 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraph-Anchored Knowledge Indexing for Retrieval-Augmented Generation
Jan 23, 2026Retrieval-Augmented Generation (RAG) has emerged as a dominant paradigm for mitigating hallucinations in Large Language Models (LLMs) by incorporating external knowledge. Nevertheless, effectively integrating and interpreting key evidence scattered across noisy documents remains a critical challenge for existing RAG systems. In this paper, we propose GraphAnchor, a novel Graph-Anchored Knowledge Indexing approach that reconceptualizes graph structures from static knowledge representations into active, evolving knowledge indices. GraphAnchor incrementally updates a graph during iterative retrieval to anchor salient entities and relations, yielding a structured index that guides the LLM in evaluating knowledge sufficiency and formulating subsequent subqueries. The final answer is generated by jointly leveraging all retrieved documents and the final evolved graph. Experiments on four multi-hop question answering benchmarks demonstrate the effectiveness of GraphAnchor, and reveal that GraphAnchor modulates the LLM's attention to more effectively associate key information distributed in retrieved documents. All code and data are available at https://github.com/NEUIR/GraphAnchor.
Structured Knowledge Representation through Contextual Pages for Retrieval-Augmented Generation
Jan 14, 2026Retrieval-Augmented Generation (RAG) enhances Large Language Models (LLMs) by incorporating external knowledge. Recently, some works have incorporated iterative knowledge accumulation processes into RAG models to progressively accumulate and refine query-related knowledge, thereby constructing more comprehensive knowledge representations. However, these iterative processes often lack a coherent organizational structure, which limits the construction of more comprehensive and cohesive knowledge representations. To address this, we propose PAGER, a page-driven autonomous knowledge representation framework for RAG. PAGER first prompts an LLM to construct a structured cognitive outline for a given question, which consists of multiple slots representing a distinct knowledge aspect. Then, PAGER iteratively retrieves and refines relevant documents to populate each slot, ultimately constructing a coherent page that serves as contextual input for guiding answer generation. Experiments on multiple knowledge-intensive benchmarks and backbone models show that PAGER consistently outperforms all RAG baselines. Further analyses demonstrate that PAGER constructs higher-quality and information-dense knowledge representations, better mitigates knowledge conflicts, and enables LLMs to leverage external knowledge more effectively. All code is available at https://github.com/OpenBMB/PAGER.
Judge as A Judge: Improving the Evaluation of Retrieval-Augmented Generation through the Judge-Consistency of Large Language Models
Feb 26, 2025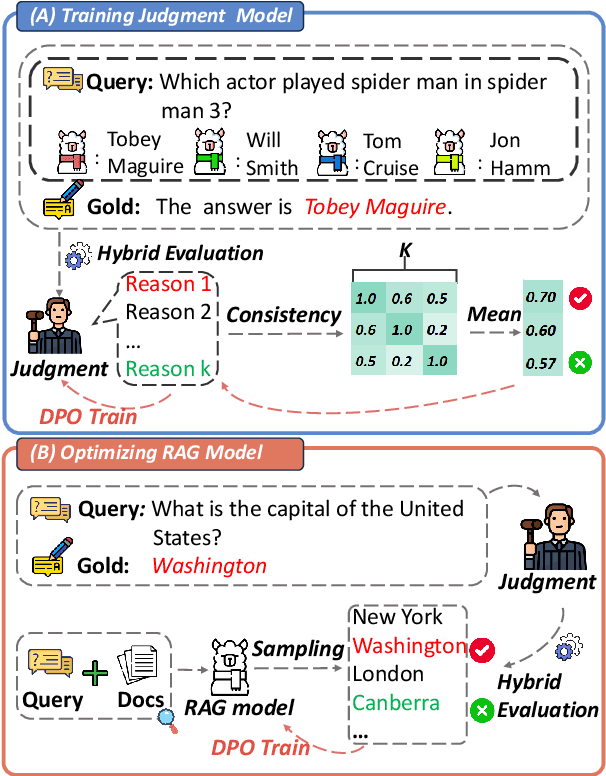
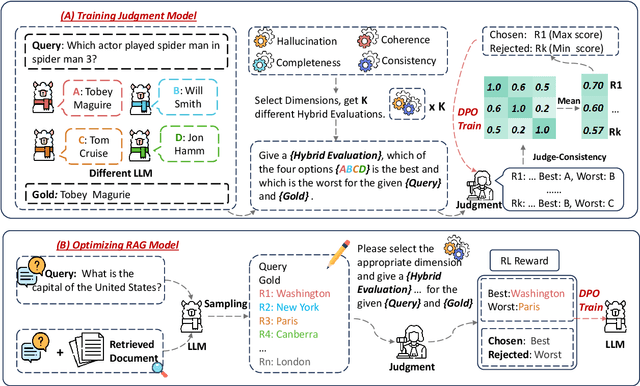
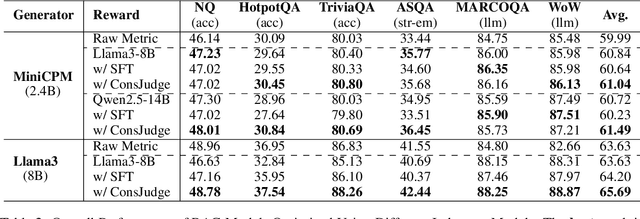
