accurate pre-training data filtering and generation strategy, and UltraChat v2, a comprehensive supervised fine-tuning dataset. These datasets enable satisfactory model performance to be achieved using just 8 trillion training tokens. Regarding training algorithms, we propose ModelTunnel v2 for efficient pre-training strategy search, and improve existing post-training methods by introducing chunk-wise rollout for load-balanced reinforcement learning and data-efficient tenary LLM, BitCPM. Regarding inference systems, we propose CPM.cu that integrates sparse attention, model quantization, and speculative sampling to achieve efficient prefilling and decoding. To meet diverse on-device requirements, MiniCPM4 is available in two versions, with 0.5B and 8B parameters, respectively. Sufficient evaluation results show that MiniCPM4 outperforms open-source models of similar size across multiple benchmarks, highlighting both its efficiency and effectiveness. Notably, MiniCPM4-8B demonstrates significant speed improvements over Qwen3-8B when processing long sequences. Through further adaptation, MiniCPM4 successfully powers diverse applications, including trustworthy survey generation and tool use with model context protocol, clearly showcasing its broad usability.
Ultra-FineWeb: Efficient Data Filtering and Verification for High-Quality LLM Training Data
May 08, 2025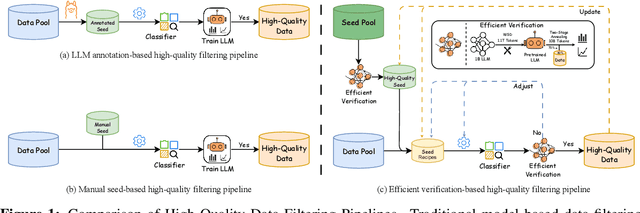



Data quality has become a key factor in enhancing model performance with the rapid development of large language models (LLMs). Model-driven data filtering has increasingly become a primary approach for acquiring high-quality data. However, it still faces two main challenges: (1) the lack of an efficient data verification strategy makes it difficult to provide timely feedback on data quality; and (2) the selection of seed data for training classifiers lacks clear criteria and relies heavily on human expertise, introducing a degree of subjectivity. To address the first challenge, we introduce an efficient verification strategy that enables rapid evaluation of the impact of data on LLM training with minimal computational cost. To tackle the second challenge, we build upon the assumption that high-quality seed data is beneficial for LLM training, and by integrating the proposed verification strategy, we optimize the selection of positive and negative samples and propose an efficient data filtering pipeline. This pipeline not only improves filtering efficiency, classifier quality, and robustness, but also significantly reduces experimental and inference costs. In addition, to efficiently filter high-quality data, we employ a lightweight classifier based on fastText, and successfully apply the filtering pipeline to two widely-used pre-training corpora, FineWeb and Chinese FineWeb datasets, resulting in the creation of the higher-quality Ultra-FineWeb dataset. Ultra-FineWeb contains approximately 1 trillion English tokens and 120 billion Chinese tokens. Empirical results demonstrate that the LLMs trained on Ultra-FineWeb exhibit significant performance improvements across multiple benchmark tasks, validating the effectiveness of our pipeline in enhancing both data quality and training efficiency.
Densing Law of LLMs
Dec 05, 2024



Large Language Models (LLMs) have emerged as a milestone in artificial intelligence, and their performance can improve as the model size increases. However, this scaling brings great challenges to training and inference efficiency, particularly for deploying LLMs in resource-constrained environments, and the scaling trend is becoming increasingly unsustainable. This paper introduces the concept of ``\textit{capacity density}'' as a new metric to evaluate the quality of the LLMs across different scales and describes the trend of LLMs in terms of both effectiveness and efficiency. To calculate the capacity density of a given target LLM, we first introduce a set of reference models and develop a scaling law to predict the downstream performance of these reference models based on their parameter sizes. We then define the \textit{effective parameter size} of the target LLM as the parameter size required by a reference model to achieve equivalent performance, and formalize the capacity density as the ratio of the effective parameter size to the actual parameter size of the target LLM. Capacity density provides a unified framework for assessing both model effectiveness and efficiency. Our further analysis of recent open-source base LLMs reveals an empirical law (the densing law)that the capacity density of LLMs grows exponentially over time. More specifically, using some widely used benchmarks for evaluation, the capacity density of LLMs doubles approximately every three months. The law provides new perspectives to guide future LLM development, emphasizing the importance of improving capacity density to achieve optimal results with minimal computational overhead.
MiniCPM-V: A GPT-4V Level MLLM on Your Phone
Aug 03, 2024

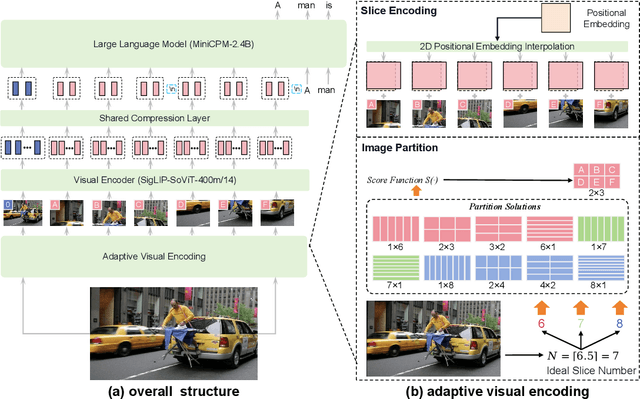
The recent surge of Multimodal Large Language Models (MLLMs) has fundamentally reshaped the landscape of AI research and industry, shedding light on a promising path toward the next AI milestone. However, significant challenges remain preventing MLLMs from being practical in real-world applications. The most notable challenge comes from the huge cost of running an MLLM with a massive number of parameters and extensive computation. As a result, most MLLMs need to be deployed on high-performing cloud servers, which greatly limits their application scopes such as mobile, offline, energy-sensitive, and privacy-protective scenarios. In this work, we present MiniCPM-V, a series of efficient MLLMs deployable on end-side devices. By integrating the latest MLLM techniques in architecture, pretraining and alignment, the latest MiniCPM-Llama3-V 2.5 has several notable features: (1) Strong performance, outperforming GPT-4V-1106, Gemini Pro and Claude 3 on OpenCompass, a comprehensive evaluation over 11 popular benchmarks, (2) strong OCR capability and 1.8M pixel high-resolution image perception at any aspect ratio, (3) trustworthy behavior with low hallucination rates, (4) multilingual support for 30+ languages, and (5) efficient deployment on mobile phones. More importantly, MiniCPM-V can be viewed as a representative example of a promising trend: The model sizes for achieving usable (e.g., GPT-4V) level performance are rapidly decreasing, along with the fast growth of end-side computation capacity. This jointly shows that GPT-4V level MLLMs deployed on end devices are becoming increasingly possible, unlocking a wider spectrum of real-world AI applications in the near future.
PyBench: Evaluating LLM Agent on various real-world coding tasks
Jul 23, 2024



