 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTool Learning with Foundation Models
Apr 17, 2023Humans possess an extraordinary ability to create and utilize tools, allowing them to overcome physical limitations and explore new frontiers. With the advent of foundation models, AI systems have the potential to be equally adept in tool use as humans. This paradigm, i.e., tool learning with foundation models, combines the strengths of specialized tools and foundation models to achieve enhanced accuracy, efficiency, and automation in problem-solving. Despite its immense potential, there is still a lack of a comprehensive understanding of key challenges, opportunities, and future endeavors in this field. To this end, we present a systematic investigation of tool learning in this paper. We first introduce the background of tool learning, including its cognitive origins, the paradigm shift of foundation models, and the complementary roles of tools and models. Then we recapitulate existing tool learning research into tool-augmented and tool-oriented learning. We formulate a general tool learning framework: starting from understanding the user instruction, models should learn to decompose a complex task into several subtasks, dynamically adjust their plan through reasoning, and effectively conquer each sub-task by selecting appropriate tools. We also discuss how to train models for improved tool-use capabilities and facilitate the generalization in tool learning. Considering the lack of a systematic tool learning evaluation in prior works, we experiment with 17 representative tools and show the potential of current foundation models in skillfully utilizing tools. Finally, we discuss several open problems that require further investigation for tool learning. Overall, we hope this paper could inspire future research in integrating tools with foundation models.
Exploring Mode Connectivity for Pre-trained Language Models
Oct 25, 2022
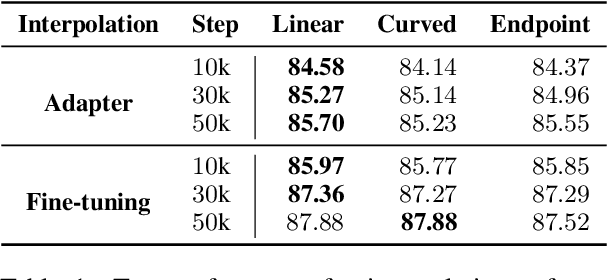

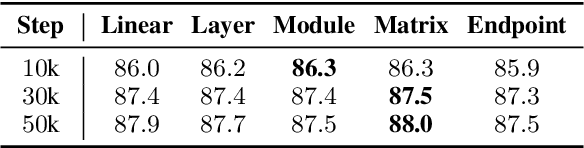
Recent years have witnessed the prevalent application of pre-trained language models (PLMs) in NLP. From the perspective of parameter space, PLMs provide generic initialization, starting from which high-performance minima could be found. Although plenty of works have studied how to effectively and efficiently adapt PLMs to high-performance minima, little is known about the connection of various minima reached under different adaptation configurations. In this paper, we investigate the geometric connections of different minima through the lens of mode connectivity, which measures whether two minima can be connected with a low-loss path. We conduct empirical analyses to investigate three questions: (1) how could hyperparameters, specific tuning methods, and training data affect PLM's mode connectivity? (2) How does mode connectivity change during pre-training? (3) How does the PLM's task knowledge change along the path connecting two minima? In general, exploring the mode connectivity of PLMs conduces to understanding the geometric connection of different minima, which may help us fathom the inner workings of PLM downstream adaptation.
Different Tunes Played with Equal Skill: Exploring a Unified Optimization Subspace for Delta Tuning
Oct 24, 2022



Delta tuning (DET, also known as parameter-efficient tuning) is deemed as the new paradigm for using pre-trained language models (PLMs). Up to now, various DETs with distinct design elements have been proposed, achieving performance on par with fine-tuning. However, the mechanisms behind the above success are still under-explored, especially the connections among various DETs. To fathom the mystery, we hypothesize that the adaptations of different DETs could all be reparameterized as low-dimensional optimizations in a unified optimization subspace, which could be found by jointly decomposing independent solutions of different DETs. Then we explore the connections among different DETs by conducting optimization within the subspace. In experiments, we find that, for a certain DET, conducting optimization simply in the subspace could achieve comparable performance to its original space, and the found solution in the subspace could be transferred to another DET and achieve non-trivial performance. We also visualize the performance landscape of the subspace and find that there exists a substantial region where different DETs all perform well. Finally, we extend our analysis and show the strong connections between fine-tuning and DETs.
