 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow Do Multimodal Large Language Models Handle Complex Multimodal Reasoning? Placing Them in An Extensible Escape Game
Mar 13, 2025The rapid advancing of Multimodal Large Language Models (MLLMs) has spurred interest in complex multimodal reasoning tasks in the real-world and virtual environment, which require coordinating multiple abilities, including visual perception, visual reasoning, spatial awareness, and target deduction. However, existing evaluations primarily assess the final task completion, often degrading assessments to isolated abilities such as visual grounding and visual question answering. Less attention is given to comprehensively and quantitatively analyzing reasoning process in multimodal environments, which is crucial for understanding model behaviors and underlying reasoning mechanisms beyond merely task success. To address this, we introduce MM-Escape, an extensible benchmark for investigating multimodal reasoning, inspired by real-world escape games. MM-Escape emphasizes intermediate model behaviors alongside final task completion. To achieve this, we develop EscapeCraft, a customizable and open environment that enables models to engage in free-form exploration for assessing multimodal reasoning. Extensive experiments show that MLLMs, regardless of scale, can successfully complete the simplest room escape tasks, with some exhibiting human-like exploration strategies. Yet, performance dramatically drops as task difficulty increases. Moreover, we observe that performance bottlenecks vary across models, revealing distinct failure modes and limitations in their multimodal reasoning abilities, such as repetitive trajectories without adaptive exploration, getting stuck in corners due to poor visual spatial awareness, and ineffective use of acquired props, such as the key. We hope our work sheds light on new challenges in multimodal reasoning, and uncovers potential improvements in MLLMs capabilities.
EmbodiedEval: Evaluate Multimodal LLMs as Embodied Agents
Jan 21, 2025



Multimodal Large Language Models (MLLMs) have shown significant advancements, providing a promising future for embodied agents. Existing benchmarks for evaluating MLLMs primarily utilize static images or videos, limiting assessments to non-interactive scenarios. Meanwhile, existing embodied AI benchmarks are task-specific and not diverse enough, which do not adequately evaluate the embodied capabilities of MLLMs. To address this, we propose EmbodiedEval, a comprehensive and interactive evaluation benchmark for MLLMs with embodied tasks. EmbodiedEval features 328 distinct tasks within 125 varied 3D scenes, each of which is rigorously selected and annotated. It covers a broad spectrum of existing embodied AI tasks with significantly enhanced diversity, all within a unified simulation and evaluation framework tailored for MLLMs. The tasks are organized into five categories: navigation, object interaction, social interaction, attribute question answering, and spatial question answering to assess different capabilities of the agents. We evaluated the state-of-the-art MLLMs on EmbodiedEval and found that they have a significant shortfall compared to human level on embodied tasks. Our analysis demonstrates the limitations of existing MLLMs in embodied capabilities, providing insights for their future development. We open-source all evaluation data and simulation framework at https://github.com/thunlp/EmbodiedEval.
LEGENT: Open Platform for Embodied Agents
Apr 28, 2024
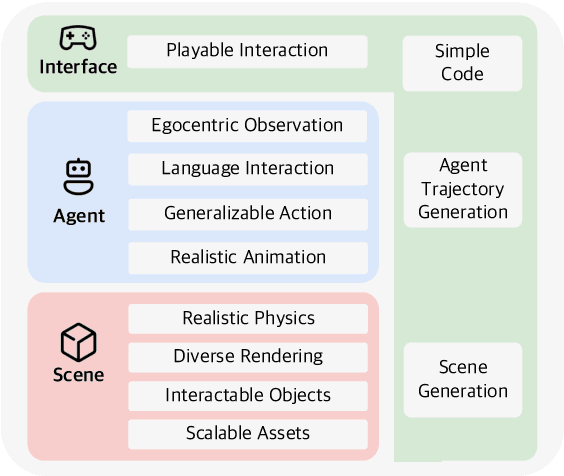


Despite advancements in Large Language Models (LLMs) and Large Multimodal Models (LMMs), their integration into language-grounded, human-like embodied agents remains incomplete, hindering complex real-life task performance in physical environments. Existing integrations often feature limited open sourcing, challenging collective progress in this field. We introduce LEGENT, an open, scalable platform for developing embodied agents using LLMs and LMMs. LEGENT offers a dual approach: a rich, interactive 3D environment with communicable and actionable agents, paired with a user-friendly interface, and a sophisticated data generation pipeline utilizing advanced algorithms to exploit supervision from simulated worlds at scale. In our experiments, an embryonic vision-language-action model trained on LEGENT-generated data surpasses GPT-4V in embodied tasks, showcasing promising generalization capabilities.
QuoteR: A Benchmark of Quote Recommendation for Writing
Mar 14, 2022
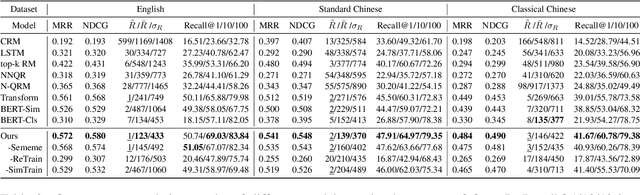
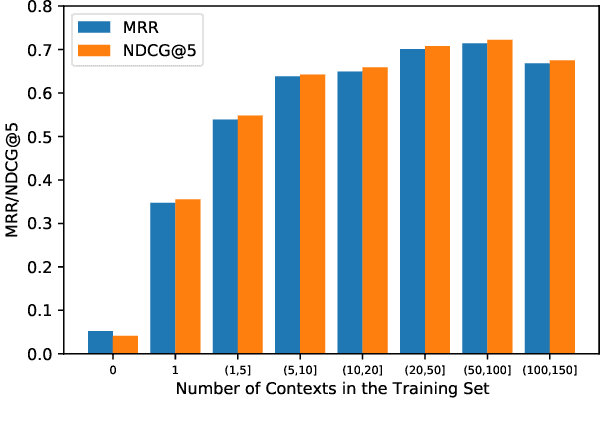

It is very common to use quotations (quotes) to make our writings more elegant or convincing. To help people find appropriate quotes efficiently, the task of quote recommendation is presented, aiming to recommend quotes that fit the current context of writing. There have been various quote recommendation approaches, but they are evaluated on different unpublished datasets. To facilitate the research on this task, we build a large and fully open quote recommendation dataset called QuoteR, which comprises three parts including English, standard Chinese and classical Chinese. Any part of it is larger than previous unpublished counterparts. We conduct an extensive evaluation of existing quote recommendation methods on QuoteR. Furthermore, we propose a new quote recommendation model that significantly outperforms previous methods on all three parts of QuoteR. All the code and data of this paper are available at https://github.com/thunlp/QuoteR.