Retrieval-Augmented Generation (RAG) has proven its effectiveness in alleviating hallucinations for Large Language Models (LLMs). However, existing automated evaluation metrics cannot fairly evaluate the outputs generated by RAG models during training and evaluation. LLM-based judgment models provide the potential to produce high-quality judgments, but they are highly sensitive to evaluation prompts, leading to inconsistencies when judging the output of RAG models. This paper introduces the Judge-Consistency (ConsJudge) method, which aims to enhance LLMs to generate more accurate evaluations for RAG models. Specifically, ConsJudge prompts LLMs to generate different judgments based on various combinations of judgment dimensions, utilize the judge-consistency to evaluate these judgments and select the accepted and rejected judgments for DPO training. Our experiments show that ConsJudge can effectively provide more accurate judgments for optimizing RAG models across various RAG models and datasets. Further analysis reveals that judgments generated by ConsJudge have a high agreement with the superior LLM. All codes are available at https://github.com/OpenBMB/ConsJudge.
RankCoT: Refining Knowledge for Retrieval-Augmented Generation through Ranking Chain-of-Thoughts
Feb 25, 2025Retrieval-Augmented Generation (RAG) enhances the performance of Large Language Models (LLMs) by incorporating external knowledge. However, LLMs still encounter challenges in effectively utilizing the knowledge from retrieved documents, often being misled by irrelevant or noisy information. To address this issue, we introduce RankCoT, a knowledge refinement method that incorporates reranking signals in generating CoT-based summarization for knowledge refinement based on given query and all retrieval documents. During training, RankCoT prompts the LLM to generate Chain-of-Thought (CoT) candidates based on the query and individual documents. It then fine-tunes the LLM to directly reproduce the best CoT from these candidate outputs based on all retrieved documents, which requires LLM to filter out irrelevant documents during generating CoT-style summarization. Additionally, RankCoT incorporates a self-reflection mechanism that further refines the CoT outputs, resulting in higher-quality training data. Our experiments demonstrate the effectiveness of RankCoT, showing its superior performance over other knowledge refinement models. Further analysis reveals that RankCoT can provide shorter but effective refinement results, enabling the generator to produce more accurate answers. All code and data are available at https://github.com/NEUIR/RankCoT.
KBAlign: Efficient Self Adaptation on Specific Knowledge Bases
Nov 25, 2024
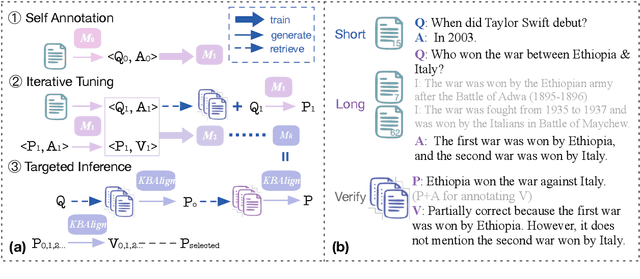

Humans can utilize techniques to quickly acquire knowledge from specific materials in advance, such as creating self-assessment questions, enabling us to achieving related tasks more efficiently. In contrast, large language models (LLMs) usually relies on retrieval-augmented generation to exploit knowledge materials in an instant manner, or requires external signals such as human preference data and stronger LLM annotations to conduct knowledge adaptation. To unleash the self-learning potential of LLMs, we propose KBAlign, an approach designed for efficient adaptation to downstream tasks involving knowledge bases. Our method utilizes iterative training with self-annotated data such as Q&A pairs and revision suggestions, enabling the model to grasp the knowledge content efficiently. Experimental results on multiple datasets demonstrate the effectiveness of our approach, significantly boosting model performance in downstream tasks that require specific knowledge at a low cost. Notably, our approach achieves over 90% of the performance improvement that can be obtained by using GPT-4-turbo annotation, while relying entirely on self-supervision. We release our experimental data, models, and process analyses to the community for further exploration (https://github.com/thunlp/KBAlign).