Deep Deconfounded Content-based Tag Recommendation for UGC with Causal Intervention
May 28, 2022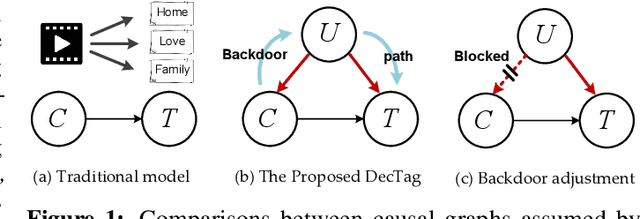
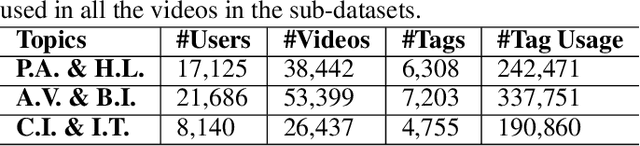
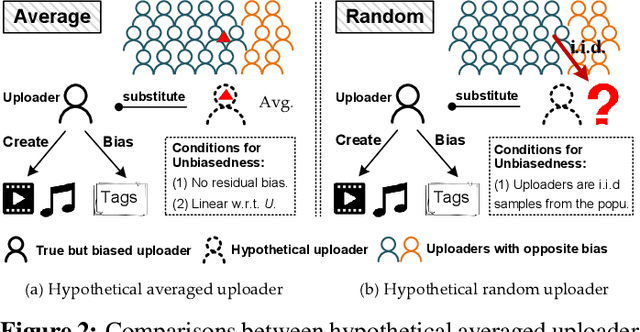
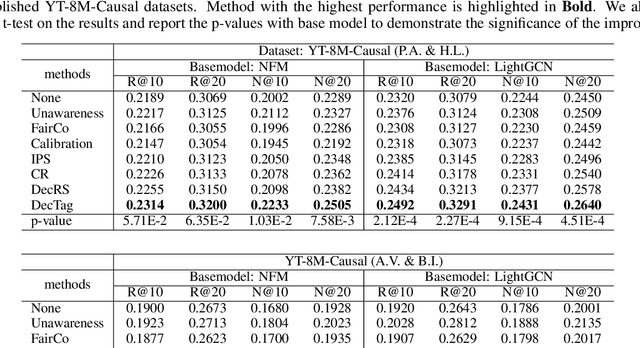
Traditional content-based tag recommender systems directly learn the association between user-generated content (UGC) and tags based on collected UGC-tag pairs. However, since a UGC uploader simultaneously creates the UGC and selects the corresponding tags, her personal preference inevitably biases the tag selections, which prevents these recommenders from learning the causal influence of UGCs' content features on tags. In this paper, we propose a deep deconfounded content-based tag recommender system, namely, DecTag, to address the above issues. We first establish a causal graph to represent the relations among uploader, UGC, and tag, where the uploaders are identified as confounders that spuriously correlate UGC and tag selections. Specifically, to eliminate the confounding bias, causal intervention is conducted on the UGC node in the graph via backdoor adjustment, where uploaders' influence on tags leaked through backdoor paths can be eliminated for causal effect estimation. Observing that adjusting the causal graph with do-calculus requires integrating the entire uploader space, which is infeasible, we design a novel Monte Carlo (MC)-based estimator with bootstrap, which can achieve asymptotic unbiasedness provided that uploaders for the collected UGCs are i.i.d. samples from the population. In addition, the MC estimator has the intuition of substituting the biased uploaders with a hypothetical random uploader from the population in the training phase, where deconfounding can be achieved in an interpretable manner. Finally, we establish a YT-8M-Causal dataset based on the widely used YouTube-8M dataset with causal intervention and propose an evaluation strategy accordingly to unbiasedly evaluate causal tag recommenders. Extensive experiments show that DecTag is more robust to confounding bias than state-of-the-art causal recommenders.
