 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInFi-Check: Interpretable and Fine-Grained Fact-Checking of LLMs
Jan 10, 2026Large language models (LLMs) often hallucinate, yet most existing fact-checking methods treat factuality evaluation as a binary classification problem, offering limited interpretability and failing to capture fine-grained error types. In this paper, we introduce InFi-Check, a framework for interpretable and fine-grained fact-checking of LLM outputs. Specifically, we first propose a controlled data synthesis pipeline that generates high-quality data featuring explicit evidence, fine-grained error type labels, justifications, and corrections. Based on this, we further construct large-scale training data and a manually verified benchmark InFi-Check-FG for fine-grained fact-checking of LLM outputs. Building on these high-quality training data, we further propose InFi-Checker, which can jointly provide supporting evidence, classify fine-grained error types, and produce justifications along with corrections. Experiments show that InFi-Checker achieves state-of-the-art performance on InFi-Check-FG and strong generalization across various downstream tasks, significantly improving the utility and trustworthiness of factuality evaluation.
FaithLens: Detecting and Explaining Faithfulness Hallucination
Dec 23, 2025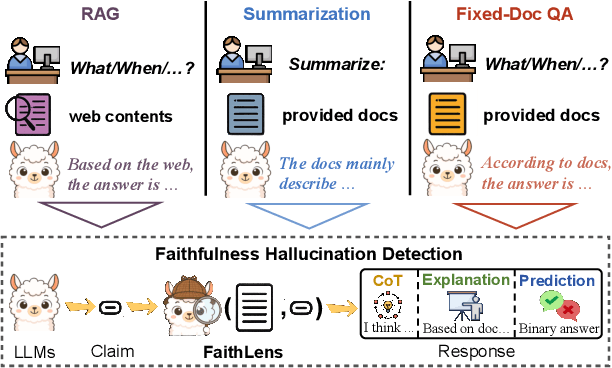
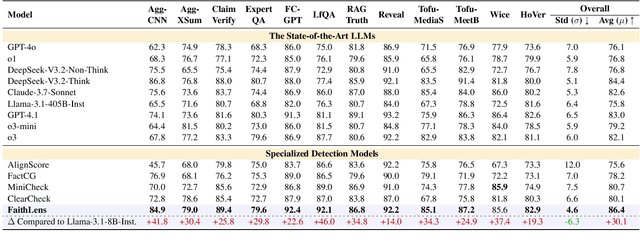
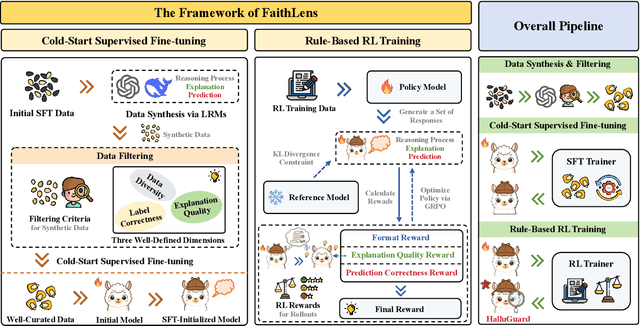
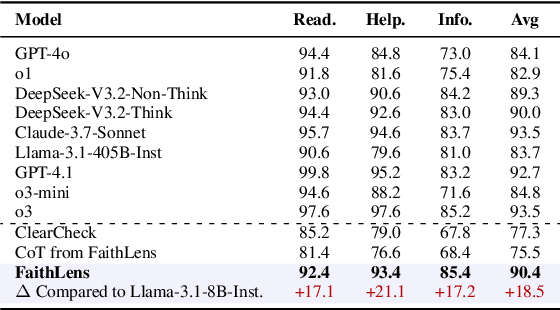
Recognizing whether outputs from large language models (LLMs) contain faithfulness hallucination is crucial for real-world applications, e.g., retrieval-augmented generation and summarization. In this paper, we introduce FaithLens, a cost-efficient and effective faithfulness hallucination detection model that can jointly provide binary predictions and corresponding explanations to improve trustworthiness. To achieve this, we first synthesize training data with explanations via advanced LLMs and apply a well-defined data filtering strategy to ensure label correctness, explanation quality, and data diversity. Subsequently, we fine-tune the model on these well-curated training data as a cold start and further optimize it with rule-based reinforcement learning, using rewards for both prediction correctness and explanation quality. Results on 12 diverse tasks show that the 8B-parameter FaithLens outperforms advanced models such as GPT-4.1 and o3. Also, FaithLens can produce high-quality explanations, delivering a distinctive balance of trustworthiness, efficiency, and effectiveness.