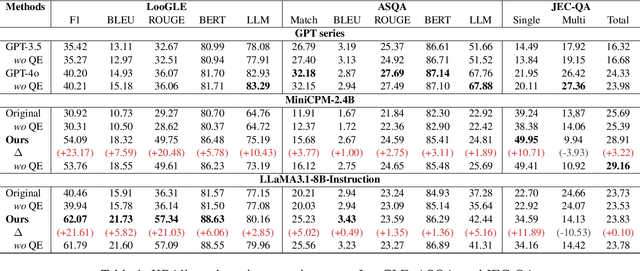
RAG-DDR: Optimizing Retrieval-Augmented Generation Using Differentiable Data Rewards
Oct 17, 2024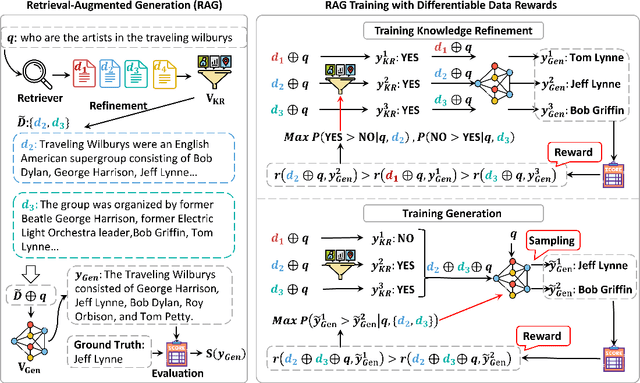
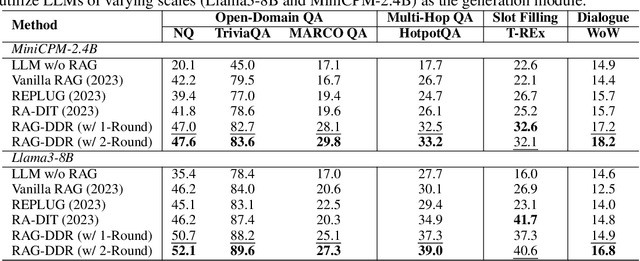
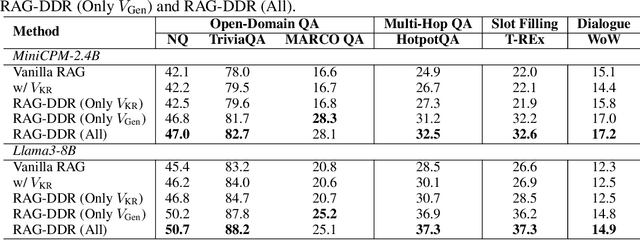
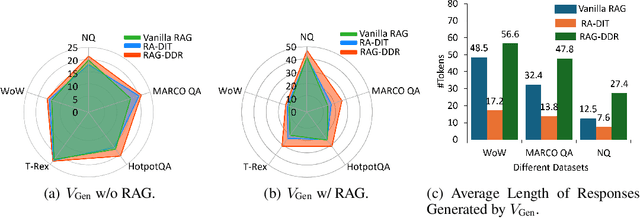
Retrieval-Augmented Generation (RAG) has proven its effectiveness in mitigating hallucinations in Large Language Models (LLMs) by retrieving knowledge from external resources. To adapt LLMs for RAG pipelines, current approaches use instruction tuning to optimize LLMs, improving their ability to utilize retrieved knowledge. This supervised fine-tuning (SFT) approach focuses on equipping LLMs to handle diverse RAG tasks using different instructions. However, it trains RAG modules to overfit training signals and overlooks the varying data preferences among agents within the RAG system. In this paper, we propose a Differentiable Data Rewards (DDR) method, which end-to-end trains RAG systems by aligning data preferences between different RAG modules. DDR works by collecting the rewards to optimize each agent with a rollout method. This method prompts agents to sample some potential responses as perturbations, evaluates the impact of these perturbations on the whole RAG system, and subsequently optimizes the agent to produce outputs that improve the performance of the RAG system. Our experiments on various knowledge-intensive tasks demonstrate that DDR significantly outperforms the SFT method, particularly for LLMs with smaller-scale parameters that depend more on the retrieved knowledge. Additionally, DDR exhibits a stronger capability to align the data preference between RAG modules. The DDR method makes generation module more effective in extracting key information from documents and mitigating conflicts between parametric memory and external knowledge. All codes are available at https://github.com/OpenMatch/RAG-DDR.