Multi-Auxiliary Augmented Collaborative Variational Auto-encoder for Tag Recommendation
Apr 20, 2022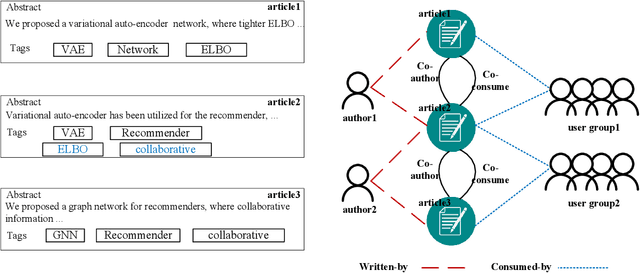
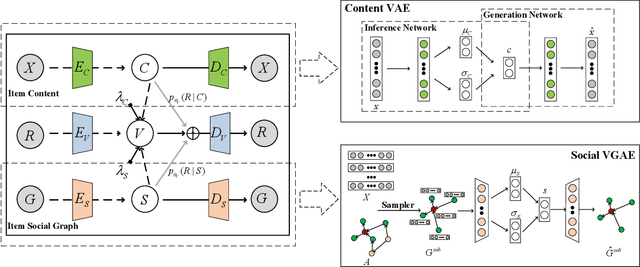
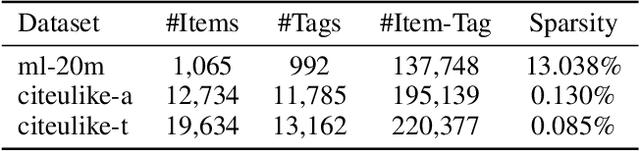
Recommending appropriate tags to items can facilitate content organization, retrieval, consumption and other applications, where hybrid tag recommender systems have been utilized to integrate collaborative information and content information for better recommendations. In this paper, we propose a multi-auxiliary augmented collaborative variational auto-encoder (MA-CVAE) for tag recommendation, which couples item collaborative information and item multi-auxiliary information, i.e., content and social graph, by defining a generative process. Specifically, the model learns deep latent embeddings from different item auxiliary information using variational auto-encoders (VAE), which could form a generative distribution over each auxiliary information by introducing a latent variable parameterized by deep neural network. Moreover, to recommend tags for new items, item multi-auxiliary latent embeddings are utilized as a surrogate through the item decoder for predicting recommendation probabilities of each tag, where reconstruction losses are added in the training phase to constrict the generation for feedback predictions via different auxiliary embeddings. In addition, an inductive variational graph auto-encoder is designed where new item nodes could be inferred in the test phase, such that item social embeddings could be exploited for new items. Extensive experiments on MovieLens and citeulike datasets demonstrate the effectiveness of our method.
Delta Tuning: A Comprehensive Study of Parameter Efficient Methods for Pre-trained Language Models
Mar 15, 2022

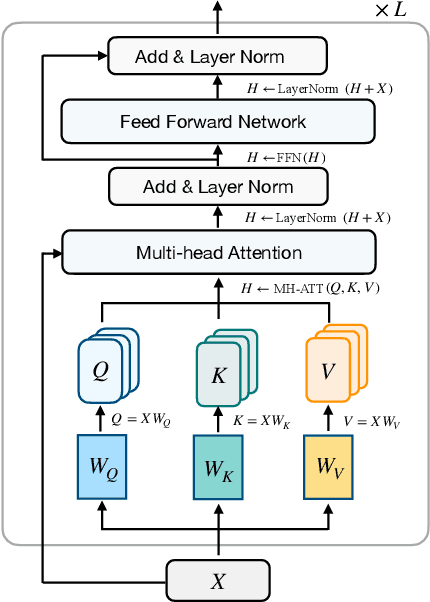
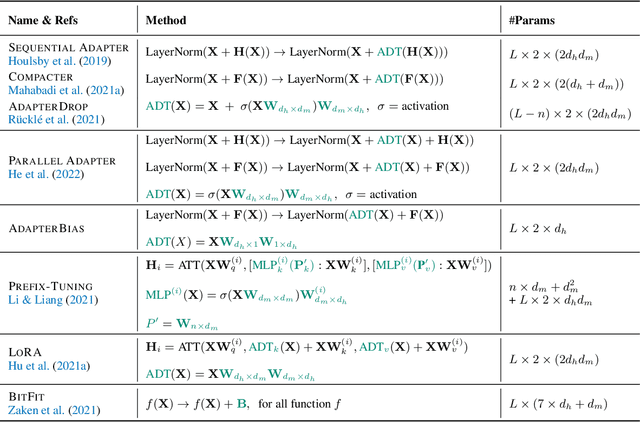
Despite the success, the process of fine-tuning large-scale PLMs brings prohibitive adaptation costs. In fact, fine-tuning all the parameters of a colossal model and retaining separate instances for different tasks are practically infeasible. This necessitates a new branch of research focusing on the parameter-efficient adaptation of PLMs, dubbed as delta tuning in this paper. In contrast with the standard fine-tuning, delta tuning only fine-tunes a small portion of the model parameters while keeping the rest untouched, largely reducing both the computation and