From Context to EDUs: Faithful and Structured Context Compression via Elementary Discourse Unit Decomposition
Dec 18, 2025Managing extensive context remains a critical bottleneck for Large Language Models (LLMs), particularly in applications like long-document question answering and autonomous agents where lengthy inputs incur high computational costs and introduce noise. Existing compression techniques often disrupt local coherence through discrete token removal or rely on implicit latent encoding that suffers from positional bias and incompatibility with closed-source APIs. To address these limitations, we introduce the EDU-based Context Compressor, a novel explicit compression framework designed to preserve both global structure and fine-grained details. Our approach reformulates context compression as a structure-then-select process. First, our LingoEDU transforms linear text into a structural relation tree of Elementary Discourse Units (EDUs) which are anchored strictly to source indices to eliminate hallucination. Second, a lightweight ranking module selects query-relevant sub-trees for linearization. To rigorously evaluate structural understanding, we release StructBench, a manually annotated dataset of 248 diverse documents. Empirical results demonstrate that our method achieves state-of-the-art structural prediction accuracy and significantly outperforms frontier LLMs while reducing costs. Furthermore, our structure-aware compression substantially enhances performance across downstream tasks ranging from long-context tasks to complex Deep Search scenarios.
WGRAMMAR: Leverage Prior Knowledge to Accelerate Structured Decoding
Jul 22, 2025Structured decoding enables large language models (LLMs) to generate outputs in formats required by downstream systems, such as HTML or JSON. However, existing methods suffer from efficiency bottlenecks due to grammar compilation, state tracking, and mask creation. We observe that many real-world tasks embed strong prior knowledge about output structure. Leveraging this, we propose a decomposition of constraints into static and dynamic components -- precompiling static structures offline and instantiating dynamic arguments at runtime using grammar snippets. Instead of relying on pushdown automata, we employ a compositional set of operators to model regular formats, achieving lower transition latency. We introduce wgrammar, a lightweight decoding engine that integrates domain-aware simplification, constraint decomposition, and mask caching, achieving up to 250x speedup over existing systems. wgrammar's source code is publicly available at https://github.com/wrran/wgrammar.
Teaching Large Language Models to Maintain Contextual Faithfulness via Synthetic Tasks and Reinforcement Learning
May 22, 2025Teaching large language models (LLMs) to be faithful in the provided context is crucial for building reliable information-seeking systems. Therefore, we propose a systematic framework, CANOE, to improve the faithfulness of LLMs in both short-form and long-form generation tasks without human annotations. Specifically, we first synthesize short-form question-answering (QA) data with four diverse tasks to construct high-quality and easily verifiable training data without human annotation. Also, we propose Dual-GRPO, a rule-based reinforcement learning method that includes three tailored rule-based rewards derived from synthesized short-form QA data, while simultaneously optimizing both short-form and long-form response generation. Notably, Dual-GRPO eliminates the need to manually label preference data to train reward models and avoids over-optimizing short-form generation when relying only on the synthesized short-form QA data. Experimental results show that CANOE greatly improves the faithfulness of LLMs across 11 different downstream tasks, even outperforming the most advanced LLMs, e.g., GPT-4o and OpenAI o1.