PersLLM: A Personified Training Approach for Large Language Models
Jul 18, 2024



Large language models exhibit aspects of human-level intelligence that catalyze their application as human-like agents in domains such as social simulations, human-machine interactions, and collaborative multi-agent systems. However, the absence of distinct personalities, such as displaying ingratiating behaviors, inconsistent opinions, and uniform response patterns, diminish LLMs utility in practical applications. Addressing this, the development of personality traits in LLMs emerges as a crucial area of research to unlock their latent potential. Existing methods to personify LLMs generally involve strategies like employing stylized training data for instruction tuning or using prompt engineering to simulate different personalities. These methods only capture superficial linguistic styles instead of the core of personalities and are therefore not stable. In this study, we propose PersLLM, integrating psychology-grounded principles of personality: social practice, consistency, and dynamic development, into a comprehensive training methodology. We incorporate personality traits directly into the model parameters, enhancing the model's resistance to induction, promoting consistency, and supporting the dynamic evolution of personality. Single-agent evaluation validates our method's superiority, as it produces responses more aligned with reference personalities compared to other approaches. Case studies for multi-agent communication highlight its benefits in enhancing opinion consistency within individual agents and fostering collaborative creativity among multiple agents in dialogue contexts, potentially benefiting human simulation and multi-agent cooperation. Additionally, human-agent interaction evaluations indicate that our personified models significantly enhance interactive experiences, underscoring the practical implications of our research.
ConPET: Continual Parameter-Efficient Tuning for Large Language Models
Sep 26, 2023Continual learning necessitates the continual adaptation of models to newly emerging tasks while minimizing the catastrophic forgetting of old ones. This is extremely challenging for large language models (LLMs) with vanilla full-parameter tuning due to high computation costs, memory consumption, and forgetting issue. Inspired by the success of parameter-efficient tuning (PET), we propose Continual Parameter-Efficient Tuning (ConPET), a generalizable paradigm for continual task adaptation of LLMs with task-number-independent training complexity. ConPET includes two versions with different application scenarios. First, Static ConPET can adapt former continual learning methods originally designed for relatively smaller models to LLMs through PET and a dynamic replay strategy, which largely reduces the tuning costs and alleviates the over-fitting and forgetting issue. Furthermore, to maintain scalability, Dynamic ConPET adopts separate PET modules for different tasks and a PET module selector for dynamic optimal selection. In our extensive experiments, the adaptation of Static ConPET helps multiple former methods reduce the scale of tunable parameters by over 3,000 times and surpass the PET-only baseline by at least 5 points on five smaller benchmarks, while Dynamic ConPET gains its advantage on the largest dataset. The codes and datasets are available at https://github.com/Raincleared-Song/ConPET.
Interactive Molecular Discovery with Natural Language
Jun 21, 2023Natural language is expected to be a key medium for various human-machine interactions in the era of large language models. When it comes to the biochemistry field, a series of tasks around molecules (e.g., property prediction, molecule mining, etc.) are of great significance while having a high technical threshold. Bridging the molecule expressions in natural language and chemical language can not only hugely improve the interpretability and reduce the operation difficulty of these tasks, but also fuse the chemical knowledge scattered in complementary materials for a deeper comprehension of molecules. Based on these benefits, we propose the conversational molecular design, a novel task adopting natural language for describing and editing target molecules. To better accomplish this task, we design ChatMol, a knowledgeable and versatile generative pre-trained model, enhanced by injecting experimental property information, molecular spatial knowledge, and the associations between natural and chemical languages into it. Several typical solutions including large language models (e.g., ChatGPT) are evaluated, proving the challenge of conversational molecular design and the effectiveness of our knowledge enhancement method. Case observations and analysis are conducted to provide directions for further exploration of natural-language interaction in molecular discovery.
Tool Learning with Foundation Models
Apr 17, 2023Humans possess an extraordinary ability to create and utilize tools, allowing them to overcome physical limitations and explore new frontiers. With the advent of foundation models, AI systems have the potential to be equally adept in tool use as humans. This paradigm, i.e., tool learning with foundation models, combines the strengths of specialized tools and foundation models to achieve enhanced accuracy, efficiency, and automation in problem-solving. Despite its immense potential, there is still a lack of a comprehensive understanding of key challenges, opportunities, and future endeavors in this field. To this end, we present a systematic investigation of tool learning in this paper. We first introduce the background of tool learning, including its cognitive origins, the paradigm shift of foundation models, and the complementary roles of tools and models. Then we recapitulate existing tool learning research into tool-augmented and tool-oriented learning. We formulate a general tool learning framework: starting from understanding the user instruction, models should learn to decompose a complex task into several subtasks, dynamically adjust their plan through reasoning, and effectively conquer each sub-task by selecting appropriate tools. We also discuss how to train models for improved tool-use capabilities and facilitate the generalization in tool learning. Considering the lack of a systematic tool learning evaluation in prior works, we experiment with 17 representative tools and show the potential of current foundation models in skillfully utilizing tools. Finally, we discuss several open problems that require further investigation for tool learning. Overall, we hope this paper could inspire future research in integrating tools with foundation models.