storage costs. Recent studies have demonstrated that a series of delta tuning methods with distinct tuned parameter selection could achieve performance on a par with full-parameter fine-tuning, suggesting a new promising way of stimulating large-scale PLMs. In this paper, we first formally describe the problem of delta tuning and then comprehensively review recent delta tuning approaches. We also propose a unified categorization criterion that divide existing delta tuning methods into three groups: addition-based, specification-based, and reparameterization-based methods. Though initially proposed as an efficient method to steer large models, we believe that some of the fascinating evidence discovered along with delta tuning could help further reveal the mechanisms of PLMs and even deep neural networks. To this end, we discuss the theoretical principles underlying the effectiveness of delta tuning and propose frameworks to interpret delta tuning from the perspective of optimization and optimal control, respectively. Furthermore, we provide a holistic empirical study of representative methods, where results on over 100 NLP tasks demonstrate a comprehensive performance comparison of different approaches. The experimental results also cover the analysis of combinatorial, scaling and transferable properties of delta tuning.
QuoteR: A Benchmark of Quote Recommendation for Writing
Mar 14, 2022
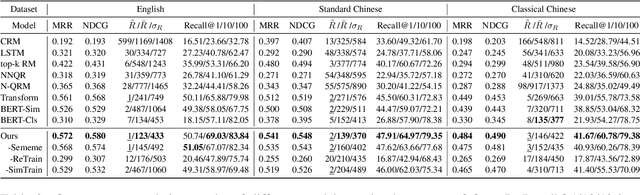
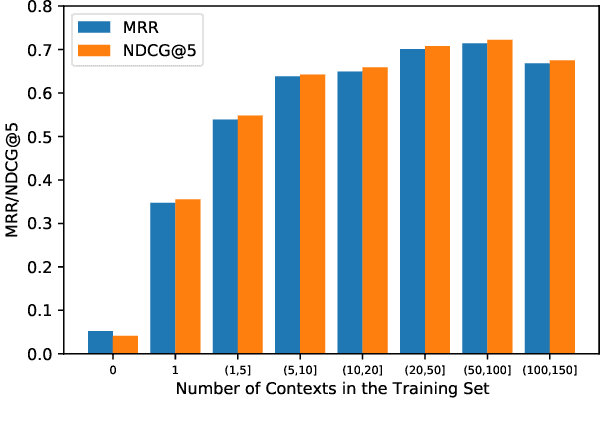

It is very common to use quotations (quotes) to make our writings more elegant or convincing. To help people find appropriate quotes efficiently, the task of quote recommendation is presented, aiming to recommend quotes that fit the current context of writing. There have been various quote recommendation approaches, but they are evaluated on different unpublished datasets. To facilitate the research on this task, we build a large and fully open quote recommendation dataset called QuoteR, which comprises three parts including English, standard Chinese and classical Chinese. Any part of it is larger than previous unpublished counterparts. We conduct an extensive evaluation of existing quote recommendation methods on QuoteR. Furthermore, we propose a new quote recommendation model that significantly outperforms previous methods on all three parts of QuoteR. All the code and data of this paper are available at https://github.com/thunlp/QuoteR.
