 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Roadmap for Big Model
Apr 02, 2022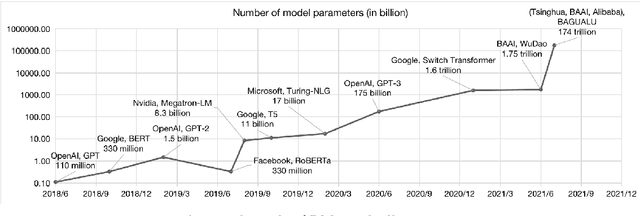
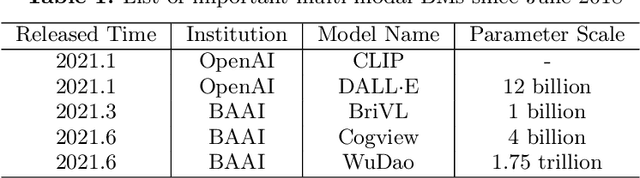
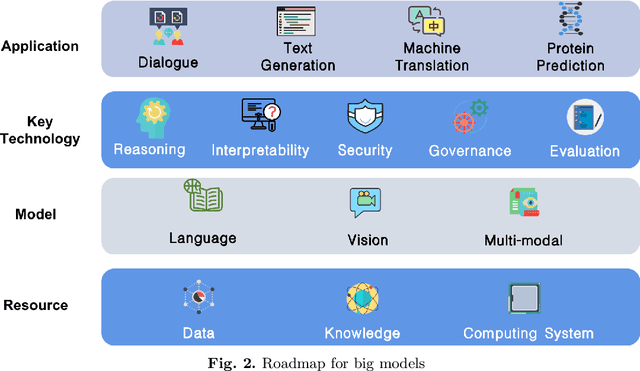
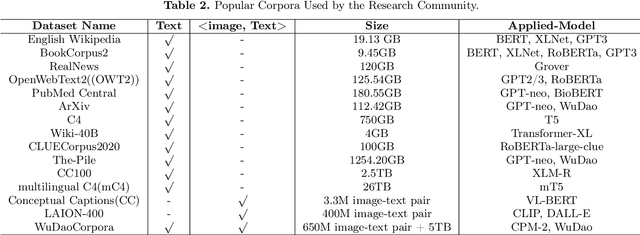
With the rapid development of deep learning, training Big Models (BMs) for multiple downstream tasks becomes a popular paradigm. Researchers have achieved various outcomes in the construction of BMs and the BM application in many fields. At present, there is a lack of research work that sorts out the overall progress of BMs and guides the follow-up research. In this paper, we cover not only the BM technologies themselves but also the prerequisites for BM training and applications with BMs, dividing the BM review into four parts: Resource, Models, Key Technologies and Application. We introduce 16 specific BM-related topics in those four parts, they are Data, Knowledge, Computing System, Parallel Training System, Language Model, Vision Model, Multi-modal Model, Theory&Interpretability, Commonsense Reasoning, Reliability&Security, Governance, Evaluation, Machine Translation, Text Generation, Dialogue and Protein Research. In each topic, we summarize clearly the current studies and propose some future research directions. At the end of this paper, we conclude the further development of BMs in a more general view.
WuDaoMM: A large-scale Multi-Modal Dataset for Pre-training models
Mar 30, 2022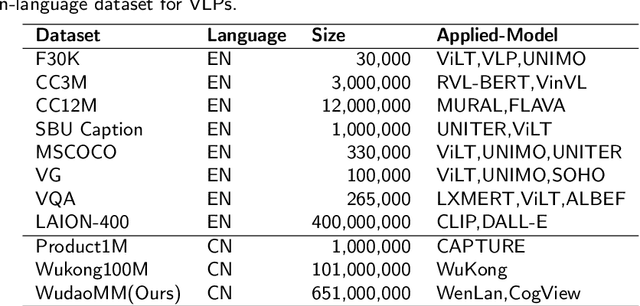