The LLM Agent, equipped with a code interpreter, is capable of automatically solving real-world coding tasks, such as data analysis and image editing. However, existing benchmarks primarily focus on either simplistic tasks, such as completing a few lines of code, or on extremely complex and specific tasks at the repository level, neither of which are representative of various daily coding tasks. To address this gap, we introduce \textbf{PyBench}, a benchmark encompassing five main categories of real-world tasks, covering more than 10 types of files. Given a high-level user query and related files, the LLM Agent needs to reason and execute Python code via a code interpreter for a few turns before making a formal response to fulfill the user's requirements. Successfully addressing tasks in PyBench demands a robust understanding of various Python packages, superior reasoning capabilities, and the ability to incorporate feedback from executed code. Our evaluations indicate that current open-source LLMs are struggling with these tasks. Hence, we conduct analysis and experiments on four kinds of datasets proving that comprehensive abilities are needed for PyBench. Our fine-tuned 8B size model: \textbf{PyLlama3} achieves an exciting performance on PyBench which surpasses many 33B and 70B size models. Our Benchmark, Training Dataset, and Model are available at: \href{https://github.com/Mercury7353/PyBench}{https://github.com/Mercury7353/PyBench}
MiniCPM: Unveiling the Potential of Small Language Models with Scalable Training Strategies
Apr 09, 2024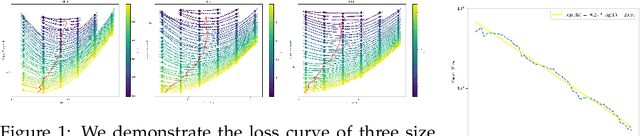


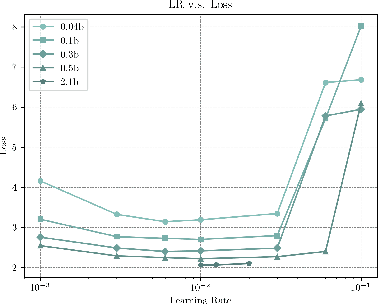
The burgeoning interest in developing Large Language Models (LLMs) with up to trillion parameters has been met with concerns regarding resource efficiency and practical expense, particularly given the immense cost of experimentation. This scenario underscores the importance of exploring the potential of Small Language Models (SLMs) as a resource-efficient alternative. In this context, we introduce MiniCPM, specifically the 1.2B and 2.4B non-embedding parameter variants, not only excel in their respective categories but also demonstrate capabilities on par with 7B-13B LLMs. While focusing on SLMs, our approach exhibits scalability in both model and data dimensions for future LLM research. Regarding model scaling, we employ extensive model wind tunnel experiments for stable and optimal scaling. For data scaling, we introduce a Warmup-Stable-Decay (WSD) learning rate scheduler (LRS), conducive to continuous training and domain adaptation. We present an in-depth analysis of the intriguing training dynamics that occurred in the WSD LRS. With WSD LRS, we are now able to efficiently study data-model scaling law without extensive retraining experiments on both axes of model and data, from which we derive the much higher compute optimal data-model ratio than Chinchilla Optimal. Additionally, we introduce MiniCPM family, including MiniCPM-DPO, MiniCPM-MoE and MiniCPM-128K, whose excellent performance further cementing MiniCPM's foundation in diverse SLM applications. MiniCPM models are available publicly at https://github.com/OpenBMB/MiniCPM .
D-Bot: Database Diagnosis System using Large Language Models
Dec 06, 2023



Database administrators (DBAs) play an important role in managing, maintaining and optimizing database systems. However, it is hard and tedious for DBAs to manage a large number of databases and give timely response (waiting for hours is intolerable in many online cases). In addition, existing empirical methods only support limited diagnosis scenarios, which are also labor-intensive to update the diagnosis rules for database version updates. Recently large language models (LLMs) have shown great potential in various fields. Thus, we propose D-Bot, an LLM-based database diagnosis system that can automatically acquire knowledge from diagnosis documents, and generate reasonable and well-founded diagnosis report (i.e., identifying the root causes and solutions) within acceptable time (e.g., under 10 minutes compared to hours by a DBA). The techniques in D-Bot include (i) offline knowledge extraction from documents, (ii) automatic prompt generation (e.g., knowledge matching, tool retrieval), (iii) root cause analysis using tree search algorithm, and (iv) collaborative mechanism for complex anomalies with multiple root causes. We verify D-Bot on real benchmarks (including 539 anomalies of six typical applications), and the results show that D-Bot can effectively analyze the root causes of unseen anomalies and significantly outperforms traditional methods and vanilla models like GPT-4.