Deep Causal Reasoning for Recommendations
Jan 06, 2022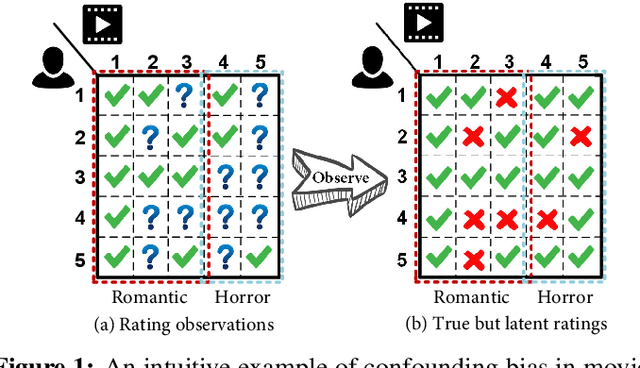
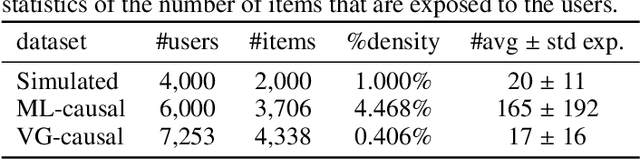
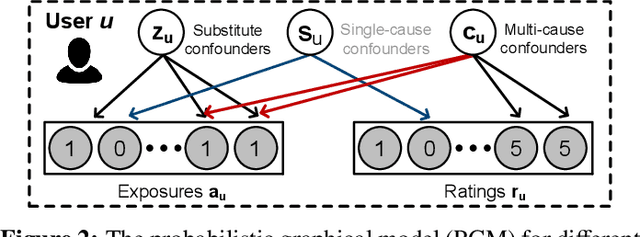
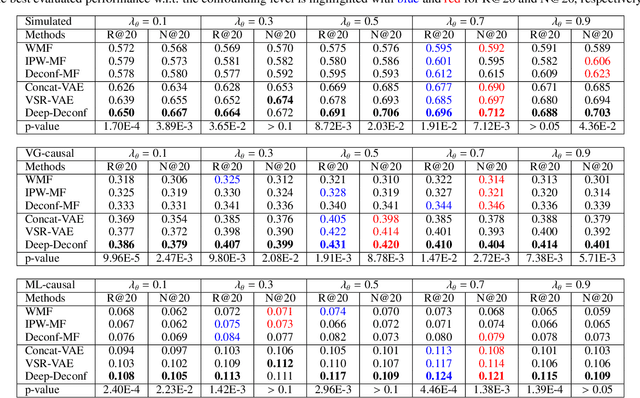
Traditional recommender systems aim to estimate a user's rating to an item based on observed ratings from the population. As with all observational studies, hidden confounders, which are factors that affect both item exposures and user ratings, lead to a systematic bias in the estimation. Consequently, a new trend in recommender system research is to negate the influence of confounders from a causal perspective. Observing that confounders in recommendations are usually shared among items and are therefore multi-cause confounders, we model the recommendation as a multi-cause multi-outcome (MCMO) inference problem. Specifically, to remedy confounding bias, we estimate user-specific latent variables that render the item exposures independent Bernoulli trials. The generative distribution is parameterized by a DNN with factorized logistic likelihood and the intractable posteriors are estimated by variational inference. Controlling these factors as substitute confounders, under mild assumptions, can eliminate the bias incurred by multi-cause confounders. Furthermore, we show that MCMO modeling may lead to high variance due to scarce observations associated with the high-dimensional causal space. Fortunately, we theoretically demonstrate that introducing user features as pre-treatment variables can substantially improve sample efficiency and alleviate overfitting. Empirical studies on simulated and real-world datasets show that the proposed deep causal recommender shows more robustness to unobserved confounders than state-of-the-art causal recommenders. Codes and datasets are released at https://github.com/yaochenzhu/deep-deconf.