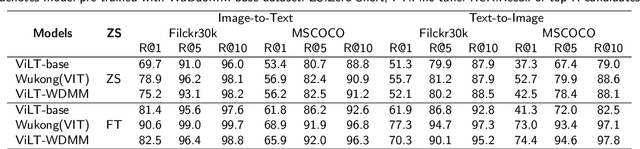
Compared with the domain-specific model, the vision-language pre-training models (VLPMs) have shown superior performance on downstream tasks with fast fine-tuning process. For example, ERNIE-ViL, Oscar and UNIMO trained VLPMs with a uniform transformers stack architecture and large amounts of image-text paired data, achieving remarkable results on downstream tasks such as image-text reference(IR and TR), vision question answering (VQA) and image captioning (IC) etc. During the training phase, VLPMs are always fed with a combination of multiple public datasets to meet the demand of large-scare training data. However, due to the unevenness of data distribution including size, task type and quality, using the mixture of multiple datasets for model training can be problematic. In this work, we introduce a large-scale multi-modal corpora named WuDaoMM, totally containing more than 650M image-text pairs. Specifically, about 600 million pairs of data are collected from multiple webpages in which image and caption present weak correlation, and the other 50 million strong-related image-text pairs are collected from some high-quality graphic websites. We also release a base version of WuDaoMM with 5 million strong-correlated image-text pairs, which is sufficient to support the common cross-modal model pre-training. Besides, we trained both an understanding and a generation vision-language (VL) model to test the dataset effectiveness. The results show that WuDaoMM can be applied as an efficient dataset for VLPMs, especially for the model in text-to-image generation task. The data is released at https://data.wudaoai.cn
Calculating Question Similarity is Enough:A New Method for KBQA Tasks
Nov 15, 2021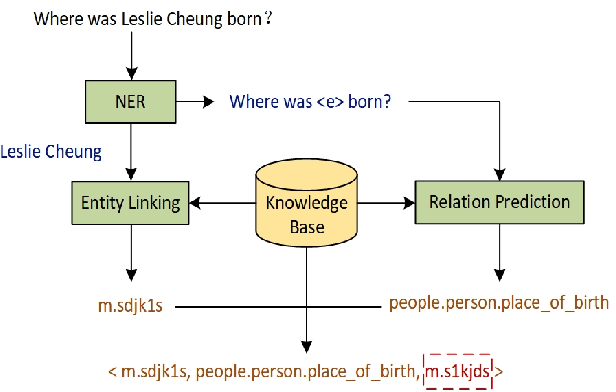
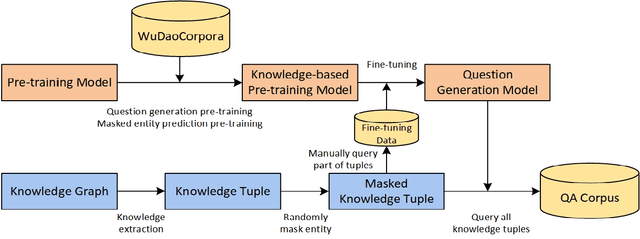

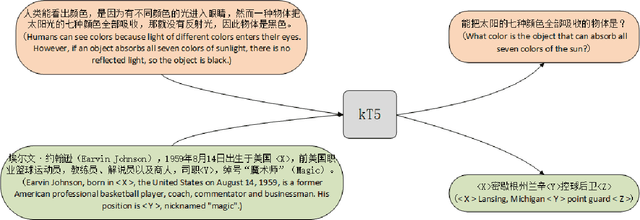
Knowledge Base Question Answering (KBQA) aims to answer natural language questions with the help of an external knowledge base. The core idea is to find the link between the internal knowledge behind questions and known triples of the knowledge base. The KBQA task pipeline contains several steps, including entity recognition, relationship extraction, and entity linking. This kind of pipeline method means that errors in any procedure will inevitably propagate to the final prediction. In order to solve the above problem, this paper proposes a Corpus Generation - Retrieve Method (CGRM) with Pre-training Language Model (PLM) and Knowledge Graph (KG). Firstly, based on the mT5 model, we designed two new pre-training tasks: knowledge masked language modeling and question generation based on the paragraph to obtain the knowledge enhanced T5 (kT5) model. Secondly, after preprocessing triples of knowledge graph with a series of heuristic rules, the kT5 model generates natural language QA pairs based on processed triples. Finally, we directly solve the QA by retrieving the synthetic dataset. We test our method on NLPCC-ICCPOL 2016 KBQA dataset, and the results show that our framework improves the performance of KBQA and the out straight-forward method is competitive with the state-of-the-art.
Turing Award elites revisited: patterns of productivity, collaboration, authorship and impact
Jun 22, 2021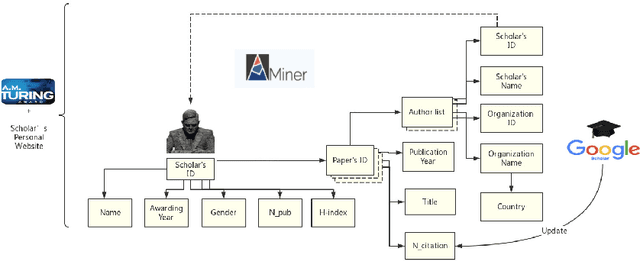