Aligning Large Language Models to Follow Instructions and Hallucinate Less via Effective Data Filtering
Feb 11, 2025Training LLMs on data that contains unfamiliar knowledge during the instruction tuning stage can make LLMs overconfident and encourage hallucinations. To address this challenge, we introduce a novel framework, NOVA, which identifies high-quality data that aligns well with the LLM's learned knowledge to reduce hallucinations. NOVA includes Internal Consistency Probing (ICP) and Semantic Equivalence Identification (SEI) to measure how familiar the LLM is with instruction data. Specifically, ICP evaluates the LLM's understanding of the given instruction by calculating the tailored consistency among multiple self-generated responses. SEI further assesses the familiarity of the LLM with the target response by comparing it to the generated responses, using the proposed semantic clustering and well-designed voting strategy. Finally, we introduce an expert-aligned reward model, considering characteristics beyond just familiarity to enhance data quality. By considering data quality and avoiding unfamiliar data, we can utilize the selected data to effectively align LLMs to follow instructions and hallucinate less. Extensive experiments and analysis show that NOVA significantly reduces hallucinations and allows LLMs to maintain a strong ability to follow instructions.
Selecting Influential Samples for Long Context Alignment via Homologous Models' Guidance and Contextual Awareness Measurement
Oct 21, 2024The expansion of large language models to effectively handle instructions with extremely long contexts has yet to be fully investigated. The primary obstacle lies in constructing a high-quality long instruction-following dataset devised for long context alignment. Existing studies have attempted to scale up the available data volume by synthesizing long instruction-following samples. However, indiscriminately increasing the quantity of data without a well-defined strategy for ensuring data quality may introduce low-quality samples and restrict the final performance. To bridge this gap, we aim to address the unique challenge of long-context alignment, i.e., modeling the long-range dependencies for handling instructions and lengthy input contexts. We propose GATEAU, a novel framework designed to identify the influential and high-quality samples enriched with long-range dependency relations by utilizing crafted Homologous Models' Guidance (HMG) and Contextual Awareness Measurement (CAM). Specifically, HMG attempts to measure the difficulty of generating corresponding responses due to the long-range dependencies, using the perplexity scores of the response from two homologous models with different context windows. Also, the role of CAM is to measure the difficulty of understanding the long input contexts due to long-range dependencies by evaluating whether the model's attention is focused on important segments. Built upon both proposed methods, we select the most challenging samples as the influential data to effectively frame the long-range dependencies, thereby achieving better performance of LLMs. Comprehensive experiments indicate that GATEAU effectively identifies samples enriched with long-range dependency relations and the model trained on these selected samples exhibits better instruction-following and long-context understanding capabilities.
WebCPM: Interactive Web Search for Chinese Long-form Question Answering
May 23, 2023

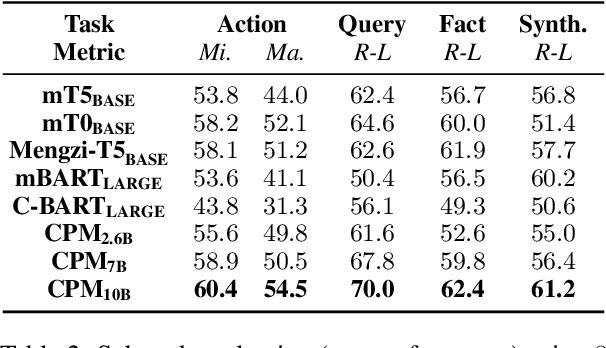

Long-form question answering (LFQA) aims at answering complex, open-ended questions with detailed, paragraph-length responses. The de facto paradigm of LFQA necessitates two procedures: information retrieval, which searches for relevant supporting facts, and information synthesis, which integrates these facts into a coherent answer. In this paper, we introduce WebCPM, the first Chinese LFQA dataset. One unique feature of WebCPM is that its information retrieval is based on interactive web search, which engages with a search engine in real time. Following WebGPT, we develop a web search interface. We recruit annotators to search for relevant information using our interface and then answer questions. Meanwhile, the web search behaviors of our annotators would be recorded. In total, we collect 5,500 high-quality question-answer pairs, together with 14,315 supporting facts and 121,330 web search actions. We fine-tune pre-trained language models to imitate human behaviors for web search and to generate answers based on the collected facts. Our LFQA pipeline, built on these fine-tuned models, generates answers that are no worse than human-written ones in 32.5% and 47.5% of the cases on our dataset and DuReader, respectively.
