 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKnowledge Inheritance for Pre-trained Language Models
Paper and Code
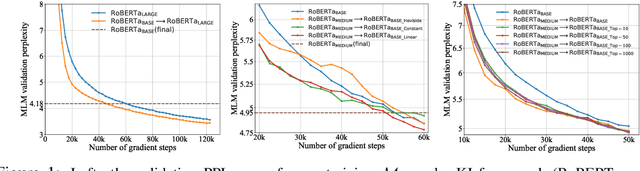
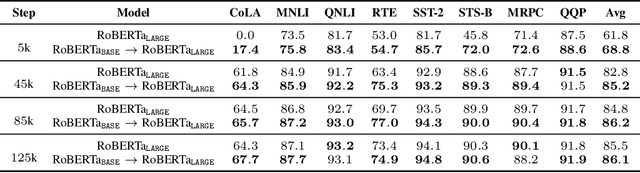
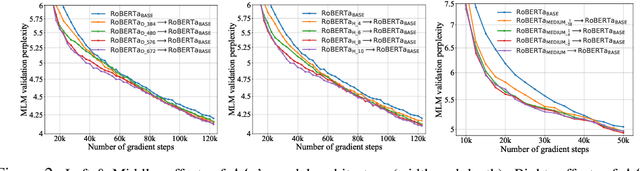
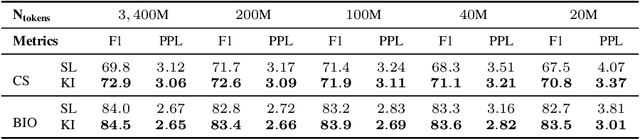
Recent explorations of large-scale pre-trained language models (PLMs) such as GPT-3 have revealed the power of PLMs with huge amounts of parameters, setting off a wave of training ever-larger PLMs. However, training a large-scale PLM requires tremendous amounts of computational resources, which is time-consuming and expensive. In addition, existing large-scale PLMs are mainly trained from scratch individually, ignoring the availability of many existing well-trained PLMs. To this end, we explore the question that how can previously trained PLMs benefit training larger PLMs in future. Specifically, we introduce a novel pre-training framework named "knowledge inheritance" (KI), which combines both self-learning and teacher-guided learning to efficiently train larger PLMs. Sufficient experimental results demonstrate the feasibility of our KI framework. We also conduct empirical analyses to explore the effects of teacher PLMs' pre-training settings, including model architecture, pre-training data, etc. Finally, we show that KI can well support lifelong learning and knowledge transfer.