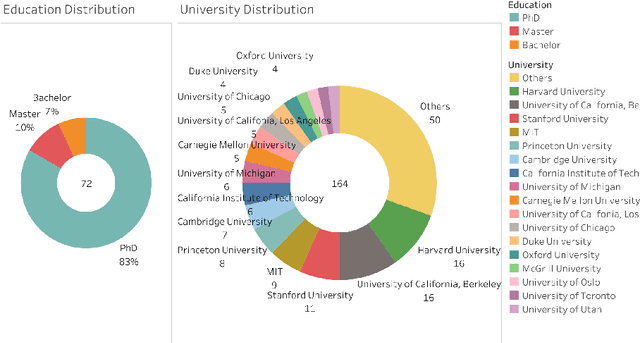

The Turing Award is recognized as the most influential and prestigious award in the field of computer science(CS). With the rise of the science of science (SciSci), a large amount of bibliographic data has been analyzed in an attempt to understand the hidden mechanism of scientific evolution. These include the analysis of the Nobel Prize, including physics, chemistry, medicine, etc. In this article, we extract and analyze the data of 72 Turing Award laureates from the complete bibliographic data, fill the gap in the lack of Turing Award analysis, and discover the development characteristics of computer science as an independent discipline. First, we show most Turing Award laureates have long-term and high-quality educational backgrounds, and more than 61% of them have a degree in mathematics, which indicates that mathematics has played a significant role in the development of computer science. Secondly, the data shows that not all scholars have high productivity and high h-index; that is, the number of publications and h-index is not the leading indicator for evaluating the Turing Award. Third, the average age of awardees has increased from 40 to around 70 in recent years. This may be because new breakthroughs take longer, and some new technologies need time to prove their influence. Besides, we have also found that in the past ten years, international collaboration has experienced explosive growth, showing a new paradigm in the form of collaboration. It is also worth noting that in recent years, the emergence of female winners has also been eye-catching. Finally, by analyzing the personal publication records, we find that many people are more likely to publish high-impact articles during their high-yield periods.
Attention: to Better Stand on the Shoulders of Giants
May 27, 2020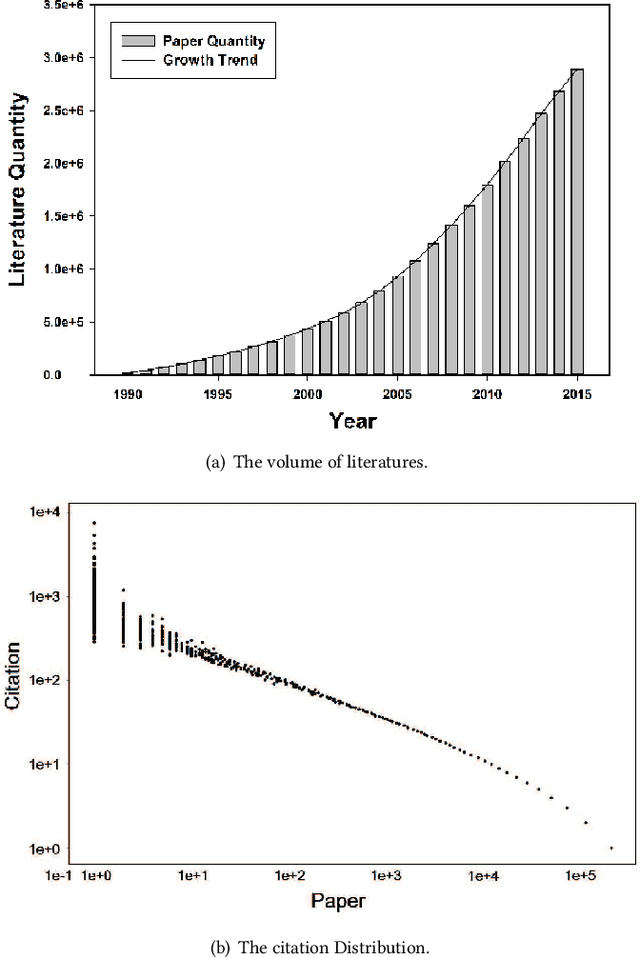