Why Should Adversarial Perturbations be Imperceptible? Rethink the Research Paradigm in Adversarial NLP
Oct 19, 2022


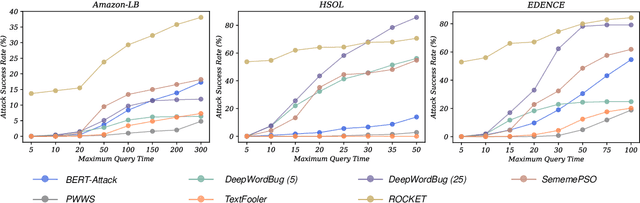
Textual adversarial samples play important roles in multiple subfields of NLP research, including security, evaluation, explainability, and data augmentation. However, most work mixes all these roles, obscuring the problem definitions and research goals of the security role that aims to reveal the practical concerns of NLP models. In this paper, we rethink the research paradigm of textual adversarial samples in security scenarios. We discuss the deficiencies in previous work and propose our suggestions that the research on the Security-oriented adversarial NLP (SoadNLP) should: (1) evaluate their methods on security tasks to demonstrate the real-world concerns; (2) consider real-world attackers' goals, instead of developing impractical methods. To this end, we first collect, process, and release a security datasets collection Advbench. Then, we reformalize the task and adjust the emphasis on different goals in SoadNLP. Next, we propose a simple method based on heuristic rules that can easily fulfill the actual adversarial goals to simulate real-world attack methods. We conduct experiments on both the attack and the defense sides on Advbench. Experimental results show that our method has higher practical value, indicating that the research paradigm in SoadNLP may start from our new benchmark. All the code and data of Advbench can be obtained at \url{https://github.com/thunlp/Advbench}.
Sememe Prediction for BabelNet Synsets using Multilingual and Multimodal Information
Mar 14, 2022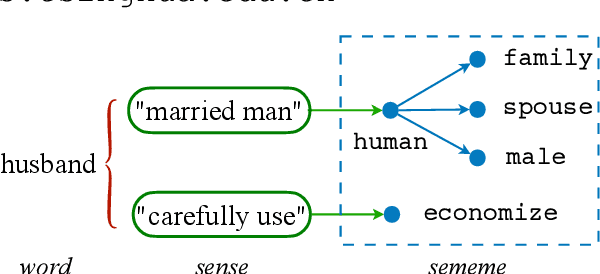
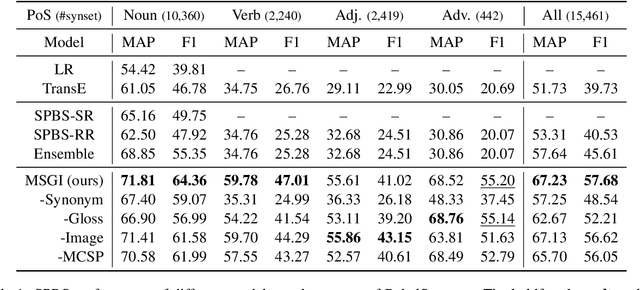


In linguistics, a sememe is defined as the minimum semantic unit of languages. Sememe knowledge bases (KBs), which are built by manually annotating words with sememes, have been successfully applied to various NLP tasks. However, existing sememe KBs only cover a few languages, which hinders the wide utilization of sememes. To address this issue, the task of sememe prediction for BabelNet synsets (SPBS) is presented, aiming to build a multilingual sememe KB based on BabelNet, a multilingual encyclopedia dictionary. By automatically predicting sememes for a BabelNet synset, the words in many languages in the synset would obtain sememe annotations simultaneously. However, previous SPBS methods have not taken full advantage of the abundant information in BabelNet. In this paper, we utilize the multilingual synonyms, multilingual glosses and images in BabelNet for SPBS. We design a multimodal information fusion model to encode and combine this information for sememe prediction. Experimental results show the substantial outperformance of our model over previous methods (about 10 MAP and F1 scores). All the code and data of this paper can be obtained at https://github.com/thunlp/MSGI.