Cross-modal Variational Auto-encoder for Content-based Micro-video Background Music Recommendation
Jul 15, 2021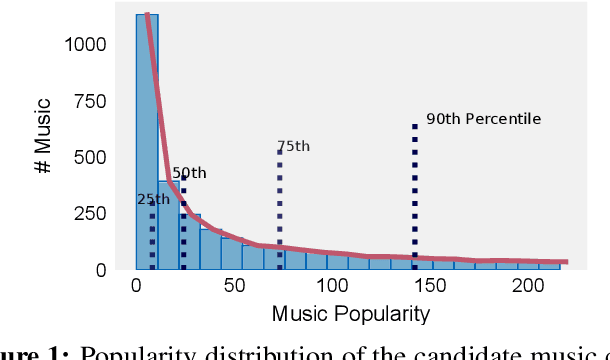
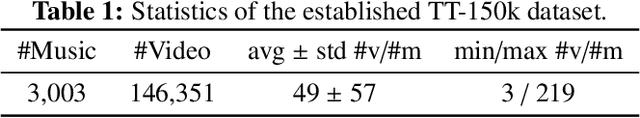

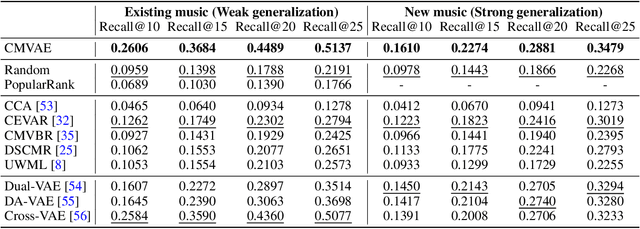
In this paper, we propose a cross-modal variational auto-encoder (CMVAE) for content-based micro-video background music recommendation. CMVAE is a hierarchical Bayesian generative model that matches relevant background music to a micro-video by projecting these two multimodal inputs into a shared low-dimensional latent space, where the alignment of two corresponding embeddings of a matched video-music pair is achieved by cross-generation. Moreover, the multimodal information is fused by the product-of-experts (PoE) principle, where the semantic information in visual and textual modalities of the micro-video are weighted according to their variance estimations such that the modality with a lower noise level is given more weights. Therefore, the micro-video latent variables contain less irrelevant information that results in a more robust model generalization. Furthermore, we establish a large-scale content-based micro-video background music recommendation dataset, TT-150k, composed of approximately 3,000 different background music clips associated to 150,000 micro-videos from different users. Extensive experiments on the established TT-150k dataset demonstrate the effectiveness of the proposed method. A qualitative assessment of CMVAE by visualizing some recommendation results is also included.
Knowledge Inheritance for Pre-trained Language Models
May 28, 2021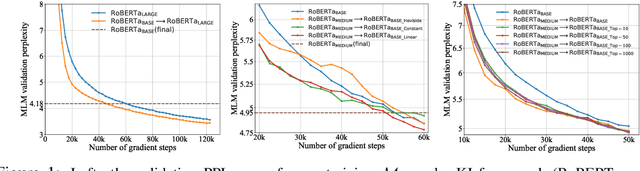
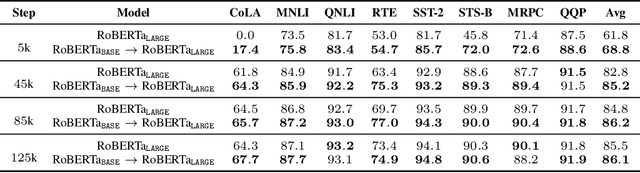
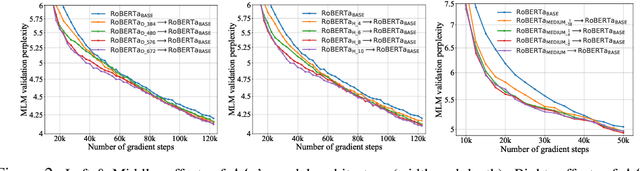
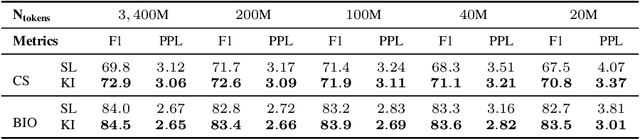
Recent explorations of large-scale pre-trained language models (PLMs) such as GPT-3 have revealed the power of PLMs with huge amounts of parameters, setting off a wave of training ever-larger PLMs. However, training a large-scale PLM requires tremendous amounts of computational resources, which is time-consuming and expensive. In addition, existing large-scale PLMs are mainly trained from scratch individually, ignoring the availability of many existing well-trained PLMs. To this end, we explore the question that how can previously trained PLMs benefit training larger PLMs in future. Specifically, we introduce a novel pre-training framework named "knowledge inheritance" (KI), which combines both self-learning and teacher-guided learning to efficiently train larger PLMs. Sufficient experimental results demonstrate the feasibility of our KI framework. We also conduct empirical analyses to explore the effects of teacher PLMs' pre-training settings, including model architecture, pre-training data, etc. Finally, we show that KI can well support lifelong learning and knowledge transfer.