Science of science (SciSci) is an emerging discipline wherein science is used to study the structure and evolution of science itself using large data sets. The increasing availability of digital data on scholarly outcomes offers unprecedented opportunities to explore SciSci. In the progress of science, the previously discovered knowledge principally inspires new scientific ideas, and citation is a reasonably good reflection of this cumulative nature of scientific research. The researches that choose potentially influential references will have a lead over the emerging publications. Although the peer review process is the mainly reliable way of predicting a paper's future impact, the ability to foresee the lasting impact based on citation records is increasingly essential in the scientific impact analysis in the era of big data. This paper develops an attention mechanism for the long-term scientific impact prediction and validates the method based on a real large-scale citation data set. The results break conventional thinking. Instead of accurately simulating the original power-law distribution, emphasizing the limited attention can better stand on the shoulders of giants.
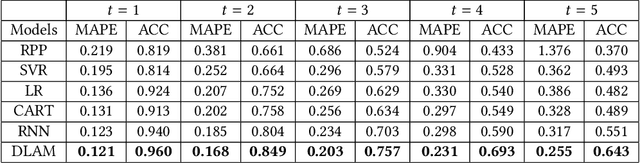
Modeling and Predicting Popularity Dynamics via Deep Learning Attention Mechanism
Nov 06, 2018


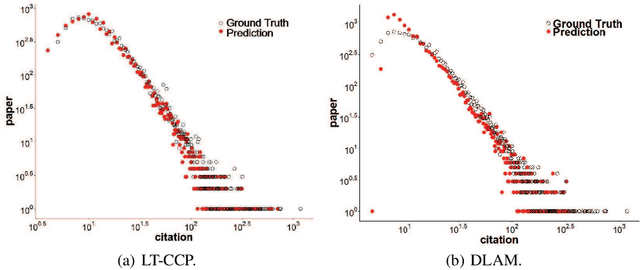
An ability to predict the popularity dynamics of individual items within a complex evolving system has important implications in a wide range of domains. Here we propose a deep learning attention mechanism to model the process through which individual items gain their popularity. We analyze the interpretability of the model with the four key phenomena confirmed independently in the previous studies of long-term popularity dynamics quantification, including the intrinsic quality, the aging effect, the recency effect and the Matthew effect. We analyze the effectiveness of introducing attention model in popularity dynamics prediction. Extensive experiments on a real-large citation data set demonstrate that the designed deep learning attention mechanism possesses remarkable power at predicting the long-term popularity dynamics. It consistently outperforms the existing methods, and achieves a significant performance improvement.
Expert Finding in Community Question Answering: A Review
Apr 21, 2018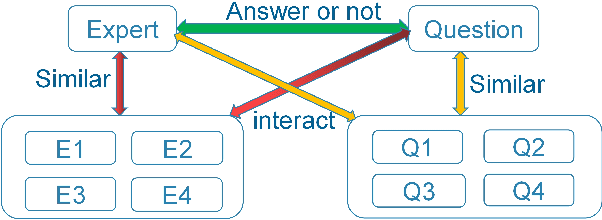



The rapid development recently of Community Question Answering (CQA) satisfies users quest for professional and personal knowledge about anything. In CQA, one central issue is to find users with expertise and willingness to answer the given questions. Expert finding in CQA often exhibits very different challenges compared to traditional methods. Sparse data and new features violate fundamental assumptions of traditional recommendation systems. This paper focuses on reviewing and categorizing the current progress on expert finding in CQA. We classify all the existing solutions into four different categories: matrix factorization based models (MF-based models), gradient boosting tree based models (GBT-based models), deep learning based models (DL-based models) and ranking based models (R-based models). We find that MF-based models outperform other categories of models in the field of expert finding in CQA. Moreover, we use innovative diagrams to clarify several important concepts of ensemble learning, and find that ensemble models with several specific single models can further boosting the performance. Further, we compare the performance of different models on different types of matching tasks, including text vs. text, graph vs. text, audio vs. text and video vs. text. The results can help the model selection of expert finding in practice. Finally, we explore some potential future issues in expert finding research in CQA.